基于视觉-语言层级对齐关系的人体全身姿态关键点的预测方法
- 国知局
- 2024-07-31 23:00:52
本发明涉及计算机视觉,特别涉及一种基于视觉-语言层级对齐关系的人体全身姿态关键点的预测方法和系统、电子设备以及存储介质。
背景技术:
1、全身姿态关键点预测技术已经广泛应用于人机交互、电影行业、动作识别、虚拟现实、增强现实等领域。不同于仅仅针对身体的某些关键点位置的预测任务,对于全身姿态的估计至少有以下几个问题需要解决:一是身体不同部位的尺度差异:模型在预测过程中对于极大尺度与极小尺度的目标均会有一定程度的性能下降(例如在现实生活中,对于远处的物体本发明往往难以分辨清楚);二是由尺度差异所延伸出来的小尺度语义模糊问题:在预测任务中,针对小尺度区域,例如手部、脸部等,由于尺度较小,因此能从中得到的信息量较少,但需要标记的关键点却很多,这使得技人员更加难以区分具体的细节,如对于手部,哪个是食指或哪个是中指;三是人体复杂的层次组织:需要细粒度关键点的精确定位。
2、虽然现有技术中针对全身姿态的估计已经有了较大的进步,例如zoomnas技术方案通过将裁剪出的手、人脸关键点特征进行高分辨率缩放,以获取更为详细的人脸、手信息。这一策略成功地减轻了尺度问题和小尺度语义模糊问题,但也存在一些潜在的负面影响。具体而言,裁剪操作导致丢失了人体的上下文信息,而缺乏这些上下文信息可能会破坏人体躯干和四肢之间的潜在关联。此外,超分辨率操作可能引入额外的偏差,导致模型从噪声数据中学到次优的结果。因此,采用zoomnas的技术方案存在以下技术问题:一是将图像进行裁剪,会导致丢失了人体的上下文信息,进而破坏人体躯干和四肢之间的潜在关联;二是超分辨率操作可能引入额外的偏差,导致模型从噪声数据中学到次优的结果。
技术实现思路
1、鉴于上述问题,本发明提供了一种基于视觉-语言层级对齐关系的人体全身姿态关键点的预测方法和系统、电子设备以及存储介质,以期至少能够解决上述问题之一。
2、根据本发明的第一个方面,提供了一种基于视觉-语言层级对齐关系的人体全身姿态关键点的预测方法,包括:
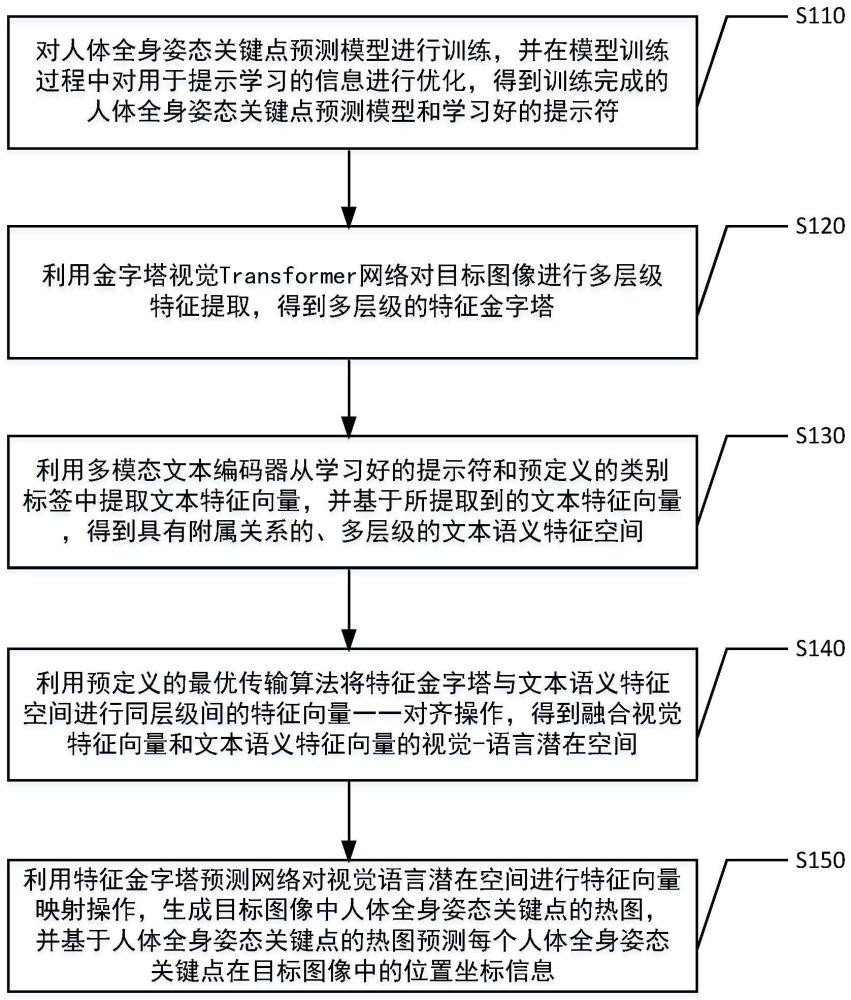
3、对人体全身姿态关键点预测模型进行训练,并在模型训练过程中对用于提示学习的信息进行优化,得到训练完成的人体全身姿态关键点预测模型和学习好的提示符,其中,训练完成的人体全身姿态关键点预测模型包括金字塔视觉transformer网络、多模态文本编码器以及特征金字塔预测网络,学习好的提示符是用于表示人体全身姿态关键点的向量;
4、利用金字塔视觉transformer网络对目标图像进行多层级特征提取,得到多层级的特征金字塔,其中,多层级的特征金字塔中不同层级的图像特征具有不同的尺寸、不同的分辨率和不同的图像粒度;
5、利用多模态文本编码器从学习好的提示符和预定义的类别标签中提取文本特征向量,并基于所提取到的文本特征向量,得到具有附属关系的、多层级的文本语义特征空间,其中,文本语义特征空间与特征金字塔具有相同数量的层级;
6、利用预定义的最优传输算法将特征金字塔与文本语义特征空间进行同层级间的特征向量一一对齐操作,得到融合视觉特征向量和文本语义特征向量的视觉-语言潜在空间;
7、利用特征金字塔预测网络对视觉-语言潜在空间进行特征向量映射操作,生成目标图像中人体全身姿态关键点的热图,并基于人体全身姿态关键点的热图预测每个人体全身姿态关键点在目标图像中的位置坐标信息。
8、根据本发明的实施例,上述对人体全身姿态关键点预测模型进行训练,并在模型训练过程中对用于提示学习的信息进行优化,得到训练完成的人体全身姿态关键点预测模型和学习好的提示符包括:
9、基于视觉语言模型构建人体全身姿态关键点预测模型,并利用金字塔视觉transformer网络对图像样本进行多层级特征提取,得到特征样本金字塔;
10、根据多层级的特征样本金字塔的层级属性信息以及类别标签样本,对用于提示学习的信息进行分层初始化,得到初始的提示符;
11、利用多模态文本编码器对初始的提示符进行文本语义特征提取操作以及文本附属关系注入操作,得到文本语义特征样本空间,并在提取操作和注入操作过程中,计算语言损失值;
12、利用特征样本金字塔和文本语义特征样本空间之间的余弦相似度定义成本函数,并利用成本函数构建熵约束的拉格朗日乘子的优化目标;
13、基于熵约束的拉格朗日乘子的优化目标,利用最优传输算法通过最小化总距离操作将特征样本金字塔和文本语义特征样本空间进行同层级间的特征向量一一对齐操作,得到视觉-语言潜在空间样本;
14、利用特征金字塔预测网络对视觉-语言潜在空间样本进行特征向量映射操作,生成目标图像中人体全身姿态关键点的热图样本,并在热图样本生成过程中,计算热图损失值;
15、根据预定义的权重,利用语言损失值和热图损失值计算训练总损失值,并利用训练总损失值对人体全身姿态关键点预测模型进行参数更新以及对用于提示学习的信息进行优化,迭代进行多轮次训练直到满足预设训练条件,得到训练完成的人体全身姿态关键点预测模型和学习好的提示符。
16、根据本发明的实施例,上述利用金字塔视觉transformer网络对图像样本进行多层级特征提取,得到特征样本金字塔包括:
17、利用金字塔视觉transformer网络的嵌入层对图像样本进行切割,将切割所得到的图像块排成序列,并通过线性映射操作将序列变换为二维矩阵;
18、将二维矩阵以及序列的位置信息输入到金字塔视觉transformer网络中,利用金字塔视觉transformer网络的transformer编码器从图像样本提取到多层级的特征样本金字塔。
19、根据本发明的实施例,上述利用多模态文本编码器对初始的提示符进行文本语义特征提取操作以及文本附属关系注入操作,得到文本语义特征样本空间,并在提取操作和注入操作过程中,计算语言损失值包括:
20、利用多模态文本编码器对初始的提示符进行文本语义特征提取操作,得到多层级的文本语义特征样本;
21、基于文本关系的先验知识,利用多模态文本编码器通过文本语义特征样本相邻层级之间的特征向量映射实现文本附属关系注入,得到具有附属关系的、多层级的文本语义特征样本空间;
22、利用基于l1范式的语言损失函数在文本语义特征样本提取操作和文本附属关系注入操作过程中计算语言损失值。
23、根据本发明的实施例,上述基于l1范式的语言损失函数如下式所示:
24、
25、其中,etext(*)表示所示多模态编码器,ti表示第i层的提示符,表示第i+1层的提示符。
26、根据本发明的实施例,上述利用特征样本金字塔和文本语义特征样本空间之间的余弦相似度定义成本函数,并利用成本函数构建熵约束的拉格朗日乘子的优化目标包括:
27、利用特征样本金字塔和文本语义特征样本空间之间的余弦相似度定义成本函数;
28、基于最优传输问题中将不同模态的特征向量映射到共同向量空间的方式,利用成本函数、预定义的传输计划矩阵、预定义的熵约束得到熵约束的拉格朗日乘子的优化目标。
29、根据本发明的实施例,上述熵约束的拉格朗日乘子的优化目标由下式表示:
30、
31、其中,c表示成本函数,t表示预定义的传输计划矩阵,λh(t)表示预定义的熵约束,u表示特征样本金字塔中的向量分量,v表示文本语义特征样本空间中的向量分量。
32、根据本发明的第二个方面,提供了一种基于视觉-语言层级对齐关系的人体全身姿态关键点的预测系统,包括:
33、模型训练模块,用于对人体全身姿态关键点预测模型进行训练,并在模型训练过程中对用于提示学习的信息进行优化,得到训练完成的人体全身姿态关键点预测模型和学习好的提示符,其中,训练完成的人体全身姿态关键点预测模型包括金字塔视觉transformer网络、多模态文本编码器以及特征金字塔预测网络,学习好的提示符是用于表示人体全身姿态关键点的向量;
34、图像特征提取模块,用于利用金字塔视觉transformer网络对目标图像进行多层级特征提取,得到多层级的特征金字塔,其中,多层级的特征金字塔中不同层级的图像特征具有不同的尺寸和分辨率;
35、文本语义特征空间获取模块,用于利用多模态文本编码器从学习好的提示符和预定义的类别标签中提取文本特征向量,并基于所提取到的文本特征向量,得到具有附属关系的、多层级的文本语义特征空间,其中,文本语义特征空间与特征金字塔具有相同数量的层级;
36、视觉-语言潜在空间获取模块,用于利用预定义的最优传输算法将特征金字塔与文本语义特征空间进行同层级间的特征向量一一对齐操作,得到融合视觉特征向量和文本语义特征向量的视觉-语言潜在空间;
37、关键点预测模块,用于利用特征金字塔预测网络对视觉-语言潜在空间进行特征向量映射操作,生成目标图像中人体全身姿态关键点的热图,并基于人体全身姿态关键点的热图预测每个人体全身姿态关键点在目标图像中的位置坐标信息。
38、根据本发明的第三个方面,提供了一种电子设备,包括:
39、一个或多个处理器;
40、存储装置,用于存储一个或多个程序,
41、其中,当一个或多个程序被一个或多个处理器执行时,使得一个或多个处理器执行基于视觉-语言层级对齐关系的人体全身姿态关键点的预测方法。
42、根据本发明的第四个方面,提供了一种计算机可读存储介质,其上存储有可执行指令,该指令被处理器执行时使处理器执行基于视觉-语言层级对齐关系的人体全身姿态关键点的预测方法。
43、本发明提供的上述基于视觉-语言层级对齐关系的人体全身姿态关键点的预测方法,能从单个图像中预测出人体各个部位的关键点位置,解决了现有技术中全身姿态的估计的难点问题;本发明提供的上述基于视觉-语言层级对齐关系的人体全身姿态关键点的预测方法利用文本信息优良的代数性质,构建不同级别文本特征的从属关系,并以此构建文本语言空间,通过文本附属关系对齐的操作,将文本关系的先验知识以代数和的形式融入语言特征的分布中,进而构建了逐层对齐的层级分明,性质优良的视觉-文本隐空间,使得对于全身关键点尤其对于小尺度部位的关键点预测更加准确。
本文地址:https://www.jishuxx.com/zhuanli/20240730/195663.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表