模型训练方法、视频定位方法、系统、设备、产品及介质与流程
- 国知局
- 2024-07-31 23:03:13
本发明涉及视频数据处理领域,特别涉及一种模型训练方法、视频定位方法、系统、设备、产品及介质。
背景技术:
1、具体来说,在当前的avel(audio-visual event localization,音频-视觉事件定位)方法中,当涉及到定位音频事件时,通常将视觉(visual)模态的信息视为一种噪声或干扰。在实际操作中,会运用各种技术手段来排除这种视觉模态信息的干扰,以确保它尽可能不影响音频事件的准确获取。
2、然而,这种设定存在一个显著的局限性,那就是它并没有充分利用音频模态与视觉模态之间潜在的、丰富的内在关联关系。将视觉模态视为噪声并排除,忽略了视觉信息可能对事件定位和识别的贡献,可能导致信息的损失,从而影响整体的事件定位准确性和可靠性。
技术实现思路
1、本发明的目的是提供一种模型训练方法、视频定位方法、系统、设备、产品及介质,通过构建视觉特征和音频特征对应的知识图结构,使用知识图结构优化第一神经网络模型,并未将视觉信息视为噪声,能够捕捉和利用音频与视频之间的复杂关联关系,能够更好地整合和利用多模态数据,提高得到的目标神经网络模型的定位精度和可靠性。
2、为解决上述技术问题,本发明提供了一种模型训练方法,包括:
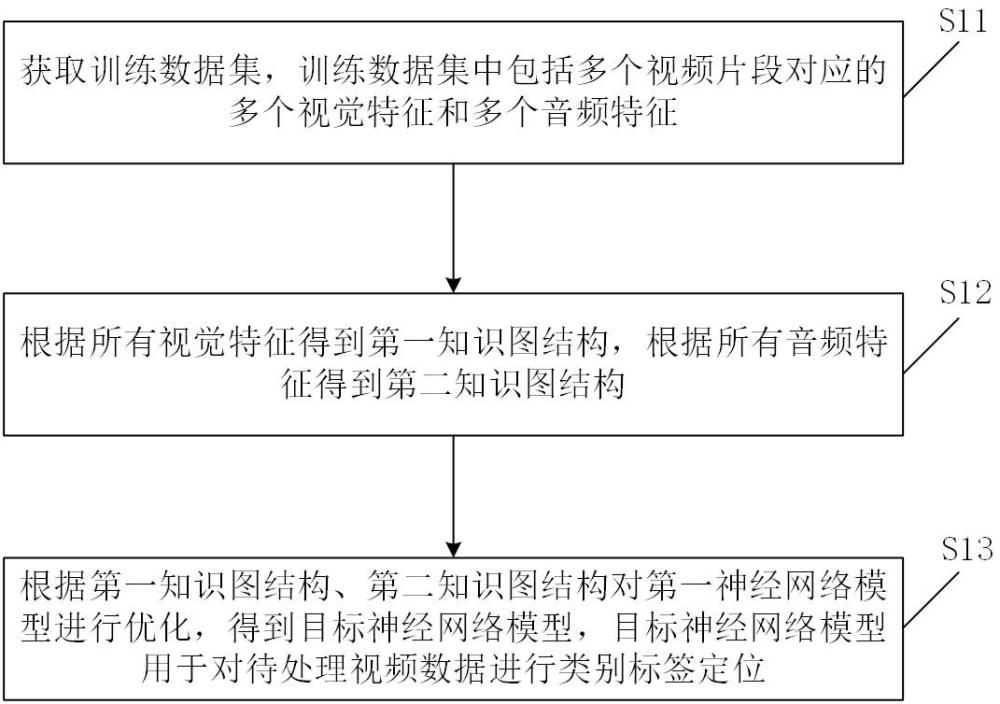
3、获取训练数据集,所述训练数据集中包括多个视频片段对应的多个视觉特征和多个音频特征;
4、根据所有所述视觉特征得到第一知识图结构,根据所有所述音频特征得到第二知识图结构;
5、根据所述第一知识图结构、所述第二知识图结构对第一神经网络模型进行优化,得到目标神经网络模型,所述目标神经网络模型用于对待处理视频数据进行类别标签定位。
6、其中,根据所述第一知识图结构、所述第二知识图结构对第一神经网络模型进行优化,得到目标神经网络模型,包括:
7、将每个所述视觉特征和所述第一知识图结构输入至第二神经网络模型,得到每个所述视觉特征对应的视觉增强特征;
8、将每个所述音频特征和所述第二知识图结构输入至所述第二神经网络模型,得到每个所述音频特征对应的音频增强特征;
9、根据所述视觉增强特征和所述音频增强特征对所述第一神经网络模型进行优化,得到所述目标神经网络模型。
10、其中,将每个所述视觉特征和所述第一知识图结构输入至第二神经网络模型,得到每个所述视觉特征对应的视觉增强特征,包括:
11、将每个所述视觉特征和所述第一知识图结构输入至所述第二神经网络模型;
12、根据所述第一知识图结构获取每个所述视觉特征的邻居节点的第一邻居特征,并根据每个所述视觉特征和对应的第一邻居特征通过聚合,得到每个所述视觉特征对应的视觉增强特征;
13、将每个所述音频特征和所述第二知识图结构输入至所述第二神经网络模型,得到每个所述音频特征对应的音频增强特征,包括:
14、将每个所述音频特征和所述第二知识图结构输入至所述第二神经网络模型;
15、根据所述第二知识图结构获取每个所述音频特征的邻居节点的第二邻居特征,并根据每个所述音频特征和对应的第二邻居特征通过聚合,得到每个所述音频特征对应的音频增强特征。
16、其中,根据所述视觉增强特征和所述音频增强特征对所述第一神经网络模型进行优化,得到所述目标神经网络模型,包括:
17、根据所述视觉增强特征和所述视觉特征确定第一优化函数,根据所述音频增强特征和所述音频特征确定第二优化函数;
18、根据所述第一优化函数和所述第二优化函数对所述第一神经网络模型的模型参数进行优化,得到所述目标神经网络模型。
19、其中,根据所述视觉增强特征和所述视觉特征确定第一优化函数,根据所述音频增强特征和所述音频特征确定第二优化函数,包括:
20、根据所述视觉增强特征和所述视觉特征确定第一损失函数,根据所述音频增强特征和所述音频特征确定第二损失函数。
21、其中,所述第一损失函数或所述第二损失函数的表达式为:
22、;
23、其中,ni为所有所述视频片段的数量,,m为视觉模态、音频模态,i为不大于ni的整数,为超参数,为所述第二神经网络模型的第 l层中第i个所述视频片段在模态m下的增强特征,为第i个所述视频片段在所述模态m下的特征,为温度超参数,为第i个所述视频片段在所述模态m下的样本候选池,m为视觉模态时,ls为所述第一损失函数,m为音频模态时,ls为所述第二损失函数。
24、其中,根据所述视觉增强特征和所述视觉特征确定第一优化函数,根据所述音频增强特征和所述音频特征确定第二优化函数之前,还包括:
25、对所述视觉增强特征和所述视觉特征进行矩阵对齐,对所述音频增强特征和所述音频特征进行矩阵对齐。
26、其中,根据所述视觉增强特征和所述视觉特征确定第一损失函数,根据所述音频增强特征和所述音频特征确定第二损失函数之前,还包括:
27、构建每个所述视觉特征的第一样本候选池,所述第一样本候选池中包括所述视觉特征的第一正样本集和第一负样本集;
28、构建每个所述音频特征的第二样本候选池,所述第二样本候选池中包括所述音频特征的第二正样本及和第二负样本集。
29、其中,还包括:
30、在对所述第一神经网络模型的模型参数进行优化的过程中,每隔预设时间或者每隔预设迭代次数,更新每个所述视觉特征的第一负样本集和每个所述音频特征的第二负样本集。
31、其中,根据所述第一优化函数和所述第二优化函数对所述第一神经网络模型的模型参数进行优化,得到所述目标神经网络模型,包括:
32、根据所述第一优化函数和所述第二优化函数对所述第一神经网络模型的模型参数进行优化的过程中,判断是否满足预设迭代结束条件;
33、若满足,则将满足预设迭代结束条件时的模型参数确定为所述目标神经网络模型的模型参数;
34、若不满足,则重新进入将每个所述视觉特征和所述第一知识图结构输入至第二神经网络模型,得到每个所述视觉特征对应的视觉增强特征;将每个所述音频特征和所述第二知识图结构输入至所述第二神经网络模型,得到每个所述音频特征对应的音频增强特征的步骤。
35、其中,根据所有所述视觉特征得到第一知识图结构,根据所有所述音频特征得到第二知识图结构,包括:
36、计算所有所述视觉特征中每两个所述视觉特征的第一相似度,根据所有所述第一相似度确定第一相似度矩阵;
37、计算所有所述音频特征中每两个所述音频特征的第二相似度,根据所有所述第二相似度确定第二相似度矩阵;
38、根据所述第一相似度矩阵确定所述第一知识图结构,根据所述第二相似度矩阵确定所述第二知识图结构。
39、其中,计算所有所述视觉特征中每两个所述视觉特征的第一相似度,根据所有所述第一相似度确定第一相似度矩阵;计算所有所述音频特征中每两个所述音频特征的第二相似度,根据所有所述第二相似度确定第二相似度矩阵之后,还包括:
40、对所述第一相似度矩阵进行稀疏化,得到第一稀疏矩阵;
41、对所述第二相似度矩阵进行稀疏化,得到第二稀疏矩阵;
42、根据所述第一相似度矩阵确定所述第一知识图结构,根据所述第二相似度矩阵确定所述第二知识图结构,包括:
43、根据所述第一稀疏矩阵确定所述第一知识图结构,根据所述第二稀疏矩阵确定所述第二知识图结构。
44、其中,对所述第一相似度矩阵进行稀疏化,得到第一稀疏矩阵,包括:
45、设定第一相似度阈值;
46、对于每个当前视觉特征,确定所述当前视觉特征与其他视觉特征的第三相似度,保留所述第一相似度矩阵中所述第三相似度大于或等于所述第一相似度阈值的值,并将所述第三相似度小于所述第一相似度阈值的值设为0,得到所述第一稀疏矩阵;
47、对所述第二相似度矩阵进行稀疏化,得到第二稀疏矩阵,包括:
48、设定第二相似度阈值;
49、对于每个当前音频特征,确定所述当前音频特征与其他音频特征的第四相似度,保留所述第二相似度矩阵中所述第四相似度大于或等于所述第二相似度阈值的值,并将所述第四相似度小于所述第二相似度阈值的值设为0,得到所述第二稀疏矩阵。
50、其中,对所述第一相似度矩阵进行稀疏化,得到第一稀疏矩阵,包括:
51、对于每个当前视觉特征,确定所述当前视觉特征与其他视觉特征的第三相似度,保留所述第一相似度矩阵中所述第三相似度较大的前k个值,并将除前k个值之外的其余值设为0,得到所述第一稀疏矩阵,k为正整数;
52、对所述第二相似度矩阵进行稀疏化,得到第二稀疏矩阵,包括:
53、对于每个当前音频特征,确定所述当前音频特征与其他音频特征的第四相似度,保留所述第二相似度矩阵中所述第四相似度较大的前k个值,并将除前k个值之外的其余值设为0,得到所述第二稀疏矩阵。
54、其中,根据所述第一稀疏矩阵确定所述第一知识图结构,根据所述第二稀疏矩阵确定所述第二知识图结构,包括:
55、对所述第一稀疏矩阵进行归一化处理,得到所述第一知识图结构;
56、对所述第二稀疏矩阵进行归一化处理,得到所述第二知识图结构。
57、其中,对所述第一稀疏矩阵进行归一化处理,得到所述第一知识图结构,包括:
58、利用第一公式对所述第一稀疏矩阵进行归一化处理,得到所述第一知识图结构;
59、对所述第二稀疏矩阵进行归一化处理,得到所述第二知识图结构,包括:
60、利用所述第一公式对所述第二稀疏矩阵进行归一化处理,得到所述第二知识图结构;
61、所述第一公式为:
62、;
63、其中 ,m为视觉模态或音频模态,, n i为所述视频片段的数量,为的对角矩阵,为模态 m下的稀疏矩阵; m为视觉模态时,为第一稀疏矩阵,为所述第一知识图结构, m为音频模态时,为所述第二稀疏矩阵,为所述第二知识图结构。
64、为解决上述技术问题,本发明提供了一种视频定位方法,包括:
65、待处理视频数据,所述待处理视频数据至少包括待处理视频片段和待处理音频片段;
66、标签定位单元,用于将所述待处理视频数据输入至目标神经网络模型中,得到所述待处理视频数据的类别标签;
67、所述目标神经网络模型根据上述所述的模型训练方法得到。
68、为解决上述技术问题,本发明还提供了一种模型训练系统,包括:
69、获取单元,用于获取训练数据集,所述训练数据集中包括多个视频片段对应的多个视觉特征和多个音频特征;
70、知识图构建单元,用于根据所有所述视觉特征得到第一知识图结构,根据所有所述音频特征得到第二知识图结构;
71、模型优化单元,用于根据所述第一知识图结构、所述第二知识图结构对第一神经网络模型进行优化,得到目标神经网络模型,所述目标神经网络模型用于对待处理视频数据进行类别标签定位。
72、为解决上述技术问题,本发明还提供了一种电子设备,包括:
73、存储器,用于存储计算机程序;
74、处理器,用于在存储计算机程序时,实现上述所述的模型训练方法的步骤或上述所述的视频定位方法的步骤。
75、为解决上述技术问题,本发明还提供了一种计算机程序产品,包括计算机程序/指令,该计算机程序/指令被处理器执行时实现上述所述的模型训练方法的步骤或上述所述的视频定位方法的步骤。
76、为解决上述技术问题,本发明还提供了一种非易失性存储介质,所述非易失性存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述所述的模型训练方法的步骤或上述所述的视频定位方法的步骤。
77、本发明提供了一种模型训练方法、视频定位方法、系统、设备、产品及介质,涉及视频数据处理领域,用于解决定位音频事件时将视频模态视作噪声导致定位不准确的问题。获取训练数据集;根据视觉特征得到第一知识图结构,根据音频特征得到第二知识图结构;根据第一知识图结构、第二知识图结构对第一神经网络模型优化得到目标神经网络模型;将待处理视频数据输入至目标神经网络模型,得到待处理视频数据的定位标签。本发明通过构建视觉特征和音频特征对应的知识图结构,使用知识图结构优化第一神经网络模型,并未将视觉信息视为噪声,能够捕捉和利用音频与视频之间的复杂关联关系,能够更好地整合和利用多模态数据,提高得到的目标神经网络模型的定位精度和可靠性。
本文地址:https://www.jishuxx.com/zhuanli/20240730/195800.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。