一种基于大语言模型的数学知识打标方法与流程
- 国知局
- 2024-07-31 23:09:30
本发明涉及大语言模型,具体为一种基于大语言模型的数学知识打标方法。
背景技术:
1、数学知识的学习资源海量且复杂,有效地提高学习资源的利用率和学习者的学习效率是大家在学习方面一直关注的热点问题。在学习中,无论是课件还是试题都有一定的针对性,一定的知识点和相适应的群体。采取合理的分类,简单的知识点标记,将标签和资源紧密相连,标签和学习内容相结合;
2、在传统教学领域内的知识点标签化,只是简单的对知识点和基本定义目录化的方式进行分类;但针对于学生群体来说,目前的试题内容中包括的知识点不像以前一样单一,老师课堂上的课件内容拓展知识多,知识量大;通过简单的对知识点进行分类的方式并不能很好的将试题中的知识点和课件上的知识点关联起来,也不便于学生后期的复习和自主学习。
技术实现思路
1、本发明的目的在于提供一种基于大语言模型的数学知识打标方法,以解决上述背景技术中提出的问题。
2、为了解决上述技术问题,本发明提供如下技术方案:一种基于大语言模型的数学知识打标方法,该方法包括以下步骤:
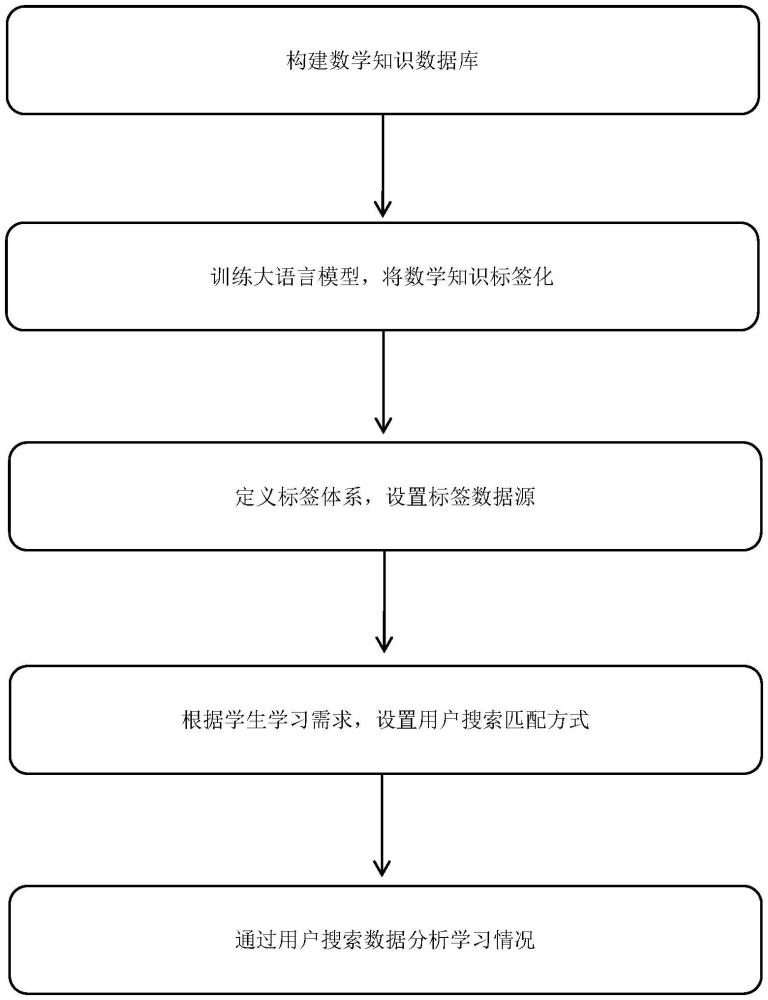
3、步骤s1:构建数学知识数据库,收集教材数学知识和教辅数学题库,归纳数学知识点;
4、步骤s2:训练大语言模型,搭建数学知识图谱,将数学知识数据库中的内容作为训练集,对数学知识进行标签化处理;
5、步骤s3:定义标签体系,将大语言模型训练得到的数学知识数据库内容标签作为第一数据源;上传课堂课件,基于数学知识库内容训进行练,对课堂课件内容进行标签化处理,作为第二数据源;
6、步骤s4:根据学生学习需求,设置用户搜索匹配方式,当学生自主学习时可通过直接查阅标签方式进行学习并查阅知识图谱中相关标签;当学生需要复习课堂课件及试题内容时,可通过输入文本数据进行标签检索,查询所需数学知识内容,并记录输出结果的标签数据来源;
7、步骤s5:通过用户搜索数据分析学习情况,收集学生用户自主搜索标签次数,计算标签权重,分析标签理解难度,对学习内容做出反馈,并对数学知识库进行更新。
8、进一步的,在步骤s1中,收集教材数学知识和教辅数学题库,构建数学知识数据库,对收集到的资料进行标记和添加元数据,并定期对数据库的内容进行更新。
9、进一步的,在步骤s2中,所述数学知识图谱搭建的方式:
10、通过主题分类的方式将数学知识库内的数学知识按照基础定义和应用题的方式进行分类,并根据数学知识之间的层次结构和递进关系,用概念节点的方式将各分类下的数学概念连接起来,构成数学知识图谱;
11、将已完成标注的文本数据样本作为训练样本投入大语言模型中,大语言模型通过学习训练样本得到学习结果作为二次训练样本;
12、对二次训练样本进行标注,输出由数学知识库内容生成的数学知识图谱,得到训练集。
13、进一步的,在步骤s3中,所述定义标签体系,将训练数据集中得到的数学知识标签设为第一数据源δ1;由教师端上传自己的课堂课件内容,转化为文本数据后,通过比对训练集将课件内容转换成数学知识图谱,将其中的数学指示标签设为第二数据源δ2。
14、进一步的,在步骤s4中,所述设置搜索匹配方式:
15、当学生用户需要自主学习时,可以直接查看感兴趣的标签内容,获取标签相关数学知识图谱,并通过数学知识图谱中包含的标签查阅相关内容,所述内容包括课堂课件、教材内容、各省历年高考数学试卷;
16、记录学生用户查询标签次数情况,来自第一数据源δ1的检索次数为m11,来自第二数据源δ2的检索次数为m12;
17、当学生用户具有检索要求时,用户输入文本数据进行检索,通过大语言模型对输入的文本数据进行分析,对文本数据进行切分,将切分结果向量化处理,检索标签向量数据库,匹配满足用户搜索要求的对象,将查询对象按照相似度从高到低进行排序,并设置相似度阈值q,只针对满足阈值q的对象进行结果输出;
18、记录学生用户查询标签次数情况,来自第一数据源δ1的检索次数为m21,来自第二数据源δ2的检索次数为m22。
19、进一步的,在步骤s5中,所述通过用户搜索数据分析对数学知识库进行更新:
20、收集学生用户搜索历史数据,获得每个标签的索引数据,分析出标签权重;标签权重为
21、其中κ1为标签检索重要程度,κ2为标签引用重要程度;根据历史数据,t为用户对标签的查阅次数,t1为标签检索查阅次数,t2为标签引用查阅次数;ν为用户搜索标签总次数;
22、设定标签权重阈值ω0=χ,通过大语言模型比对标签权重ωn和标签权重阈值ω0的大小判断是否需要增加该标签的知识数据库文本,当标签权重ωn大于标签权重阈值ω0时增加该标签的知识数据库文本;
23、课堂课件内容和数学知识库关联性λ为:
24、
25、其中ν为用户搜索标签总次数,m11为学生用户通过标签直接查找自主学习时来自第一数据源δ1的检索次数,m12为学生用户通过标签直接查找自主学习时来自第二数据源δ2的检索次数,m21为学生用户输入文本数据进行检索时来自第一数据源δ1的检索次数,m22为学生用户输入文本数据进行检索时来自第二数据源δ2的检索次数;
26、收集各课堂课件内容和数学知识关联性λn,并对关联性λn数值进行整理,按照从大到小的方式进行排序,设定关联性阈值λ0,对小于关联性阈值的课堂课件进行定期清理,并对教师端进行反馈。
27、所述通过用户搜索数据分析学习情况,对学习内容作出反馈:
28、输入需要得到反馈的数学知识文本数据,通过大语言模型对输入的文本数据进行分析,对文本数据进行切分,将切分结果进行向量化处理,检索标签向量数据库,匹配满足用户搜索要求的对象,设置反馈阈值qc,标记满足反馈阈值qc的标签;
29、则该数学知识的学习难度系数
30、其中ti为被标记满足反馈阈值qc标签的查阅次数,ηi为标签复查率;
31、通过线性回归模型分析该数学知识的学习难度系数δ和该数学知识题库试题学生用户正确率α的关系确定学习难度系数阈值δ0,线性回归模型为:
32、α=β0+β1δ+ε;
33、其中β0、β1为回归系数,ε为误差项,数学知识题库学生用户正确率α由大语言模型统计的历史数据中得到;
34、教师端通过对学习难度系数的分析,判断该数学知识困难程度,当学习难度系数大于学习难度系数阈值时,表示学生对该数学知识理解掌握困难,需要增加该数学知识相关课时;当难度系数小于难度系数阈值时,表示学生对该数学知识理解掌握简单,可减小相关课时和课件数量。
35、与现有技术相比,本发明所达到的有益效果是:本发明通过大语言模型将数学知识和课堂课件标签化并通过大语言模型学习数学知识图谱构建的方式将标签按照层次结构、关系连接连接起来,学生用户可以更加高效、便捷、直观的了解到数学知识及课堂内容,节省查阅资料所需时间,提高学习效率;
36、通过标签检索数据,教师端可以了解到学生用户的学习情况,针对学生对数学知识学习的困难程度对课堂内容进行调整;根据学生搜索历史分析标签权重,对数学知识库内容进行更新,使教学内容更具有针对性。
本文地址:https://www.jishuxx.com/zhuanli/20240730/196134.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表