综合的医疗机构违规风险的自动识别方法及系统与流程
- 国知局
- 2024-07-31 23:14:48
本发明涉及计算机应用,具体地,涉及一种综合的医疗机构违规风险的自动识别方法及系统。
背景技术:
1、目前,对定点医疗机构的监管不断趋严,但缺少相对客观准确的风险评估手段。
2、传统的机构风险评估主要基于历史相关行政处罚事件进行评分,颗粒度和时效性均较差。因为行政处罚相对于实际违规行为,往往存在较大的偶然性,受到检查时间、力度、重点和检查人员个体差异的显著影响:如专项检查、飞行检查开展的时间通常具有随机性和滞后性,且不同的突击检查中检查主题和侧重点也不一致。另外违规风险指标往往仅考虑某一个来源的检查违规结果数据,未形成多来源的数据汇总,导致风险评价的稳定性差。
3、其次机构风险评价的数据获取难度较大,需要专项的人力投入。这导致机构的风险评价的周期往往以年度为单位,不能及时对机构采取不同程度的监管措施和关注程度,也无法观察到机构年度内的风险变动。
4、最后传统机构风险评价的特征主要集中在医保结算数据维度,而较少从已有的违规结果中挖掘违规模式特点,进而构造综合的风险指标。
5、因此,需要构建一种新的风险评估方法,克服传统医保监管领域中自然风险结局标签数据缺失、现有的各类数据碎片化,缺少及时、稳定监管手段的挑战。
6、专利文献cn113627525a公开了一种特征提取模型的训练方法,可以应用于金融领域及人工智能技术领域。该特征提取模型的训练方法包括:获取对第一历史医疗信息进行预处理得到的第一描述信息,其中,第一描述信息用于描述用户针对医保项目消耗的资源信息,其中,相同资源信息对应多种不同的第一描述信息;基于第一描述信息,生成分词编码数据,其中,相同资源信息对应唯一的分词编码数据;以及利用分词编码数据训练待训练的特征提取模型,得到训练完成的特征提取模型,其中,特征提取模型用于提取分词编码数据的向量化特征。但该发明没有对预测结果提供归因分析,得到各机构的重要影响特征。
技术实现思路
1、针对现有技术中的缺陷,本发明的目的是提供一种综合的医疗机构违规风险的自动识别方法及系统。
2、根据本发明提供的一种综合的医疗机构违规风险的自动识别方法,包括:
3、步骤s1:输入数据并进行数据处理;
4、步骤s2:根据数据计算各系统内部风险分,通过赋予的权重矩阵,得到综合风险分初始值;
5、步骤s3:预测动态综合风险分,构建特征指标,输入随机森林预测模型,并输出结果;
6、步骤s4:对随机森林预测得到的结果进行归因分析。
7、优选地,在所述步骤s1中:
8、输入的数据,包括:信用评价数据、疑点数据和违规处罚数据、大数据模型数据、就诊信息和处方明细数据;
9、信用评价数据,包括:医疗机构编码、医疗机构名称、医疗机构等级、信用得分和信用等级;
10、疑点数据和违规处罚数据,包括:医疗机构编码、医疗机构名称、违规行为发生时间段、预设疑点金额、预设违规金额和违规项目;
11、大数据模型数据,包括:医疗机构编码、违规行为发生时间、流水号和风险分;
12、就诊信息,包括:医疗机构名称、医疗机构等级、出入院时间、就诊类型、疾病诊断、住院天数、医疗总费用、个账支出和医保基金支出;
13、处方明细数据,包括:医疗机构名称、流水号、交易时间、项目类别、明细项目名称、明细项目编码、明细项目金额和明细项目使用量;
14、对数据进行处理,包括:
15、将年龄设置为介于0至110之间的整数;
16、将性别设置为男性或女性;
17、医疗机构等级设置为一级、二级和三级;
18、项目名称标准化映射至医保目录,剔除金额为负的项目
19、剔除预设的普遍使用的项目:
20、刨除预设的入院常规检查项目,包括血常规,尿常规,肝功和肾功;
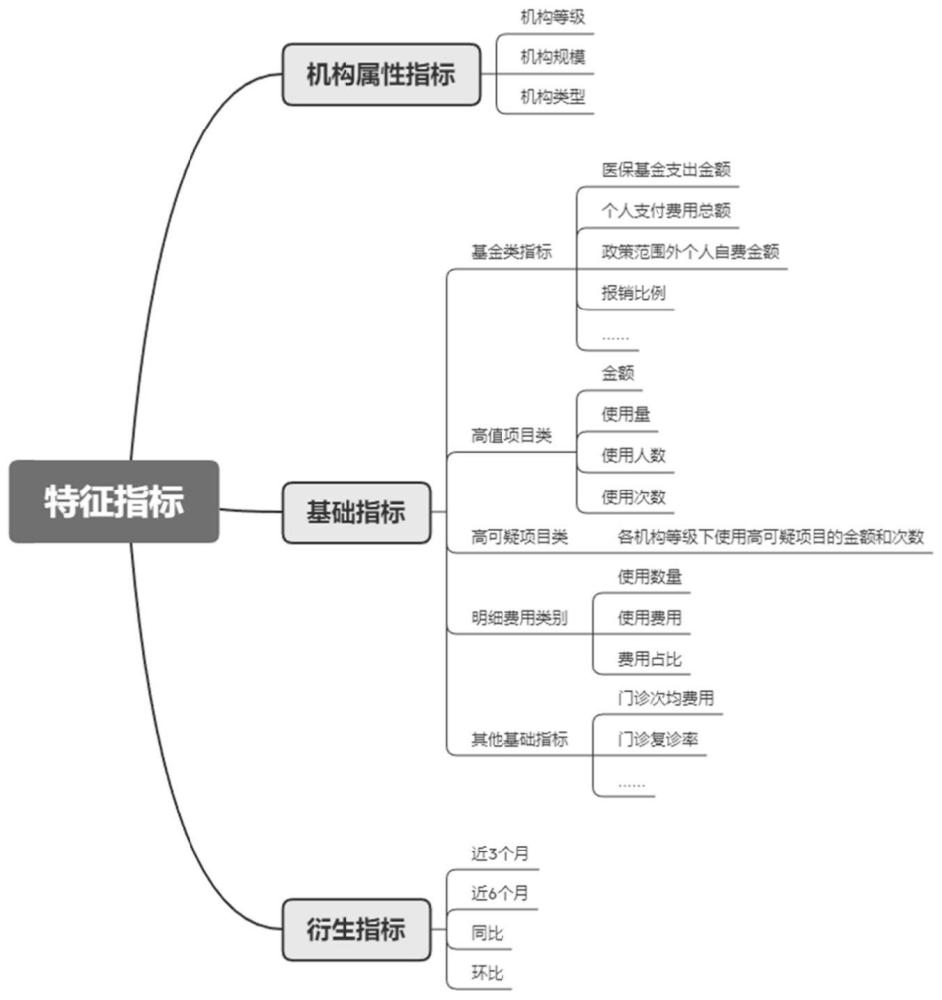
21、刨除预设的对于诊断特异性不大的项目;
22、刨除预设的含义不明确的项目,包括诊查费、诊察费和5%西药报销。
23、优选地,在所述步骤s2中:
24、计算各系统内部风险分:
25、已经查实违规行为的数据:将数据拆分到行为发生时间所在的月份,计算绝对量指标:违规金额和违规金额占机构总费用的比重;计算相对量指标:违规金额排名和违规金额占机构总费用的比重排名;
26、指标预警数据:指标预警根据指标计算风险分,按月对医疗机构计算风险分和风险分的排名指标;
27、大数据模型数据:将与医疗机构相关的大数据模型,按医疗机构和违规行为发生的月份,对风险分进行汇总得到月度总风险分的排名;
28、对各来源的数据内部的绝对指标和相对指标分别赋予权重,两个指标的权重之和为1;若存在多个相对指标和绝对指标,则所有相对指标和绝对指标的权重之和为1;对多个系统分别赋予不同的权重,权重之和为1;
29、通过赋予的权重初始值矩阵,得到机构月度的综合风险分初始值,对初始矩阵进行调整。
30、优选地,在所述步骤s3中:
31、构建特征指标:
32、特征指标包含:机构属性指标、基础指标和衍生指标;
33、机构属性指标:不随滚动周期变动;
34、基础指标:包括门诊指标群、住院指标群和不区分门诊住院的总指标群;
35、衍生指标:衍生指标为基础指标在近3个月、近6个月、同比和环比维度下的计算值;其中近3个月和近6个月分别为以当前月份为起点,滚动向前2个月和5个月的范围内的数值;
36、获取特征指标和机构的综合风险分,对数据进行处理后输入随机森林模型,具体步骤如下:
37、风险分的处理:分别计算医疗机构以当前月份为起点的近3个月的总风险分,平均风险分,并对风险分进行0至1标准化处理,得到月度标准风险分,近3个月标准总风险分,近3个月标准平均风险分;
38、特征指标的处理:将原始指标中的趋向于正负无穷的数值和缺失值用0填充,将输入特征中的月份特征剔除;
39、训练测试集的划分:将已有数据中最后一个月的数据作为测试集,其余为训练集,根据训练集中的风险分分布和专家经验,制定风险等级对应的风险分阈值,得到高中低三个风险等级;
40、模型训练和评价:分别采用月度标准风险分、近3个月标准总风险分和近3个月标准平均风险分输入模型,采用网格搜索的方式进行调参,根据f1-score选择最佳的y形式,确定近3个月标准平均风险分的效果最好;
41、模型输出:输出预测月份的风险分,风险分对应的风险等级,以及模型的特征重要性。
42、优选地,在所述步骤s4中:
43、对随机森林预测得到的高风险的机构,采用shap归因模型,输出得到各个特征的shap影响值。
44、根据本发明提供的一种综合的医疗机构违规风险的自动识别系统,包括:
45、模块m1:输入数据并进行数据处理;
46、模块m2:根据数据计算各系统内部风险分,通过赋予的权重矩阵,得到综合风险分初始值;
47、模块m3:预测动态综合风险分,构建特征指标,输入随机森林预测模型,并输出结果;
48、模块m4:对随机森林预测得到的结果进行归因分析。
49、优选地,在所述模块m1中:
50、输入的数据,包括:信用评价数据、疑点数据和违规处罚数据、大数据模型数据、就诊信息和处方明细数据;
51、信用评价数据,包括:医疗机构编码、医疗机构名称、医疗机构等级、信用得分和信用等级;
52、疑点数据和违规处罚数据,包括:医疗机构编码、医疗机构名称、违规行为发生时间段、预设疑点金额、预设违规金额和违规项目;
53、大数据模型数据,包括:医疗机构编码、违规行为发生时间、流水号和风险分;
54、就诊信息,包括:医疗机构名称、医疗机构等级、出入院时间、就诊类型、疾病诊断、住院天数、医疗总费用、个账支出和医保基金支出;
55、处方明细数据,包括:医疗机构名称、流水号、交易时间、项目类别、明细项目名称、明细项目编码、明细项目金额和明细项目使用量;
56、对数据进行处理,包括:
57、将年龄设置为介于0至110之间的整数;
58、将性别设置为男性或女性;
59、医疗机构等级设置为一级、二级和三级;
60、项目名称标准化映射至医保目录,剔除金额为负的项目
61、剔除预设的普遍使用的项目:
62、刨除预设的入院常规检查项目,包括血常规,尿常规,肝功和肾功;
63、刨除预设的对于诊断特异性不大的项目;
64、刨除预设的含义不明确的项目,包括诊查费、诊察费和5%西药报销。
65、优选地,在所述模块m2中:
66、计算各系统内部风险分:
67、已经查实违规行为的数据:将数据拆分到行为发生时间所在的月份,计算绝对量指标:违规金额和违规金额占机构总费用的比重;计算相对量指标:违规金额排名和违规金额占机构总费用的比重排名;
68、指标预警数据:指标预警根据指标计算风险分,按月对医疗机构计算风险分和风险分的排名指标;
69、大数据模型数据:将与医疗机构相关的大数据模型,按医疗机构和违规行为发生的月份,对风险分进行汇总得到月度总风险分的排名;
70、对各来源的数据内部的绝对指标和相对指标分别赋予权重,两个指标的权重之和为1;若存在多个相对指标和绝对指标,则所有相对指标和绝对指标的权重之和为1;对多个系统分别赋予不同的权重,权重之和为1;
71、通过赋予的权重初始值矩阵,得到机构月度的综合风险分初始值,对初始矩阵进行调整。
72、优选地,在所述模块m3中:
73、构建特征指标:
74、特征指标包含:机构属性指标、基础指标和衍生指标;
75、机构属性指标:不随滚动周期变动;
76、基础指标:包括门诊指标群、住院指标群和不区分门诊住院的总指标群;
77、衍生指标:衍生指标为基础指标在近3个月、近6个月、同比和环比维度下的计算值;其中近3个月和近6个月分别为以当前月份为起点,滚动向前2个月和5个月的范围内的数值;
78、获取特征指标和机构的综合风险分,对数据进行处理后输入随机森林模型,具体步骤如下:
79、风险分的处理:分别计算医疗机构以当前月份为起点的近3个月的总风险分,平均风险分,并对风险分进行0至1标准化处理,得到月度标准风险分,近3个月标准总风险分,近3个月标准平均风险分;
80、特征指标的处理:将原始指标中的趋向于正负无穷的数值和缺失值用0填充,将输入特征中的月份特征剔除;
81、训练测试集的划分:将已有数据中最后一个月的数据作为测试集,其余为训练集,根据训练集中的风险分分布和专家经验,制定风险等级对应的风险分阈值,得到高中低三个风险等级;
82、模型训练和评价:分别采用月度标准风险分、近3个月标准总风险分和近3个月标准平均风险分输入模型,采用网格搜索的方式进行调参,根据f1-score选择最佳的y形式,确定近3个月标准平均风险分的效果最好;
83、模型输出:输出预测月份的风险分,风险分对应的风险等级,以及模型的特征重要性。
84、优选地,在所述模块m4中:
85、对随机森林预测得到的高风险的机构,采用shap归因模型,输出得到各个特征的shap影响值。
86、与现有技术相比,本发明具有如下的有益效果:
87、1、本发明创新性地构建综合动态风险分;
88、2、本发明对预测结果提供归因分析,得到各机构的重要影响特征,具有实用价值;
89、3、本发明按月度频率更新季度周期模型,综合考虑了实际数据质量、模型敏感度、风险趋势变化规律等因素,风险识别效果更加稳健。
本文地址:https://www.jishuxx.com/zhuanli/20240730/196616.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表