引入ESA的2D数字人人像抠图方法及系统与流程
- 国知局
- 2024-07-31 23:15:31
本发明涉及图像处理,具体地说是引入esa的2d数字人人像抠图方法及系统。
背景技术:
1、在神经网络中,注意力机制是一种重要的技术,用于增强模型对输入信息的关注度,从而提高模型在处理复杂任务时的性能。传统的神经网络模型对所有输入信息一视同仁,无法有效地区分输入信息的重要性,这在处理大规模空间信息时会导致性能下降和计算成本增加。因此,注意力机制的引入成为了解决这一问题的有效途径。sa空间自注意力机制是目前应用较为广泛的一种注意力机制,在处理空间信息时表现出了良好的效果。其通过学习输入空间信息之间的关系,动态地分配不同位置的注意力权重,从而使模型能够聚焦于输入信息中最重要的部分。
2、portrait matting人像抠图是语义分割的高频应用实例,其作为许多任务的前置或后置处理的重要组成部分,起到无可替代的作用。在2d数字人制作全流程技术中尤其凸显,其在tfg多种模型,如wav2lip、videoretalking、dinet、synctalkface等的人脸回帖后处理中决定了最终的可视化效果。目前的人像抠图算法主要包括trimap-based和trimap-free两类,后者的效果弱于前者,但是考虑实际应用中获得先验知识的难度,多数情况下仍然选择trimap-free的方法,如faceparsing、modnet以及sam和基于sam改进的sam-track等。
3、空间自注意力机制提出的底层思想是协助模型关注与任务强关联度的特征,增强网络的学习能力,从而提升模型的表达能力。但是现有自注意力机制的设计,往往依托数据路径设计策略即前馈传播机制实现,而学习的实质是通过反向梯度传播链式求导法则实现的,具体而言,对网络学习内容更具影响力的是不同的任务目标和损失约束策略,而不是前馈序列中的相关层影响。
4、如何基于空间注意力机制实现性能延迟平衡的人像抠图,是需要解决的技术问题。
技术实现思路
1、本发明的技术任务是针对以上不足,提供引入esa的2d数字人人像抠图方法及系统,来解决如何基于空间注意力机制实现性能延迟平衡的人像抠图的技术问题。
2、本发明一种引入esa的2d数字人人像抠图方法,包括如下步骤:
3、s100数据采集:采集数据集,包括coco8-seg数据集以及开源的p3m-10k人像抠图数据集,对于p3m-10k人像抠图数据集,其训练集中图像均为保护了人脸隐私的图像,其中两个测试集中图像为没有隐私问题的图像,coco8-seg数据集中包含多类目标的语义分割数据;
4、s200数据集构建:基于coco8-seg数据集以及开源的p3m-10k人像抠图数据集构建样本数据集,样本数据集中包括保护了人脸隐私的图像和没有人脸隐私问题的图像,并对样本数据集进行划分,得到训练验证集和测试集;
5、s300图像预处理:对于训练验证集中每个图像以及对应的遮罩,对所述图像以及对应的遮罩进行数据增强以及图像预处理,得到预处理后的训练验证集;
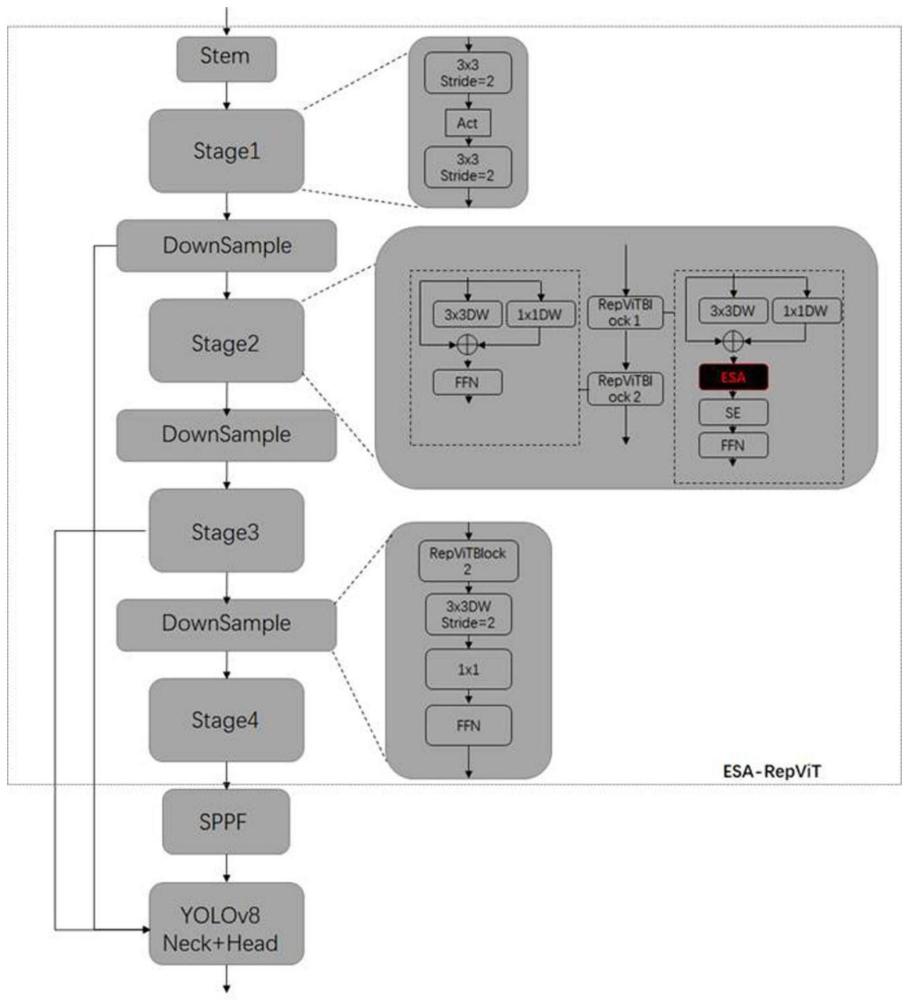
6、s400模型构建:在repvit网络模型中引入esa模块得到esa-repvit主干网络模型,将esa-repvit主干网络模型作为主干网络、基于yolov8网络构建人像抠图网络模型;
7、s500模型训练:基于预处理后的训练验证集对人像抠图网络模型进行模型训练和模型验证,并基于测试集对训练后的人像抠图网络模型进行测试,得到训练后人像抠图网络模型;
8、s600人像抠图:对于待处理的2d人像,对所述图像进行数据增强以及图像预处理,得到预处理后的图像,以预处理后的图像为输入、通过训练后人像抠图网络模型进行特征提取,输出对应的遮罩。
9、作为优选,构建数据集包括如下步骤:
10、对于p3m-10k人像抠图数据集中两个没有人脸隐私问题的测试集,人工筛选出α个图像,其中,第i个数据对应的图像为ai,其中,i∈{1,2,…,α};
11、对于coco8-seg数据集中person数据,人工筛选出β张图像,第j张图像为bj,其中,j∈{1,2,…,β};
12、混合筛选出的图像ai和图像bj、构建指导数据集dm,其中,m∈{1,2,…,α+β};
13、对于指导数据集dm,从中筛选出γ张图像,并从p3m-10k人像抠图数据集中筛选出δ张保护了人脸隐私的图像,构建γ+δ张图像的训练验证集fk,其中,k∈{1,2,…,γ+δ},并对训练验证集中训练数据和验证数据进行比例划分;
14、基于剩余的(α+β-γ)张图像构建测试集。
15、作为优选,对所述图像以及对应的遮罩进行数据增强以及图像预处理,包括如下步骤:
16、对于图像fk,利用python中的colorjitter函数对图像进行增强,并连同对应的遮罩mk进行随机裁剪、随机平移、水平翻转操作,得到增强后的图像fik和遮罩mik;
17、将增强后的图像fik及其遮罩mik缩放至640×640像素,利用python对fik依次进行张量转化、归一化、维度扩增、维度倒置操作,得到预处理后的图像f’k和遮罩m’k。
18、作为优选,所述人像抠图网络模型包括esa-repvit网络结构、sppf模块、neck部和head部,颈部包括pan网络结构,所述人像抠图网络模型用于执行如下对输入的图像进行特征提取输出遮罩:
19、l100、将图像iin输入esa-repvit网络结构,依次经过stage2、stage3、stage4模块,分别得到fms2、fms3以及fms4;
20、l200、将fms4带入sppf模块,得到fmsppf,其中,
21、
22、l300、将fmsppf与fms2、fms3分别输入pan网络中进行多尺度特征融合和提取,并将pan网络的输出输入head部,通过输出层得到最终的人像抠图mask。
23、作为优选,步骤l100包括如下操作:
24、l110、图像iin输入stem模块,依次经过卷积核为3×3且步长为2的卷积块、激活函数模块、卷积核为3×3且步长为2的卷积块,分别得到fm1-1、fm1-2以及fm1-3,其中,
25、l120、将fm1-3输入stage1模块,依次经过两个repvitblock网络结构,两个repvitblock网络结构分别为第一个repvitblock1和第二个repvitblock2,第一个repvitblock1中依次经过并行3×3和1×1深度卷积构成的融合空间信息的token mixer、esa模块、se模块以及串行1x1扩展卷积层和1x1投影层用以实现通道之间互动的ffn模块,分别得到
26、在第二个repvitblock2中依次经过并行3×3和1×1深度卷积构成的融合空间信息的token mixer、串行1x1扩展卷积层和1x1投影层用以实现通道之间互动的ffn模块,分别得到
27、l130、将fm2-6输入downsample模块,依次经过repvitblock2、卷积核为3×3且步长为2的深度卷积块、1×1卷积块以及ffn模块,分别得到
28、l140、将fm3-4输入stage2模块,依次经过两个repvitblock,两个repvitblock分别为第一个repvitblock1和第二个repvitblock2,在第一个repvitblock1中依次经过tokenmixer、esa模块、se模块以及ffn模块,分别得到在第二个repvitblock2中依次经过tokenmixer、ffn模块,分别得到
29、l150、将fm4-6输入downsample模块,依次经过repvitblock2、卷积核为3×3且步长为2的深度卷积块、1×1卷积块以及ffn模块,分别得到
30、l160、将fm5-4输入stage3模块,依次经过两个repvitblock,在第一个repvitblock1中依次经过token mixer、esa模块、se模块以及ffn模块,分别得到在第二个repvitblock2中依次经过tokenmixer、ffn模块,分别得到
31、l170、将fm6-6输入downsample模块,依次经过repvitblock2、卷积核为3×3且步长为2的深度卷积块、1×1卷积块以及ffn模块,分别得到
32、l180、将fm7-4输入stage4模块,依次经过两个repvitblock,在第一个repvitblock1中依次经过token mixer、esa模块、se模块以及ffn模块,分别得到在第二个repvitblock2中依次经过tokenmixer、ffn模块,分别得到
33、作为优选,步骤l120包括如下步骤:
34、将fm2-1并行输入到c-gap和c-gmp模块分别沿通道进行全局平均池化和全局最大池化,得到和
35、将fm2-1-1和fm2-1-2按通道进行并置,得到随后进行1×1卷积和sigmoid激活函数处理,得到
36、将监督遮罩m’k缩放至160×160像素,并与fm2-1-4构建lmse损失约束;
37、将fm2-1-4重作用于fm2-1进行hadamard乘积,得到fm2-2。
38、作为优选,步骤l140中,通过的esa模块执行如下:
39、将fm4-1并行输入到c-gap和c-gmp模块分别沿通道进行全局平均池化和全局最大池化,得到和
40、将fm4-1-1和fm4-1-2按通道进行并置,得到随后进行1×1卷积和sigmoid激活函数处理,得到
41、将监督遮罩m’k缩放至80×80像素,并与fm4-1-4构建lmse损失约束;
42、将fm4-1-4重作用于fm4-1进行hadamard乘积,得到fm4-2。
43、作为优选,步骤l160中,通过esa模块执行如下:
44、将fm6-1并行输入到c-gap和c-gmp模块分别沿通道进行全局平均池化和全局最大池化,得到和
45、将fm6-1-1和fm6-1-2按通道进行并置,得到随后进行1×1卷积和sigmoid激活函数处理,得到
46、将监督遮罩m’k缩放至40×40像素,并与fm6-1-4构建lmse损失约束;
47、将fm6-1-4重作用于fm6-1进行hadamard乘积,得到fm6-2。
48、作为优选,步骤l180中通过esa模块执行如下操作:
49、将fm8-1并行输入到c-gap和c-gmp模块分别沿通道进行全局平均池化和全局最大池化,得到和
50、将fm8-1-1和fm8-1-2按通道进行并置,得到随后进行1×1卷积和sigmoid激活函数处理,得到
51、将监督遮罩m’k缩放至20×20像素,并与fm8-1-4构建lmse损失约束;
52、将fm8-1-4重作用于fm8-1进行hadamard乘积,得到fm8-2。
53、第二方面,本发明一种引入esa的2d数字人人像抠图系统,用于通过如第一方面任一项所述的一种引入esa的2d数字人人像抠图方法对2d人数字人人像进行抠图,所述系统包括数据采集模块、数据集构建模块、图像预处理模块、模型构建模块、模型训练以及人像抠图模块;
54、所述数据采集模块用于执行如下:采集数据集,包括coco8-seg数据集以及开源的p3m-10k人像抠图数据集,对于p3m-10k人像抠图数据集,其训练集中图像均为保护了人脸隐私的图像,其中两个测试集中图像为没有隐私问题的图像,coco8-seg数据集中包含多类目标的语义分割数据;
55、所述数据集构建模块用于执行如下:基于coco8-seg数据集以及开源的p3m-10k人像抠图数据集构建样本数据集,样本数据集中包括保护了人脸隐私的图像和没有人脸隐私问题的图像,并对样本数据集进行划分,得到训练验证集和测试集;
56、所述图像预处理模块用于执行如下:对于训练验证集中每个图像以及对应的遮罩,对所述图像以及对应的遮罩进行数据增强以及图像预处理,得到预处理后的训练验证集;
57、所述模型构建模块用于执行如下:在repvit网络模型中引入esa模块得到esa-repvit主干网络模型,将esa-repvit主干网络模型作为主干网络、基于yolov8网络构建人像抠图网络模型;
58、所述模型训练模块用于执行如下:基于预处理后的训练验证集对人像抠图网络模型进行模型训练和模型验证,并基于测试集对训练后的人像抠图网络模型进行测试,得到训练后人像抠图网络模型;
59、所述人像抠图模块用于执行如下:对于待处理的2d人像,对所述图像进行数据增强以及图像预处理,得到预处理后的图像,以预处理后的图像为输入、通过训练后人像抠图网络模型进行特征提取,输出对应的遮罩。
60、本发明的引入esa的2d数字人人像抠图方法及系统具有以下优点:
61、1、提出的esa注意力机制,以梯度路径设计策略为指导,引入高质量遮罩进行辅助监督,相比于数据路径设计策略指导下设计更深的网络结构以获取丰富的梯度流,大大减少了网络的规模,提升了推理前馈传播效率,且性能较好,适用于端侧实时处理;
62、2、引入esa机制改造的esa-repvit网络,使全局信息得到了二次递增关注,更符合人像抠图任务的主观认知,提升全局细粒度信息和语义信息的表征能力。
本文地址:https://www.jishuxx.com/zhuanli/20240730/196661.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表