基于数据关系图的数据湖大规模表聚类方法、存储介质以及电子装置
- 国知局
- 2024-07-31 23:17:03
本发明涉及数据挖掘以其应用领域,尤其涉及一种基于数据关系图的数据湖大规模表聚类方法、存储介质以及电子装置。
背景技术:
1、数据湖是一种存储和管理大量异构数据的分布式系统,其中的数据以其原始的形式存储,并提供了灵活的方式对数据进行处理和分析。数据湖的出现为数据科学家等专业人员提供了一个高效便捷的数据操作和管理环境。近年来,数据湖得到了广泛的关注,与尤其在相关数据集发现方面,通过挖掘原始数据的相关性,能有效提升数据湖中的数据可用性。随着政府开放数据运动的推进,可从数据湖中获取大量的表格用于数据分析,但组织和访问它们的难度也在增大。由于这些表以原始形式存储在数据湖中,表间关系和联系未知,表的属性名、属性值表达术语不同等问题,难以从这些高度多样化的表中提取有价值的信息,但对大量结构化数据源的访问需求呈现急剧增长的趋势。
2、访问大量结构化数据源的方法之一是数据集成。数据集成系统为用户提供一个统一的接口来访问一组数据源。一般情况下,数据集成系统需要先定义中介模式,一个中介模式表示一个正在考虑的领域,用户通过中介模式和系统交互,然后定义从各个数据源的模式到该中介模式的映射。很多工作通过向用户推荐中介模式和模式映射来促进这一过程。全自动的数据集成生成不精确的中介模式和模式映射,一般接受近似的不完全的集成作为起点,并在需要时进一步增强和改进。但全自动的集成技术只能处理属于同一域的数据源,因此在进行数据集成之前,仍然需要一个将表聚类到域中的预处理阶段。但目前少有工作将大规模表自动聚类到领域中。随着数据湖的长期部署和使用,数据湖变得非常多样化,这使得很难找到同一领域的相关表。因此,数据湖需要提供按领域聚类表的服务,以提升湖中数据的可用性。
3、一个通用的表领域聚类过程首先需要构造合适的特征来描述表;其次,根据提取到的特征,将湖中表聚类为多个簇;最后对每簇表的统一领域进行分类。而特征构造和表聚类是实现表领域聚类的核心。特征构造的目的是确定相关的属性,并量化它们的相关度。在特征构造阶段,会面临一些问题:首先,考虑到湖中的数据量非常大,基于数据值的特征需要对所有属性值进行一次扫描,会产生大量的时间开销。其次,属性层次的特征仅能判断两个表的两个属性是否相关,不足以支撑表层次的领域聚类。在表聚类阶段,会根据表之间的领域相关度,将湖中表划分成多个簇,簇内表的领域相关度足够大,簇间表的领域差异度足够大。在对表聚类的过程中会面临一些问题:首先,由于湖中数据会动态变化,无法根据先验知识确定聚类的数量。其次,由于湖中数据规模巨大,聚类过程需要耗费大量的计算时间。
4、由于数据湖中的数据量通常非常大而且随着业务的发展,数据湖会不断摄入新的数据,这就要求领域聚类算法能及时反映数据的变化。因此,数据湖表领域聚类应保证聚类结果的精度和聚类过程的速度,这关系到数据湖的价值和可用性。在表聚类阶段,基于距离的划分聚类算法,如k-means,往往比分层聚类算法速度更快,但精度却有所降低。因此,可尝试优化k-means算法的输入,保证同一领域的表语义距离足够小,不同领域的表的语义距离足够大,这样可以保证领域聚类速度的同时,提高领域聚类的精度。目前的图嵌入技术能够提升分类图中节点的精度,可用于优化表聚类算法的输入。当前一些基于网络或超图的元模型已经被提出用于数据湖。引入数据关系图可提升大规模表领域聚类的准确率和速率,对于特征构造:1、数据关系图可以很好地组织提取的特征,并可清晰表达全局的数据关联情况。2、基于图中节点的邻接信息,可生成描述表语义的向量,进而可计算全湖任意两表间的领域相关度。对于聚类过程:1、利用基于关系图生成的表语义向量,可提高聚类过程的自动化程度,并降低聚类算法的复杂度。但是,在使用数据关系图的具体过程中仍然存在一系列的问题。
5、当前的数据关系图模型局限于根据属性层次或局部表的相关性,而未能在全局层面按照表层次的语义相关性对表进行组织和集成。而只有将表按照表层次的语义相关度组织成全局图,才能根据图中节点的邻接信息生成描述表语义的向量,进而进行领域聚类。但由于湖中数据规模更大、动态性更强,构建全局关系图时,需要考虑计算成本,构造合适的特征以加快计算表层次的语义相关度是有难度的。另外,设计语义相似表发现算法时,既需要保证发现结果的高准确率、高召回率,同时也要保证发现过程的速度,这更是有挑战的。湖中数据的内容和领域会随业务需求和数据来源的变化而不断演变,这意味着无法预先定义所有可能的领域。另外,数据关系图中节点的邻接信息蕴含着表间复杂的相关情况,如何学习这些信息,生成能够描述表语义的特征向量是有难度的。最后,由于湖中数据会不断演变,需要自适应地确定聚类标准和聚类数量。而且在数据湖超大数据规模下进行表领域聚类,聚类算法应具有较低的复杂度。
6、针对相关数据集发现、数据关系图构建、数据集聚类有很多工作。但这些工作仍存在一些不足:在相关数据集发现方面:当前工作局限于为给定表搜索可连接、可合并、以某种形式相似或互补的表,而未能为给定表发现领域相同的相关表。在数据湖场景下的数据关系图构建方面:当前工作局限于根据属性层次或局部表间的相关性组织和集成湖中的表,而未能在全局层面按照表层次的语义相关性对表进行组织和集成,导致无法根据图中节点的邻接信息生成描述表语义的特征向量,也就无法用于湖中表的聚类。在数据聚类方面:当前少有工作对大量结构化数据进行聚类和领域聚类,而主要针对文本数据进行聚类和主题建模。但由于结构化数据和文本数据在数据结构、相关性定义等方面存在差异,针对文本数据的工作无法直接应用于结构化数据。
7、因此,如何提升大规模数据湖环境下表领域聚类的精度和速度,是当前学术界和工业界亟需解决的核心问题。
技术实现思路
1、本技术各示例性实施例提供一种基于数据关系图的数据湖大规模表聚类方法、装置、存储介质以及电子装置,以实现提升大规模数据湖环境下表领域聚类的精度和速度的技术效果。
2、本技术各示例性实施例提出一种基于数据关系图的数据湖大规模表聚类方法,所述方法包括以下步骤:
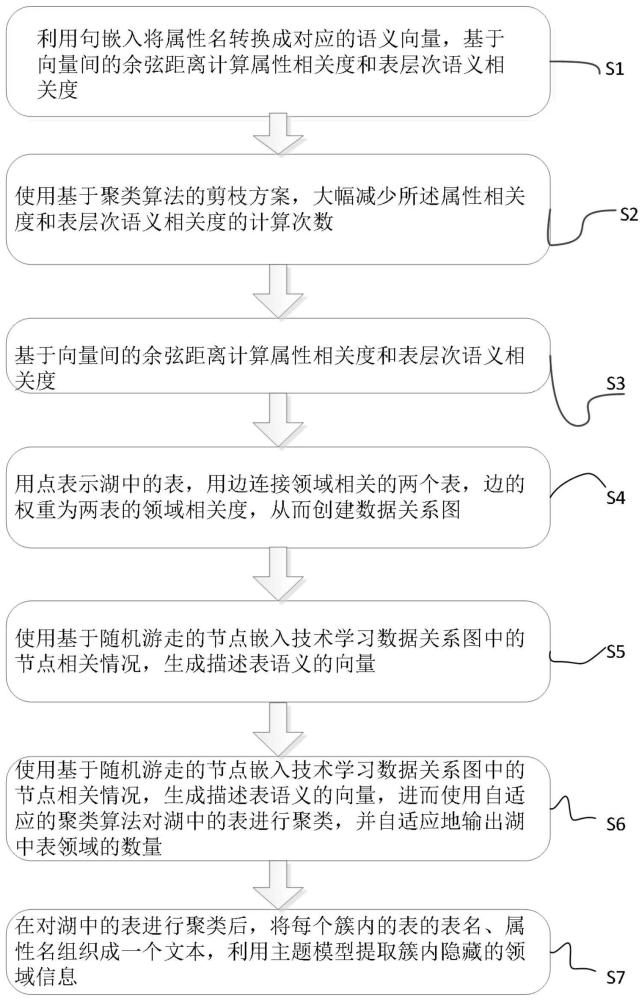
3、s1、利用句嵌入将属性名转换成对应的语义向量,基于向量间的余弦距离计算属性相关度和表层次语义相关度;
4、s2、使用基于聚类算法的剪枝方案,大幅减少所述属性相关度和表层次语义相关度的计算次数;
5、s3、基于向量间的余弦距离计算属性相关度和表层次语义相关度;
6、s4、用点表示湖中的表,用边连接领域相关的两个表,边的权重为两表的领域相关度,从而创建数据关系图;
7、s5、使用基于随机游走的节点嵌入技术学习数据关系图中的节点相关情况,生成描述表语义的向量;
8、s6、使用基于随机游走的节点嵌入技术学习数据关系图中的节点相关情况,生成描述表语义的向量,进而使用自适应的聚类算法对湖中的表进行聚类,并自适应地输出湖中表领域的数量;
9、s7、在对湖中的表进行聚类后,将每个簇内的表的表名、属性名组织成一个文本,利用主题模型提取簇内隐藏的领域信息。
10、在本技术的另一个方面,还提出了一种计算机可读的存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行上述任一项方法实施例中的步骤。
11、在本技术的另一个方面,还提出了一种电子装置,包括存储器和处理器,其特征在于,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行上述任一项方法实施例中的步骤。
12、有益效果:
13、首先利用句嵌入将属性名转换成对应的语义向量,基于向量间的余弦距离计算属性相关度和表层次语义相关度。在最坏情况下需要计算相关度的数量是二次级的,本发明使用基于聚类算法的剪枝方案,大幅减少两种相关度的计算次数。本发明用点表示湖中的表,用边连接领域相关的两个表,边的权重为两表的领域相关度,从而创建数据关系图。其次,使用基于随机游走的节点嵌入技术学习数据关系图中的节点相关情况,生成描述表语义的向量,进而使用自适应的聚类算法对湖中的表进行聚类,并自适应地输出湖中表领域的数量。在对湖中的表进行聚类后,将每个簇内的表的表名、属性名组织成一个文本,利用主题模型提取簇内隐藏的领域信息。本发明可快速、精准、自适应地对大规模数据湖中的表按照领域进行聚类、估计湖中表的领域数量并输出领域类型。
本文地址:https://www.jishuxx.com/zhuanli/20240730/196802.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表