支路内支路间嵌套注意力3D点云降噪网络
- 国知局
- 2024-07-31 23:17:21
本发明属于图像降噪算法领域,具体涉及的是一种支路内支路间嵌套注意力3d点云降噪网络。
背景技术:
1、作为一种三维数据的表征方式,点云较之二维图像具有更高的空间信息表达能力。这种表达能力让点云能更精确地捕捉到物体或场景的外形与结构,还能细致反应其深度信息和空间位置。这一特性使点云在城市规划、虚拟现实和增强现实、生物医学成像及文化遗产保护等领域,具有显著的应用潜力。
2、点云数据在采集过程中不可避免地会受到噪声的影响,这些噪声源可能包括扫描设备的精度限制、环境因素(例如光照条件和物体表面的反射特性)以及生成算法]等限制。噪声的存在不仅降低了点云数据的整体质量,而且对数据的后续处理和应用产生了不利影响。例如,在执行点云配准任务时,噪声可能会误导配准过程,降低模型的精度;在进行物体识别时,噪声的存在可能会降低识别过程的可靠性。因此,开发有效的点云降噪算法对于提高点云数据的应用价值具有重要意义。
3、深度学习在点云降噪算法中主要应用于通过自学习降噪策略,自动识别并适应数据内部的复杂模式及噪声特征。在训练过程中,深度学习模型能够自动调整其参数,以最优方式适配数据特性和降噪需求,显著降低了对人工干预和先验知识的依赖。这种方法具备出色的自适应性、高精度、优秀的实时处理能力和良好的泛化能力。根据深度学习点云降噪处理框架的不同,将降噪方法分为基于pointnet的点云降噪网络、基于图卷积点云降噪网络和基于transformer的点云降噪网络。
4、基于pointnet的点云深度学习处理网络通过对单个点进行操作提取局部特征,但这种方法未能充分利用邻域的局部结构信息。基于图卷积的点云深度学习网络可以更有效地捕捉这种邻域局部结构,但是过多的图卷积层会导致参数量增加,从而增加网络训练的时间。而基于transformer的点云降噪网络,西北大学的xu等人提出了tdnet,该网络利用transformer对输入的噪声点云进行特征提取。tdnet在降噪过程中引入了一种自适应采样策略,旨在从噪声点云中选择出更接近于干净点云的点来进行表面重建,这种方法在某些情况下可能导致过度平滑的降噪效果。
技术实现思路
1、本发明针对现有技术存在的问题,提出了一种支路内支路间嵌套注意力3d点云降噪网络。本发明结合transformer在点云长距离依赖关系及全局信息捕获能力等方面的显著优势,在特征嵌入阶段采用改进的图卷积模块,为transformer提供更精细的特征输入,从而实现更好的点云降噪效果。
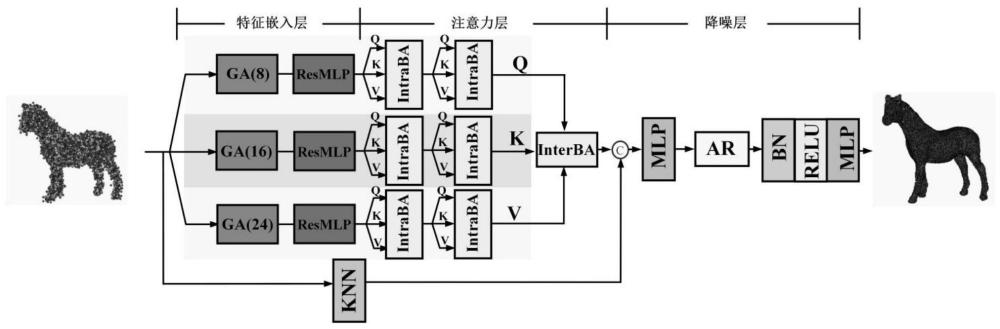
2、为了实现上述目的,本发明通过以下技术方案予以实现:支路内支路间嵌套注意力3d点云降噪网络,包括特征嵌入层、注意力层和降噪层3部分,特征嵌入层采用3分支结构,每个支路均由图注意力ga模块和残差多层感知机resmlp模块组成,通过将点云数据分配至3个不同支路实现了不同尺度特征的提取;
3、在注意力层中,将特征嵌入层中提取的不同尺度的特征送入支路内注意力intraba模块,进行两次注意力处理以对不同尺度特征进行特征增强,三个支路增强的特征分分别作为支路间注意力interba模块的q、k、v,通过注意力机制对不同尺度的特征进行特征融合得到支路间注意力特征;
4、在降噪层中,首先利用k最近邻分类算法为每个点寻找其k个最近邻点,将这k个最近邻点的坐标与支路间注意力特征进行通道拼接后作为聚合残差ar模块的输入,利用聚合残差ar模块进行点云降噪,然后将输出的结果进行归一化、卷积和激活处理,输出每个点与干净点云表面的预测偏移量,最后根据预测的偏移量调整噪声点云的位置完成降噪。
5、进一步的,所述图注意力ga模块以一个多层感知机mlp块开头,后接k最近邻分类knn模块,然后三个mlp块并行排列,其输出汇聚进行特征拼接,拼接后依次经过mlp块和lrelu激活函数,最终通过softmax函数进行归一化操作后输出,整个流程以一个特征更新fu块作为结束。
6、进一步的,所述残差多层感知机模块包括三组交替排布的多层感知机mlp块和relu激活函数结构,并在每组之间引入了残差连接,然后在最后加入maxpool函数。
7、进一步的,所述特征嵌入层的具体工作过程为:
8、设点云中有n个点:经过线性变换维度提升后,得到一组节点特征:然后利用k最近邻分类算法为每个点xi寻找其周围的k个最近邻点xi,j,逐步计算每个节点特征hi与它周围邻域节点特征hi,j之间的注意力系数ei,j;
9、ei,j=β·[whi·whi,j·w(hi-hi,j)],j∈ki (1)
10、其中w、β是可学习权重参数,在网络中使用mlp来逼近,[·]表示通道拼接的操作,ki代表节点xi周围的k个最近邻点xi,j的集合;
11、对注意力系数ei,j进行归一化操作得到ηi,j
12、
13、其中lrelu(·)表示leakyrelu激活函数,softmax(·)为归一化操作,exp表示以自然常数e为底的指数函数;
14、得到注意力系数后,对每个点xi的特征hi进行特征更新,得到每个点融合了邻域信息的新特征h′i,公式如下:
15、
16、得到每个点更新后的特征hi′后,采用残差多层感知机resmlp模块对hi′进行强化,得到特征嵌入层的输出特征hi″
17、fres(h)=[h·relu(mlp(h))] (4)
18、hi″=maxpooling(fres3(fres2(fres1(hi′)))) (5)
19、其中[·]表示通道拼接,fres(·)表示每个残差连接操作,mlp(·)表示对特征进行线性变换,relu(·)表示激活函数,maxpooling(·)表示最大池化函数。
20、进一步的,所述支路内注意力intraba模块以单一数据支路为输入,该输入并行地流向三个多层感知器mlp块,前两个mlp块的输出进行点积运算,再经由softmax函数处理,产生一个加权特征映射,此映射与第三个mlp块的输出再进行点积运算,得到的结果与原始输入特征进行差运算,差值通过一个进一步的mlp块处理,并通过激活函数进行调制,最终,这一调制后的输出与初始输入特征相结合,形成了更新后的特征输出。
21、进一步的,所述支路间注意力interba模块由三个输入支路和对应的三个mlp块组成,每个块处理各自的输入,其中,两个mlp块的输出相互进行点积运算,然后该结果通过softmax函数,softmax输出再与第三个mlp块的输出进行点积运算,通过一个额外的mlp和激活函数,最终,这个过程的输出与三个支路的输入结果相加,得到interba模块的最终输出。
22、进一步的,所述注意力层的具体工作过程:
23、各支路内注意力intraba模块将输入的特征经过线性变换得到3个特征向量q、k、v
24、(q,k,v)=h″(wq,wk,w)v,h″∈rn×d (6)
25、其中wv∈rd×d是可学习权重参数,h″是特征嵌入层的输出特征hi″的集合,n为点云中点的个数,d为点云特征的维度;
26、得到3个特征向量后,对查询矩阵q和关键矩阵k进行点积运算,得到注意力权重
27、
28、其中kt表示关键矩阵k的转置,
29、对权重进行归一化得到注意力权重a
30、
31、其中d表示点云中每个点的查询向量q和关键向量k的维度,ki为点云中节点xi周围k个最近邻点xi,j的集合,注意力权重a即为xi,j对xi中心点的重要性;
32、对注意力权重和值向量进行加权求和得到自注意力特征hsa
33、hsa=a·v (9)
34、将输入特征h″减去自注意力特征hsa,得到了偏移注意力特征;
35、最后得到支路内注意力特征hintra
36、hintra=relu(mlp(h″-hsa))+h″ (10)
37、其中mlp(·)为线性变换,relu(·)为激活函数;
38、第m个intraba模块输出的特征为经过2个intraba模块,各支路输出不同尺度的增强特征三支路增强特征经过线性变换分别作为interba模块的三个特征向量——q、k、v
39、
40、
41、
42、其中分别为三个支路输出特征的可学习权重参数,分别为尺度为8,16,24的支路输出的特征,将q与k的转置kt点乘,得到注意力权重
43、
44、对权重进行归一化得到支路间注意力权重a=(υ)i,j
45、
46、
47、其中d表示点云中每个点的查询向量q和关键向量k的维度,ki为点云中节点xi周围k个最近邻点xi,j的集合,将注意力权重a与v相乘后通过mlp与relu激活函数再与各支路内注意力特征相加得到支路间注意力特征hinter
48、
49、进一步的,所述聚合残差ar模块由4个聚合残差块arb组成,arb之间采用残差的连接方式,arb首先将输入特征按通道均匀划分为m个组,然后在每个分组内,依次执行2次归一化、激活和卷积操作,各分组处理后的结果再次进行通道拼接,然后与原始输入特征相加后输出结果。
50、进一步的,所述降噪层的具体工作过程如下:
51、注意力层输出的特征为hinter,hinter∈rn×d,xi点与周围k个最近邻点的坐标为xi,j,将hinter扩维后与xi,j通道拼接然后经过线性变换作为输入har,将har经过通道分割分为m个组,每个通道的输入特征维度为(d+3)/m,第i个组入的特征经过计算得到
52、
53、
54、其中mlp(·)操作为线性变换,bn(·)为归一化操作,relu(·)为激活函数,然后将各通道输出结果进行通道拼接得到hout,将hout与输入结果相加,再经过线性变换、归一化、激活模块最终得到每个点与干净点云表面的偏移量xv∈rn×3
55、
56、xv=relu(bn(mlp(hout+har))) (21)
57、其中[·]为通道拼接;
58、经过四个arb模块的不断修正,网络最终可以预测更为精确的每个噪声点的偏移量xv
59、
60、其中表示第i个arb模块对输入特征进行的操作。
61、进一步的,网络的损失函数为:
62、输入的噪声点云表示为无噪声点云表示为噪声点实际偏移量可以表示为s(x)=nn(x,y)-x,其中nn(x,y)表示y中离x最近的k个点,s(x)计算出从x到干净点云表面的实际偏移量,训练目标是最小化网络预测的噪声点偏移量与实际偏移量之间的差异;
63、
64、其中n(xi)是xi的邻域点,最终的训练目标£是每个点的偏移量的集合
65、
66、与现有技术相比,本发明的有益效果为:本发明在特征嵌入层中采用了图注意力模块,对领域点特征进行加权处理,有效地提取并强调关键点信息。而且在注意力层,设计了支路内、支路间嵌套的注意力模块。支路内注意力模块专注于捕捉各支路内部点云依赖关系,而支路间注意力模块致力于整合不同支路的信息,提取最适合的点云特征;同事在降噪层,设计了一个聚合残差模块,该模块结合残差连接和分组卷积技术,有效预测点云中每个点相对于干净点云表面的偏移量。通过采用分组卷积,该模块在保持计算效率的同时,实现了对点云噪声的精确预测。
67、本发明所提网络有效保留了点云的几何和拓扑信息,同时更好地保留点云细节信息,生成的点云在视觉上更加平滑,空洞也更少,在降噪误差分析中,经本发明降噪算法降噪后的点云和性能较高的scorenet算法降噪后的点云相比,平均倒角距离(chamferdistance,cd)和平均点到面距离(point-to-face distance,pfd)分别降低了7.6%和9.5%;在算法运行时间对比中,本章所提算法在提高降噪性能的同时,有效控制了时间复杂度。
本文地址:https://www.jishuxx.com/zhuanli/20240730/196826.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。