基于知识和数据双驱的可解释航班延误预测方法及系统
- 国知局
- 2024-07-31 23:21:30
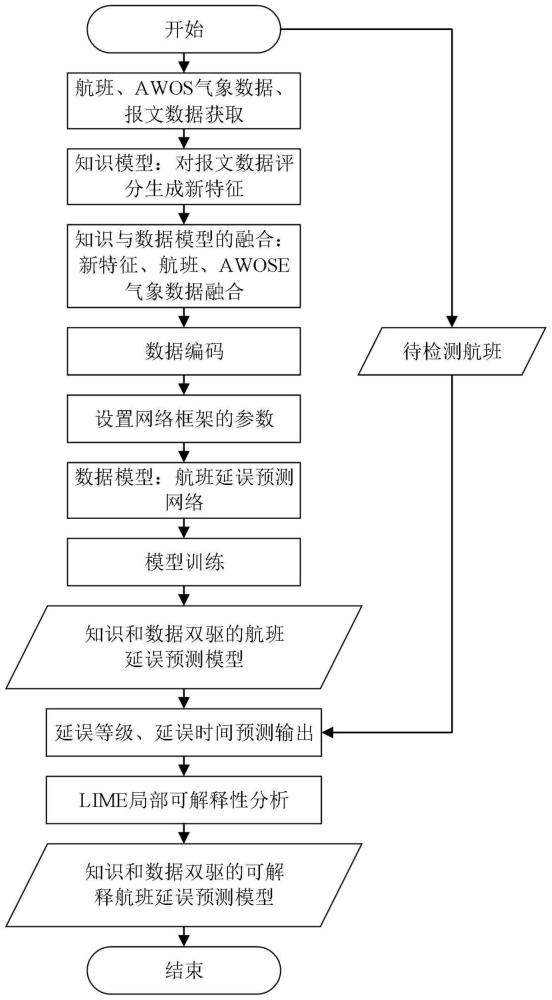
本发明属于交通延误预测,尤其涉及基于知识和数据双驱的可解释航班延误预测方法及系统。
背景技术:
1、航班延误率是衡量民航系统运行效率的一个重要指标,大面积航班延误对航班正常运行的影响是灾难性的。对航班延误进行准确的可解释的预报能够给管理者提供更多的决策依据,提前预估延误风险并制定相应的应对措施,从而能够有效的避免大面积航班延误的发生。民航是运行在无数规章下的有序的复杂的系统,决定航班能否按时起飞的因素是多方面的,但都是签派员、管制员以及机组结合规章与现实条件做出的决策。早期针对航班延误的研究,国内外学者使用统计分析等传统方法,但是预测准确率并不高。随着深度学习等人工智能技术的快速发展,深度神经网络也被应用在航班延误预测领域。与传统方法相比,深度学习等数据驱动方法准确率较高使其得到大规模的应用,但单纯使用数据驱动忽略了人类积累的经验知识并且作为一种黑箱模型完全不可解释,使其准确率结合知识有进一步提升空间的同时模型的可信性也需要进一步得到分析。
2、在知识与数据融合驱动方面,2016年张钹院士和朱军等人在《迈向第三代人工智能》文章中指出第三代人工智能的发展思路是把第一代知识驱动和第二代数据驱动结合起来,通过同时利用知识、数据、算法和算力四个要素构建更强大的ai;2022年清华大学朱小燕教授指出纯数据驱动的人工智能是具有不可解释性和不可理解的,深度学习的成功实际上是潜藏危机的。人类的智能的本质在于利用知识寻找事物的本质,知识驱动与数据驱动的人工智能可以把机器学习的隐式直觉与人凭借知识的常识判断进行有机结合;2022年潘云鹤院士和金哲等人提出在当前数据驱动的人工智能中引入先验假设、逻辑规则和方程公式等知识,建立数据和知识双轮驱动的人工智能方法;2022年胡珉等人将数据与知识驱动相结合的方法运用在土压平衡盾构结泥饼事件预警模型中,通过从历史数据中提取结泥饼事件规则,建立诊断知识库后结合综合概率法对数据模型预测结果的输出进行调整。相较于单一数据驱动方法,该模型能有效降低误报率,提升了工程效率;2022年马高等人基于领域知识通过机器学习算法和规范公式建立了与全灌浆套筒失效模式相关的新的特征参数,基于新的数据库训练数据模型后得到了更好的预测结果;2022年xiaofeng xu等人提出了一种基于知识修正数据模型预测结果的车辆轨迹预测方法。
3、在可解释性研究方面,2017年miller等人对可解释性的非数学定义是:可解释性是人类能够理解决策原因的程度。2016年kim等人定义可解释性是人类能够一致预测模型结果的程度。欧盟于2018年发布的“关于可信赖人工智能的伦理准则”初步形成了人工智能伦理准则的核心框架,指出可信人工智能是其能够进行广泛应用的必要条件,而可解释是可信的一种实现方式。常用的本身可解释的模型有线性回归、逻辑回归、决策树、rulefit、朴素贝叶斯和k近邻算法,这些模型分别适用于一些分类或者回归任务。可解释还有另外一种模型无关的方法,该方法将解释过程从预测模型中分离出来,在保留预测模型优势的同时提升预测结果的可解释性。模型无关的可解释研究主流方法有两种,分别是全局可解释方法和局部可解释方法。全局可解释常用的算法为shap,是一种起源于博弈论通过特征对最终结果的贡献来衡量特征重要性的方法。局部可解释常用算法为lime,由ribeiro于2016年提出,通过在局部训练可解释的代理模型来近似黑盒模型的预测结果,与全局可解释方法不同的是lime侧重于对个体预测结果的解释分析。2021年黄艺龙等使用lime对脓毒症使用机器学习模型预测结果进行可解释性分析,通过lime提取出对预测结果影响最大的前10个特征来对模型进行解释分析,提升了模型的可信度。
4、通过上述分析,现有技术存在的问题及缺陷为:现有技术中,忽略了航班运行中的专家知识数据库的判断,仅使用数据模型对航班延误进行预测;延误预测精度有待进一步提升;无法对数据模型的预测结果进行解释和分析,可解释性差。
技术实现思路
1、为克服相关技术中存在的问题,本发明公开实施例提供了基于知识和数据双驱的可解释航班延误预测方法及系统。
2、所述技术方案如下:基于知识和数据双驱的可解释航班延误预测方法,包括:
3、基于融合知识特征后的数据进行数据预处理、分割,获得训练集和测试集;将构建好的训练集输入设定初始参数,对航班延误预测网络进行训练,得到基于知识和数据双驱的航班延误预测模型;
4、将待预测的航班、awose气象及对应的报文数据进行知识评分、数据融合及预处理,输入到所述基于知识和数据双驱的航班延误预测模型,通过设定好参数后的航班延误预测网络对待预测数据进行特征提取;
5、提取后的特征同时通过多任务层并列的回归预测结构和分类预测结构实现回归任务预测和分类任务预测,回归任务和分类任务的输出分别为延误时间和分属于每个类别的概率,基于所述的分属于每个类别的概率得到待预测航班的延误类别;
6、使用lime对训练好的基于知识和数据双驱的航班延误预测网络进行分析,得到基于知识和数据双驱的可解释航班延误预测模型,输入单条数据进行预测,得到该模型对分类和回归预测结果起主要影响作用的特征,实现模型的可解释性分析。
7、进一步,基于融合知识特征后的数据进行数据预处理、分割前,需进行:
8、根据专家知识数据库对获取的报文数据进行评分;
9、将评分与航班数据、awose气象数据进行融合生成新数据集,实现知识模型与数据模型的联合驱动;
10、设定航班延误预测网络的初始参数以及训练方式的初始参数。
11、进一步,所述专家知识数据库包括:能见度和云底高的评分规则、风的评分规则、降水的评分规则、结冰状况的评分规则和危险天气现象的评分规则;
12、所述实现知识模型与数据模型的联合驱动包括:针对各机场起飞航班使用航班数据中的计划起飞时间和本机场的awose气象数据记录时间以及本机场的报文发布时间进行匹配融合;针对各机场降落航班使用航班数据中的计划降落时间和目的机场的awose气象数据记录时间以及目的机场的报文发布时间进行匹配融合;通过融合航班数据、awose气象数据和知识评分数据后形成新的数据集,实现知识模型和数据模型的联合驱动;
13、所述航班延误预测网络使用多任务nr-densenet网络,多任务nr-densenet网络的初始参数包括:block个数、每个block的全连接层个数、分别用于分类和回归任务的多任务层的结构以及输入数据的特征维度;训练方式的初始参数包括:训练时的学习率、训练时的优化器、训练时分别用于回归任务和分类任务的损失函数、训练时多任务层中回归任务和分类任务的损失权重分配比例。
14、进一步,所述基于融合知识特征后的数据进行数据预处理、分割,包括:数据清洗、数据标注和数据编码;
15、在数据清洗中,采用直接删除的方式对缺失的数据和含有异常项的数据删除;采用近似项填充的方式对航班中存在缺失值的数据填充;
16、在数据标注中,针对起飞或降落航班进行处理,根据计算的起飞或降落延误时间作为航班延误预测网络的回归任务标签,对延误时间按照时间范围进行延误等级划分,作为航班延误预测网络的分类任务标签;
17、在数据编码中,针对连续型和离散型特征进行处理,对连续型特征使用min-max编码,对于离散型特征使用catboost编码。
18、进一步,所述将构建好的训练集输入设定初始参数,对航班延误预测网络进行训练,得到基于知识和数据双驱的航班延误预测模型,包括:
19、将训练集按照批次依次送到航班延误预测网络进行特征提取,将提取后的特征输入到多任务层中的回归层进行回归预测,回归层使用linear激活函数得到延误预测时间,通过均方误差损失函数进行损失计算后获得回归任务的损失值;分类层使用softmax激活函数得到每个等级的预测值,通过交叉熵损失函数进行损失计算后获得分类任务的损失值;通过设定的分类损失和回归损失的比例计算出总损失后进行迭代完成训练,得到基于知识和数据双驱的航班延误预测模型;
20、通过设定的分类损失和回归损失的比例计算出总损失,包括:
21、回归任务的均方误差损失函数公式为:
22、
23、式中,mse为回归任务的均方误差损失函数,m为样本个数,y(xi)为第i个样本的真实延误时间标签,为第i个样本的预测延误时间;
24、分类任务的交叉熵损失函数公式为:
25、
26、式中,h为分类任务的交叉熵损失函数,i为航班延误等级个数,q(xi)为第x个样本第i个类别的真实标签,log项用于惩罚远离真实标签的预测概率,xi为第x个样本第i个类别,为第x个样本第i个类别的预测概率;
27、总损失函数的公式为:
28、loss=rmsemse+rhh
29、式中,loss为多任务模型的总损失函数,rmse为分配的回归任务的损失权重,rh为分配的分类任务的损失权重,h为分类任务的交叉熵损失函数。
30、进一步,所述通过设定好参数后的航班延误预测网络对待预测数据进行特征提取,包括:通过密集连接将构建块串联起来实现特征的重用,并将densenet中的卷积层和池化层替换为构建块里面的全连接层。
31、进一步,所述多任务层并列的回归预测结构采用linear激活函数,直接输出航班延误的预测时间;
32、所述分类预测结构采用softmax激活函数,将航班延误情况分为五类,通过softmax激活函数为每个输出分类的结果都赋予一个概率值,表示属于每个类别的可能性;然后将最大概率的等级标签作为最终的预测结果。
33、进一步,所述使用lime对训练好的基于知识和数据双驱的航班延误预测网络进行分析,包括:使用lime作为局部可解释性分析算法,分析数据模型特征重要性,lime求解最优化的问题,计算公式为:
34、
35、
36、式中,ξ(x)为最优化总损失函数,l(f,g,πx)为衡量在x生成的新数据集πx范围内,可解释模型g(zi)逼近数据模型f(zi)的程度;ω(g)为可解释模型g的复杂度与可解释性的相对度量关系,g为可解释模型的集合,g为可解释模型中的一个,为生成的数据个数πx数据集内的数据个数,πx(zi)为由x生成的数据向量zi与原向量x的距离度量,f(zi)为数据模型,g(zi)为可解释模型,f为待解释的数据模型。
37、进一步,将lime与多任务模型相结合,使lime同时分析多任务模型中的回归和分类预测模型;针对分类任务设置lime使用多分类logistic回归可解释模型,针对回归任务设置lime使用线性回归可解释模型。
38、本发明的另一目的在于提供一种基于知识和数据双驱的可解释航班延误预测系统,该系统实施所述的基于知识和数据双驱的可解释航班延误预测方法,该系统包括:
39、数据获取模块,获取机场报文数据以及获取局方提供的航班和awose气象数据;
40、知识提取模块,根据专家知识数据库对报文数据进行评分;
41、融合驱动模块,融合知识处理后的评分数据、航班数据和awose气象数据构建新的数据集;
42、数据预处理模块,将构建的新数据集进行数据清洗、数据标注和数据编码工作,构建融合知识后的可送入数据模型进行训练的数据集;
43、数据模型训练模块,设定航班延误预测网络初始参数并将融合知识后的新数据集输入航班延误预测网络进行训练,得到基于知识和数据双驱的航班延误预测模型;
44、预测结果获取模块,通过多任务层中的分类任务层获取待预测航班分别属于各类别的预测概率,进而取概率最大的延误等级作为预测结果,预测航班延误类别信息,通过多任务层中的回归任务层获取待预测航班的延误时间;
45、可解释性分析模块,使用lime对多任务模型同时进行回归和分类结果的可解释分析,得到基于知识和数据双驱的可解释航班延误预测模型
46、结合上述的所有技术方案,本发明所具备的优点及积极效果为:本发明首先根据专家知识数据库对获取的报文数据进行评分;将评分与航班数据、awose气象数据进行融合生成新数据集,实现知识模型与数据模型的联合驱动;设定航班延误预测网络的初始参数以及训练方式的初始参数;对融合知识特征后的数据进行数据清洗、数据标注和数据编码,并将数据按照8:2的比例分割成训练集和测试集;将构建好的训练集输入设定参数后的航班延误预测网络进行训练,得到基于知识和数据双驱的航班延误预测模型;将待预测的航班、awose气象及对应的报文数据进行知识评分、数据融合及预处理后输入到基于知识和数据双驱的航班延误预测模型,通过设定好参数后的航班延误预测网络对待预测数据进行特征提取;提取后的特征同时通过多任务层并列的回归预测结构和分类预测结构实现回归任务预测和分类任务预测,回归任务和分类任务的输出分别为延误时间和分属于每个类别的概率。
47、本发明基于所述的分属于每个类别的概率可以得到待预测航班的延误类别,使用lime对训练好的基于知识和数据双驱的航班延误预测网络进行分析,得到基于知识和数据双驱的可解释航班延误预测模型,输入单条数据进行预测后得到该模型对分类和回归预测结果起主要影响作用的特征,实现模型的可解释性分析,增强了数据模型的可解释性。
48、本发明对航班延误预测具有较高的预测性能,在某国际机场相较于不添加知识模型处理的特征,回归任务平均mse降低了17.2%,平均mae降低了23.6%,分类任务准确率比原模型提升了2.2%。
本文地址:https://www.jishuxx.com/zhuanli/20240730/197184.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表