一种基于加权采样数据集蒸馏的Non-IID联邦学习方法
- 国知局
- 2024-07-31 23:21:58
本发明涉及人工智能的,具体而言,尤其涉及一种基于加权采样数据集蒸馏的non-iid联邦学习方法。
背景技术:
1、在联邦学习中,由于不同客户端收集的数据来源不同,信息描述各异,并且使用不同设备进行数据收集,来自不同客户端的数据样本往往呈现不同的分布特征或相关性。由于这种异质性,从相同初始模型训练的本地模型往往会朝着不同的梯度方向进行优化。在梯度交换的联邦学习中,这种异质数据产生的梯度会严重影响聚合模型的收敛性。
2、现有的算法一般通过个性化联邦,将具有相似数据集的本地模型一起聚合,或者通过知识蒸馏让本地模型学习到全局的知识。同时,也有一些算法使用数据生成来弥补病态分布的数据集。
3、联邦蒸馏算法(fd)[1]于2018年首次提出。因为fedavg算法需要在每个全局轮次传输全局模型的参数,这会造成很大的沟通压力。fd中客户端提供在公共数据集上各自预测的分数,然后将来自各客户端的平均分作为老师的知识进行蒸馏。[2]提出了一种利用本地知识对全局模型进行微调的新方法。它不需要全局数据集,利用本地知识获得数据生成器,以进行知识蒸馏。为了防止遗忘本地知识以外的知识,g lee等[3]通过全局模型基于本地数据的负向标签对本地模型进行知识蒸馏从而使本地不会偏离全局模型太远。
4、[4]提出了私有fl-gan,这是一种基于联邦学习的差分隐私gan。通过将lipschitz条件与差分隐私敏感度进行战略性结合,他们的模型可以生成高质量的合成数据,而不会牺牲训练数据的隐私性。这种解决方案可以解决联邦学习中数据不足的问题,特别是在非独立同分布场景下。然而,由于gan模型获得的数据是无标签的,因此它们尚不能作为监督式联邦学习中高质量的带标签数据集。[5]提出了fedboosting方法,该方法通过考虑本地客户端的数据多样性来解决联邦学习中的权重发散和梯度泄漏问题,并提出了一种基于差分隐私的线性聚合方法,使用同态加密来解决潜在的数据泄漏风险。
5、但是,现有算法基本上都是通过巧妙的设计来弥补梯度聚合类联邦学习的弊端。不能从根本解决数据非独立同分布带来的联邦学习的收敛性问题。
6、此外,还有几种策略用于解决非独立同分布(non-iid)问题。[6]提出了一种适用于个性化联邦学习的解决方案,称为flkd(具有知识蒸馏的联邦学习),其中知识传递通过全局模型进行,并且客户端可以通过相互学习定制本地模型,从而提供了对抗梯度泄漏攻击的自然防御。为了解决联邦学习中的非独立同分布数据问题,[7]提出了一种联邦模型组件自注意机制(fedmcsa),以实现完全个性化的联邦适应以更新模型。该机制通过利用模型组件的自注意力,促进了不同客户端之间在细粒度上的合作,增强了类似模型组件之间的合作,同时减少了具有显著差异的组件之间的干扰。
7、[1]e.jeong,s.oh,h.kim,j.park,m.bennis,s.-l.kim,communication-efficient on-device machine learning:federated distillation and augmentationunder non-iid private data,arxiv preprint arxiv:1811.11479(2018).[2]l.zhang,l.shen,l.ding,d.tao,l.-y.duan,fine-tuning global model via data-freeknowledge distillation for non-iid federated learning,in:proceedings of theieee/cvf conference on computer vision and pattern recognition,2022,pp.10174–10183.
8、[3]g.lee,m.jeong,y.shin,s.bae,s.-y.yun,preservation of the globalknowledge by not-true distillation in federated learning,arxiv preprintarxiv:2106.03097(2021).
9、[4]b.xin,y.geng,t.hu,s.chen,w.yang,s.wang,l.huang,federated syntheticdata generation with differential privacy,neurocomputing 468(2022)1–10.
10、[5]h.ren,j.deng,x.xie,x.ma,y.wang,fedboosting:federated learning withgradient protected boosting for text recognition,neurocomputing569(2024)127126.
11、[6]f.yu,l.wang,b.zeng,k.zhao,r.yu,personalized and privacy-enhancedfederated learning framework via knowledge distillation,neurocomputing 575(2024)127290.
12、[7]q.guo,y.qi,s.qi,d.wu,q.li,fedmcsa:personalized federated learningvia model components self-attention,neurocomputing 560(2023)126831.
技术实现思路
1、根据上述背景技术提到的技术问题,而提供一种基于加权采样数据集蒸馏的non-iid联邦学习方法。
2、本发明采用的技术手段如下:
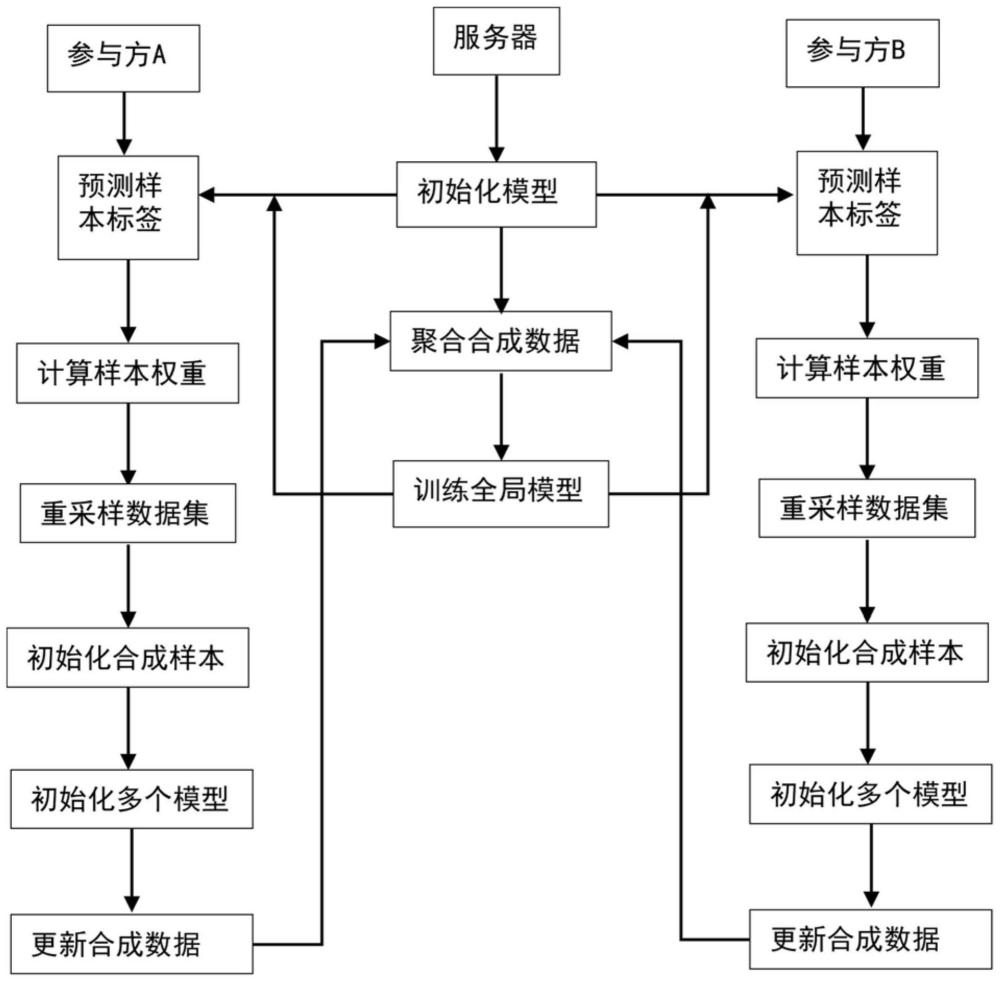
3、一种基于加权采样数据集蒸馏的non-iid联邦学习方法,包括以下步骤:
4、步骤1:假设有m个参与方,且每个参与方拥有的数据xk,∈(1.m)互不重复,设置第k个客户端拥有的标签类别为yk,不同的客户端的数据不满足独立同分布条件;
5、步骤2:假设每轮选择客户端有s个,进行本地数据集蒸馏;
6、步骤3:对所述步骤2蒸馏后的数据集进行全局服务器训练。
7、进一步地,所述步骤2中,所述本地数据集蒸馏包括以下步骤:
8、步骤21:服务器任意选定几个参与方,所述参与方的客户端从服务器下载全局模型;
9、步骤22:在客户端k上,基于全局模型,计算得到不同本地数据的预测;
10、步骤23:为了使在整体数据集上展现出比随机输出更好的模型收敛,增加损失函数,使得损失函数有收敛到0的趋势;
11、步骤24:根据得到的结果fx计算每个样本的权重,使全体数据集的损失收敛,则样本权重更新参数可以设计为:
12、
13、将得到的权重进行归一化后作为重采样时每个样本的概率;
14、步骤25:通过欠采样对样本进行处理,即采样后样本集大小n<count(k);
15、步骤26:数据集蒸馏过程基于分布匹配进行训练。
16、进一步地,所述步骤22中,本地基于全局模型对每个样本xk预测结果px与其样本标签y,得到如下结果:
17、
18、其中,fx表示概率预测模型;px表示预测最大可能概率;y表示样本标签。
19、进一步地,所述损失函数为
20、
21、其中,表示预测对的损失,表示预测错的损失。
22、进一步地,表示客户端上的一个与全局模型相同结构的初始化模型,通过数据集蒸馏,最小化以下损失函数:
23、
24、即在本地基于相同初始化模型使用合成数据集训练得到的和使用原始数据集训练得到的可以在相同的数据集上得到相似的损失;
25、所述数据集蒸馏算法包括:内层循环和外层循环;在外层循环中,首先初始化一个模型队列
26、
27、其中,表示客户端上初始化模型;是模型队列包含有多个不同初始化值的相同结构的模型;然后随机选定一个模型,并进入内层循环;在内层循环中,计算合成数据集和原始数据集在选定模型上的损失
28、
29、损失函数包括两个部分,分别在特征提取层其中表示mse损失;表示分类器的输出层,为交叉熵损失,将合成数据与原始数据对齐;并在保持模型参数不变的基础上使用损失函数更新合成数据集,此处内层循环结束;然后继续外层循环;将选定的模型在原始数据集上更新若干轮次,并保存在模型队列中;在一定轮次外层循环结束后,向模型队列中压入新的初始化模型,当模型队列超过队列的容量上限n时,将最先压入的模型依次释放;通过多次循环,得到本地合成数据集
30、进一步地,在本地客户端上得到合成数据集后,将合成数据上传到服务器,服务器基于临近多轮获得的合成数据,构建一个基于合成“假”数据的带标签的近似满足独立同分布条件的全局数据集:
31、
32、通过不断的本地和服务器进行通信,可以使全局模型不断被训练,直至收敛。
33、较现有技术相比,本发明具有以下优点:
34、本发明适用于极端non-iid的联邦学习。本算法解决了联邦学习中极端非独立同分布引起的收敛通信轮次过多和低精度等问题。此外,我们的算法架构使得联邦学习可以依赖最少甚至仅有一个客户端在单个通信轮次中参与训练。这种对异步性的极大适应性进一步扩展了联邦学习的适用范围。同时,由于本算法不再需要上传模型参数到服务器,因此在一定程度上有潜力可以减少通信的压力。
本文地址:https://www.jishuxx.com/zhuanli/20240730/197216.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。