一种医疗领域中全量数据的差异比对方法和装置与流程
- 国知局
- 2024-07-31 23:23:25
本发明属于医疗数据处理,具体涉及一种医疗领域中全量数据的差异比对方法和装置。
背景技术:
1、现有医疗机构内网部署应用的his(hospital information system,医院信息系统)、pass(prescription automatic screening system,合理用药监测系统)等系统,通过oracle、sqlserver、mysql等数据库来存储产生的医疗数据。
2、随着数据融合、数据应用、人工智能等方向的发展,面临着向不同省市医疗机构进行数据采集、分析、以及应用等需求。由于医疗机构采用内网部署系统,会造成外网无法访问,这样采集医疗结构内医疗数据面临网络上的限制、数据安全、不泄露、采集数据过程中不能影响系统日常使用等限制,使得数据采集面临各种挑战。现有数据采集技术中,将主数据库中的医疗全量数据快照备份到备份数据库,通过jdbc(jave database connectivity,api)程序访问数据库的标准接口从备份数据库中读取全量数据以导出到csv文件形式并保存,然后csv文件通过医疗机构开通的专门网络通道传输到卫健局专网服务器上。
3、由于很多区域医疗机构的his、pass系统都是内部局域网部署,全量数据采集只能通过备份文件的形式,然后再传输到卫健局专网服务器,多次重复以上全量数据采集动作,如何找出多次采集的全量数据变更(新增、删除、修改),变得非常重要。
4、目前常用的解决方案为:将当前的全量数据和前一天的全量数据分别存储,存到两个csv文件,并将两个csv文件读取到两个数组中,然后进行比较,比较手段包括:(1)基于diffutils.diff()计算差异,且在实际应用中可能需要考虑csv文件的具体内容和格式来定制化比较;(2)手动循环遍历两个数组,具体手动比较数据中的每个元素,这种方式简单但效率较低、适合数据量少的情况,当遇到海量数据时则该比较手段直接被放弃掉;(3)采用java 8中流式api调用方法,即list.stream().filter(i->list.contains(i)).collect(collectors.tolist()),对应解释为:从list集合中创建一个流(javadevelopment kit 8引入的新特性),然后通过过滤器filter获取那些在另一个集合list中也存在的元素,最后把过滤后的元素放到新的集合list中。
5、以上常用解决方案存在极大弊端,包括:当一个数据表中存在千万级别数据并以单张csv文件的形式导出,这样在进行比较时加载存有千万级别数的csv文件会容易引起程序服务资源的内存爆满,且循环比对产生对(o)n的时间复杂度,cpu疯狂计算会导致cpu持续飙升。
技术实现思路
1、鉴于上述,本发明的目的是提供一种医疗领域中全量数据的差异比对方法和装置,对全量数据进行分片存储后再进行差异比对,以避免加载数据时出现程序的内存和cpu占满。
2、为实现上述发明目的,实施例提供的一种医疗领域中全量数据的差异比对方法,包括以下步骤:
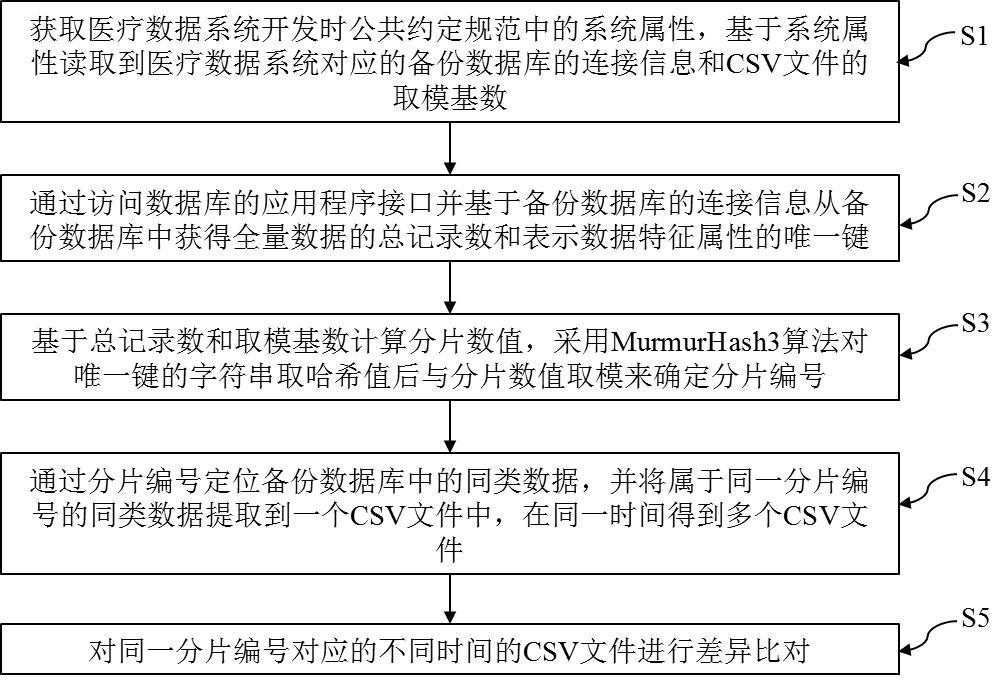
3、获取医疗数据系统开发时公共约定规范中的系统属性,基于系统属性读取到医疗数据系统对应的备份数据库的连接信息和csv文件的取模基数;
4、通过访问数据库的应用程序接口并基于备份数据库的连接信息从备份数据库中获得全量数据的总记录数和表示数据特征属性的唯一键;
5、基于总记录数和取模基数计算分片数值,采用murmurhash3算法对唯一键的字符串取哈希值后与分片数值取模来确定分片编号;
6、通过分片编号定位备份数据库中的同类数据,并将属于同一分片编号的同类数据提取到一个csv文件中,在同一时间得到多个csv文件;
7、对同一分片编号对应的不同时间的csv文件进行差异比对。
8、优选地,所述方法还包括:当同一时间得到的多个csv文件之间的数据量差异超过设定阈值时,选择数据量大的csv文件进行二次划分,包括:
9、提取数据量大的csv文件中的另一总记录数,并对另一总记录数进行基于murmurhash3算法的哈希计算后,将哈希值与自定义的二次分片数值取模来确定二次分片编号,通过二次分片编号定位备份数据库中的同类数据,并将属于同一二分片编号的同类数据提取到一个csv文件中,这样实现将数据量大的csv文件二次划分成多个csv文件。
10、优选地,所述方法还包括:将第一次得到的哈希值再次进行murmurhash3计算,得到第二次计算的哈希值,并将第二次计算的哈希值与分片数值取模来确定分片编号。
11、优选地,所述方法还包括:采用一致性哈希算法,将每个分片对应的哈希值按照顺序映射到哈希环对应的节点上,当增加分片或减少分片时,从哈希环上确定增加分片或减少分片对应的2个相关分片,并重新移动2个相关分片对应的数据,依据移动后的数据重新计算对应的哈希值并调整分片编号;
12、其中,增加分片时对应的2个相关分片是指与增加分片相邻的2个分片,此时重新移动的2个相关分片对应的数据为相邻2个分片的数据;
13、减少分片时对应的2个相关分片是指与减少分片相邻的2个分片,此时重新移动的2个相关分片对应的数据为减少分片的数据,和相邻2个分片的数据。
14、优选地,所述方法还包括:采用时间范围分片算法,将表示数据特征属性的唯一键中某个时间字段作为分片字段,设置时间分片下界值和时间分片上界值,并依据设置的分片数值、时间分片下界值、以及时间分片上界值自定义组装sql查询语句,通过执行sql查询语句获取数据并写入分片编号对应的csv文件中。
15、优选地,基于系统属性从医疗数据系统对应的备份数据库中读取备份数据库的连接信息和csv文件的取模基数外,还读取用户名、密码、数据库类类型、以及csv文件存储路径。
16、优选地,当医疗数据系统采用spring框架开发时,获取医疗数据系统开发时公共约定规范中的系统属性,包括:
17、启动java应用程序从main函数方法入口加载公共约定规范spring.properties文件,基于propertiesconfiguration对象从spring.properties文件中读取系统属性并存储到map数据结构对象中,其中,系统属性通过k-v键值对方式存储;
18、所述通过访问数据库的应用程序接口采用在main函数方法体内加入的jdbc api接口,基于备份数据库的连接信息通过执行sql语句从备份数据库中获得全量数据的总记录数和表示数据特征属性的唯一键。
19、优选地,对同一分片编号对应的不同时间的csv文件进行差异比对,包括:
20、针对同一分片编号对应的不同时间的两个csv文件,首先读取文件内容摘要,并将文件内容摘要对应的字符串进行表示方式转换后,计算字符串的信息摘要值,当两csv文件对应的信息摘要值相等时,则认为两csv文件无差异。
21、优选地,对同一分片编号对应的不同时间的csv文件进行差异比对,还包括:
22、当两csv文件对应的信息摘要值不相等时,则认为两csv文件存在差异,并进行数据比对,包括:分别读取两csv文件中的具体数据存储到两数组中,并基于两数组进行数据的差异比对,得到差异结果。
23、为实现上述发明目的,本发明实施例还提供了一种医疗领域中全量数据的差异比对装置,包括:
24、第一获取模块,其用于获取医疗数据系统开发时公共约定规范中的系统属性,基于系统属性读取到医疗数据系统对应的备份数据库的连接信息和csv文件的取模基数;
25、第二获取模块,其用于通过访问数据库的应用程序接口并基于备份数据库的连接信息从备份数据库中获得全量数据的总记录数和表示数据特征属性的唯一键;
26、分片编号确定模块,其用于基于总记录数和取模基数计算分片数值,采用murmurhash3算法对唯一键的字符串取哈希值后与分片数值取模来确定分片编号;
27、分片获取模块,其用于通过分片编号定位备份数据库中的同类数据,并将属于同一分片编号的同类数据提取到一个csv文件中,在同一时间得到多个csv文件;
28、差异比对模块,其用于对同一分片编号对应的不同时间的csv文件进行差异比对。
29、为实现上述发明目的,本发明实施例还提供了一种计算设备,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述一个或多个处理器执行所述可执行代码时,用于实现上述医疗领域中全量数据的差异比对方法。
30、为实现上述发明目的,本发明实施例还提供了一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,实现上述医疗领域中全量数据的差异比对方法。
31、与现有技术相比,本发明具有的有益效果至少包括:
32、本发明基于表示数据特征属性的唯一键的字符串,并采用murmurhash3算法和基于分片数值的取模计算来确定分片编号,基于分片编号将备份数据库中的全量数据进行分片切分,能将大数据表的全量数据切分后存放到多个csv文件,达到文件加载程序的内存、cpu不至于直接拉满,进而导致程序进程卡顿,本发明可支持应用于数据的全量采集、数据的变更差异比对、数据分析等应用领域。
本文地址:https://www.jishuxx.com/zhuanli/20240730/197327.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表