基于多模态知识图谱与大语言模型的视觉问答系统的制作方法
- 国知局
- 2024-07-31 23:25:12
本发明属于人工智能自然语言处理领域,具体是指基于多模态知识图谱与大语言模型的视觉问答系统。
背景技术:
1、随着数字化时代发展,信息爆炸式增长,人们对于快速准确获取专业领域知识的需求日益增长,大语言模型作为一种预训练的语言生成模型,可降低某些专业邻域问答系统的开发成本,进行自然语言问题的粗粒度解析。
2、然而大语言模型在进行推理、判断时存在局限,不能给出问题的准确答案,于是利用多模态知识图谱进行优化。多模态知识图谱可有效自然文本和图像等多模态信息,再结合模式层关系细粒度解析问题,提高大模型生成答案的准确性。
3、为此,提出基于多模态知识图谱与大语言模型的视觉问答系统。将知识图谱中的实体和关系嵌入到大模型的向量空间中,作为大模型的输入之一,从而使大模型能够利用知识图谱中的信息进行推理和推断。
技术实现思路
1、本发明的目的在于提供基于多模态知识图谱与大语言模型的视觉问答系统,以解决上述背景技术中提出的问题。
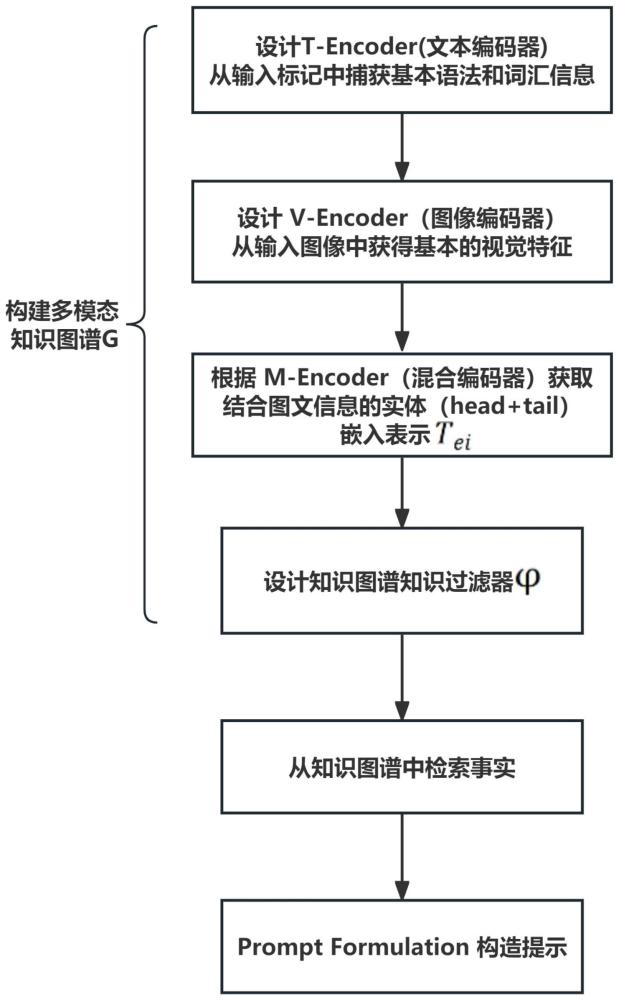
2、为实现上述目的,本发明提供如下技术方案:基于多模态知识图谱与大语言模型的视觉问答系统,包括以下步骤:
3、s1、设计t-encoder(文本编码器)从输入标记中捕获基本语法和词汇信息。
4、s2、设计v-encoder(图像编码器),从输入图像中获得基本语法和词汇信息。
5、s3、根据m-encoder(混合编码器)获取结合图文信息的实体(head+tail)嵌入表示tei。
6、s4、设计知识图谱过滤器φ,应用多个过滤规则,避免任何缺乏可恢复意义的事实被添加到g,以减少t-encoder,v-encoder和m-encoder在提取信息时产生的任何错误,完成多模态知识图谱构建。
7、s5、从知识图谱中检索事实,按照问题回答和故事完成这两个指标,检索在知识图谱g中与任务t最相关的前三个事实。
8、s6、promptformulation(提示构造),使用gpt-3与少量样本学习来将提取的事实表述为自然语言,并将它们融入到一个大型语言模型的提示中。
9、其中,所述s1,构建t-encoder(文本编码器),将lt层作为文本编码器,它也由mha和ffn模块的lt层组成,类似于ln出现在mha和ffn之后的视觉编码器。具体来说,是将一个目标序列{w1,…,w2}嵌入到指定矩阵中,文本表示计算如下:
10、
11、
12、
13、其中,为输出文本序列l层的隐藏状态。
14、其中,所述s2,设计v-encoder(图像编码器),从输入图像中获得基本语法和词汇信息。采用预训练好的第一个lv层作为视觉编码器来提取图像特征,将每幅图像重新缩放为统一的h*w像素进行合并投影,将得到的视觉序列嵌入矩阵。有以下计算公式:
15、
16、
17、
18、其中,为视觉编码器l层的隐藏状态。
19、其中,所述s3,根据m-encoder获取获取结合图文信息的实体(head+tail)嵌入表示tei。多模态kgc主要面临着不同模式之间的异质性和不相关性问题。与之前利用额外的共同注意层来整合模态信息的作品不同,我们提出通过多层次融合对vit和bert最后的lm层的多模态特征进行建模,即lm编码器。具体来说,我们在自注意块上提出了一个前缀引导的交互模块(pgi),以预先减少模态的异质性。我们还在ffn层中提出了一个相关感知融合模块(caf),以减少无关图像元素对噪声的影响。具体计算公式如下:
20、
21、
22、
23、
24、其中,所述s4,设计知识图谱过滤器φ,使用worldnet的nlet接口确定每个事实中单词的词性。应用以下过滤规则:(1)tail与head相同;(2)head中不包含名词;(3)tail的第一个单词与relation的最后一个单词相同;(4)head或tail以代词或连词开头;(5)事实[head,relation,tail]中不含动词,符合上述规则的事实将不会被加入g,以避免任何缺乏可恢复意义的事实被添加到g。至此,多模态知识图谱被构建。
25、其中,所述s5,从知识图谱中检索事实,按照问题回答这一指标,检索特定故事实体中的离散信息,利用知识图谱g中的事实f与问题t之间的字符编辑距离确定相关性,与问题回答最相关的事实f被定义为:
26、
27、其中lev代表levenshtein距离函数,任务t为问题。
28、仅从g中选择前三个最相关的事实f,更多的事实f对整体系统性能产生的变化可忽略不计。
29、从知识图谱中检索事实,按照故事完成这一指标,使用sentence-bert(sbert)生成有助于语义比较的嵌入确认语义相关性,知识图谱g中的每个事实f与故事最新段落t的sbert嵌入存在余弦相似度,与故事完成最相关的事实f被定义为:
30、
31、其中cos代表余弦相似度函数,sb代表sbert嵌入模型的应用,任务t为故事的最新段落。
32、仅从g中选择前三个最相关的事实f,更多的事实f对整体系统性能产生的变化可忽略不计。
33、其中,所述s6,使用gpt-3与少量样本学习来将提取的事实表述为自然语言,并将它们融入到一个大型语言模型的提示中。我们使用下图所示的提示来促使gpt-3生成格式正确的句子。[facthead]、[factrelation]和[facttail]将被替换为正在表述的知识图谱事实的三个组成部分。
34、
35、与现有技术相比,本发明的有益效果是:
36、1、本发明包含文档特定信息的动态知识边缘图可以增强大型语言模型的提示生成,从而减轻了基于转换器的语言模型所使用的有限上下文长度的限制。
37、2、本发明构建的多模态知识图谱可有效处理自然文本和图像等多模态信息,再结合模式层关系细粒度解析问题,提高大模型生成答案的准确性。
38、3、本发明我们用gpt-3与少量样本学习来将提取的事实表述为自然语言,对提示形成方法进行了广泛改进。
技术特征:1.基于多模态知识图谱与大语言模型的视觉问答系统,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于多模态知识图谱与大语言模型的视觉问答系统,其特征在于:所述s1,设计t-encoder(文本编码器)从输入标记中捕获基本语法和词汇信息。构建视觉编码器,将第一个lt层作为文本编码器,通过相关计算让其呈现出预想效果。
3.根据权利要求1所述的基于多模态知识图谱与大语言模型的视觉问答系统,其特征在于:所述s2,设计v-encoder(图像编码器),从输入图像中获得基本语法和词汇信息。采用预训练好的第一个lv层作为视觉编码器来提取图像特征,将每幅图像重新缩放为统一的h*w像素进行合并投影,将得到的视觉序列嵌入矩阵。
4.根据权利要求1所述的基于多模态知识图谱与大语言模型的视觉问答系统,其特征在于:所述s3,根据m-encoder(混合编码器)获取结合图文信息的实体(head+tail)嵌入表示tei。与以往利用额外的共同注意层来整合模态信息的工作不同,我们提出通过多层次融合对vit和bert最后的lm层的多模态特征进行建模,即lm编码器。
5.根据权利要求1所述的基于多模态知识图谱与大语言模型的视觉问答系统,其特征在于:所述s4,设计知识图谱过滤器φ,使用worldnet的nlet接口确定每个事实中单词的词性。应用以下过滤规则:(1)tail与head相同;(2)head中不包含名词;(3)tail的第一个单词与relation的最后一个单词相同;(4)head或tail以代词或连词开头;(5)事实[head,relation,tail]中不含动词,符合上述规则的事实将不会被加入g,以避免任何缺乏可恢复意义的事实被添加到g。至此,多模态知识图谱被构建。
6.根据权利要求1所述的基于多模型知识图谱与大语言模型的视觉问答系统,其特征在于:所述s5,从知识图谱中检索事实,按照问题回答这一指标,检索特定故事实体中的离散信息,利用知识图谱g中的事实f与问题t之间的字符编辑距离确定相关性,与问题回答最相关的事实f被定义为:
7.根据权利要求1所述的基于多模态知识图谱与大语言模型的视觉问答系统,其特征在于:所述s5,从知识图谱中检索事实,按照故事完成这一指标,使用sentence-bert(sbert)生成有助于语义比较的嵌入确认语义相关性,知识图谱g中的每个事实f与故事最新段落t的sbert嵌入存在余弦相似度,与故事完成最相关的事实f被定义为:
8.根据权利要求1所述的基于多模态知识图谱与大语言模型的视觉问答系统,其特征在于:所述s6,使用gpt-3与少量样本学习来将提取的事实表述为自然语言,并将它们融入到一个大型语言模型的提示中。我们使用下图所示的提示来促使gpt-3生成格式正确的句子。[facthead]、[factrelation]和[facttail]将被替换为正在表述的知识图谱事实的三个组成部分。
技术总结本发明公开了基于多模态知识图谱与大语言模型的视觉问答系统,属于人工智能自然语言处理领域。多模态知识图谱可有效处理自然文本和图像等多模态信息,再结合模式层关系细粒度解析问题,提高大模型生成答案的准确性。本发明将知识图谱中的实体和关系嵌入到大模型的向量空间中,作为大模型的输入之一,从而使大模型能够利用知识图谱中的信息进行推理和推断。通过设计T‑Encoder(文本编码器)、V‑Encoder(图像编码器)、M‑Encoder(混合编码器)和知识图谱过滤器φ来构建多模态知识图谱;再从知识图谱中检索事实,最后构造提示PromptFormulation,完成构建基于多模态知识图谱与大语言模型的视觉问答系统。技术研发人员:朱莹,冯君桐,袁善,荆渤韬,安浦闻,艾日帕提江·阿不都热合曼,赵茂春,郑子奇,张梦伟,张哲雨,李雨哲,刘鑫垚受保护的技术使用者:朱莹技术研发日:技术公布日:2024/7/29本文地址:https://www.jishuxx.com/zhuanli/20240730/197453.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。