一种基于文本简化和情感指导的观点摘要生成方法
- 国知局
- 2024-07-31 23:26:47
本发明属于文本摘要,具体涉及一种基于文本简化和情感指导的观点摘要生成方法。
背景技术:
1、随着互联网的普及和文本信息量的爆炸性增长,人们面临着大量信息的获取和处理压力。在这种情况下,文本摘要技术通过自动提取文本中的关键信息,帮助人们快速了解文本内容,节省了大量时间和精力。观点摘要是这一领域的一个重要分支,致力于将在线评论、互联网论坛或社交媒体中用户观点的表达进行聚合和提炼,其本质是文本摘要的子任务,核心目标是将多个文本总结为表达用户主要观点的简短摘要。
2、近年来,人们提出了许多观点摘要生成技术,以从大量评论数据中过滤出有价值的观点信息。根据其工作性质,观点摘要生成技术可以分为两类:抽象式方法和抽取式方法。对于抽象式观点摘要生成方法,大多数工作围绕基于深度学习的生成式框架展开,例如transformer、gpt(generative pre-trained)等。由于缺乏标注的摘要数据集,需要通过构造伪摘要数据集对模型进行监督训练,其成功的关键在于合成数据集的质量。对于抽取式观点摘要生成方法,一般工作聚焦在两个关键步骤:先利用模型得到评论句子的语义表示,后使用某种算法结合评论句子的语义表示选择最合适的句子集。
3、理想的观点摘要应该能够准确表达用户的主要观点,并具备共识性和简洁性的特点。然而,现有的观点摘要生成方法存在一些挑战,无法完全确保结果中不会存在冲突的观点句子,也难以保证生成的观点摘要不含复杂的摘要句子。因此,未来的研究和技术发展可以考虑集中于提高观点摘要的观点一致性和简洁性,以满足用户对信息快速获取和理解的需求。
技术实现思路
1、针对现有观点摘要生成方法存在的问题,本发明提供了一种基于文本简化和情感指导的观点摘要生成方法,从抽取式方法的角度改善生成的观点摘要中存在的含非共识观点、含冲突观点、句子不够简洁等问题。
2、本发明所采用的技术方案如下:
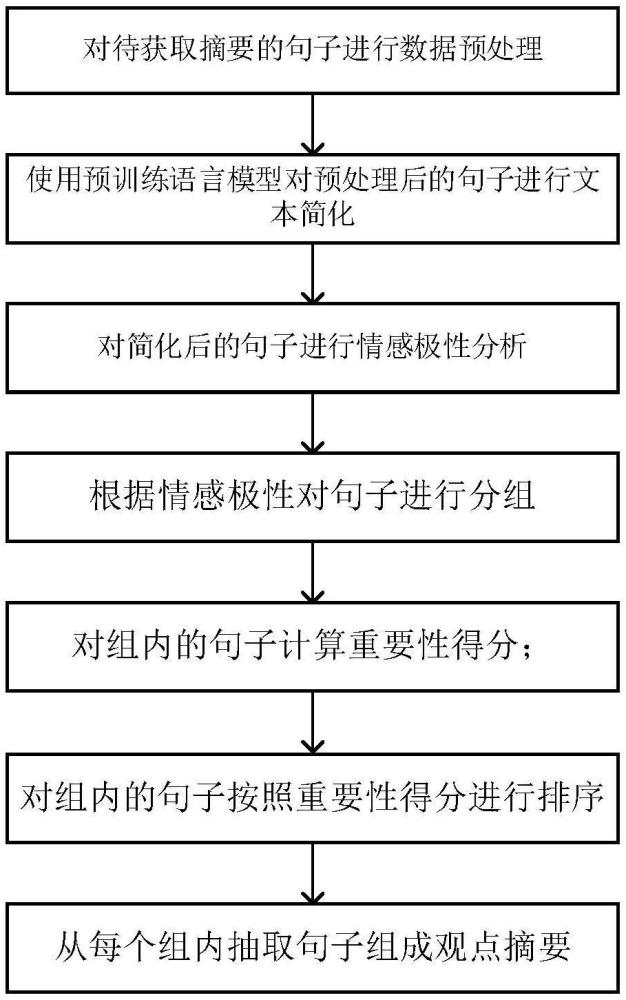
3、一种基于文本简化和情感指导的观点摘要生成方法,包括以下步骤:
4、s1、对待处理数据集中的所有句子进行预处理;
5、s2、利用第一预训练语言模型,对预处理后的句子进行文本简化,得到简化后句子;
6、s3、利用第二预训练语言模型,对简化后句子进行情感极性分析,得到各简化后句子的情感分布以及所属情感极性类别;
7、s4、根据情感极性类别对各简化后句子进行分组,将属于相同情感极性类别的简化后句子归为一组;
8、s5、对每个分组,计算其中各简化后句子的重要性得分,并对简化后句子按照重要性得分进行降序排列;
9、s6、根据各简化后句子的情感分布,计算每个分组的权重,并根据权重选取简化后句子,对所有分组中选取的简化后句子进行拼接,得到观点摘要。
10、进一步地,所述情感极性类别共有5类,分别为极负、负向、中立、正向和极正。
11、进一步地,s1中预处理的过程包括:
12、s1.1、删除句子中的网页链接;
13、s1.2、删除字符长度小于4的句子。
14、进一步地,s2中文本简化的过程包括:
15、s2.1、利用训练好的第一预训练语言模型,对预处理后的句子进行简化,得到简化后句子;其中,所述第一预训练语言模型具体为bart预训练语言模型;
16、s2.2、判断简化后句子的字符长度是否超过预设长度阈值,若是,则根据简化后句子内的标点符号进行句子划分,得到新的简化后句子;否则,保留简化后句子。
17、进一步地,所述标点符号包括顿号、逗号、句号、问号、感叹号、冒号、分号、括号、方括号、省略号和破折号。
18、进一步地,所述第二预训练语言模型具体为训练好的roberta预训练语言模型,或训练好的bert预训练语言模型。
19、进一步地,s5中计算各简化后句子的重要性得分的过程包括:
20、s5.1、构建包含依次的编码器(encoder)和解码器(decoder)的语义表征模型,以待处理数据集为语义表征训练集,对语义表征模型进行训练,得到训练后语义表征模型;
21、s5.2、提取训练后语义表征模型中的编码器,用于句子语义表征;
22、s5.3、假设s4所得分组中第j,j=1,2,...,5个分组共包括nj,j=1,2,...,5个简化后句子,在第j个分组中第i,i=1,2,...,nj个简化后句子的头部添加一个特殊符号,将添加特殊符号的简化后句子输入至s5.2所得编码器中,经编码器处理后,其输出的特殊符号的编码即为第j个分组中第i个句子的语义表征zi,i=1,2,...,nj;
23、s5.4、根据第j个分组中所有简化后句子的语义表征,求取语义表征平均值zj,j=1,2,...,5;
24、s5.5、对第j个分组中的第i个简化后句子,计算其语义表征zi与语义表征平均值zj的相似度,作为其重要性得分。
25、进一步地,采用kl(kullback-leibler divergence)散度计算相似度。
26、进一步地,s6中计算每个分组的权重的过程包括:
27、s6.1、假设第j个分组中第i个简化后句子的情感分布为pi,i=1,2,...,nj,具体为1×5维的向量,对第j个分组中所有简化后句子的情感分布的对应维度进行求和,所得结果作为第j个分组的整体情感分布psum,j,j=1,2,...,5,公式为:
28、
29、s6.2、对第j个分组的整体情感分布psum,j进行归一化操作,得到第j个分组的权重wjj=1,2,...,5,公式为:
30、
31、进一步地,s6中,所有分组中选取的简化后句子共同构成句子集,根据句子集中所有简化后句子的语义表征,求取语义表征平均值,进而计算得到句子集中各简化后句子的重要性得分,再按照重要性得分进行降序排列,选取前n个句子,拼接得到观点摘要;其中,n为已知人工撰写的标准观点摘要的句子数平均值。
32、与现有技术相比,本发明的有益效果如下:
33、本发明提出了一种基于文本简化和情感指导的观点摘要生成方法,在观点摘要技术中引入文本简化技术,将复杂句子转换为简单句子,能够帮助减少摘要中存在的复杂句子,提高了观点摘要的简洁性;同时该方法有效利用了句子的情感信息,利用情感重要性得分计算整体情感权重,用于生成观点摘要,可减少摘要中非共识观点或冲突观点,提高观点摘要的共识性;本发明相较于现有已公开的观点摘要生成方法,在摘要评价指标rouge上具有优异的效果。
技术特征:1.一种基于文本简化和情感指导的观点摘要生成方法,其特征在于,包括以下步骤:
2.根据权利要求1所述基于文本简化和情感指导的观点摘要生成方法,其特征在于,所述情感极性类别共有5类,分别为极负、负向、中立、正向和极正。
3.根据权利要求1所述基于文本简化和情感指导的观点摘要生成方法,其特征在于,s1中预处理的过程包括:
4.根据权利要求1所述基于文本简化和情感指导的观点摘要挖掘方法,其特征在于,s2中文本简化的过程包括:
5.根据权利要求4所述基于文本简化和情感指导的观点摘要生成方法,其特征在于,所述标点符号包括顿号、逗号、句号、问号、感叹号、冒号、分号、括号、方括号、省略号和破折号。
6.根据权利要求2所述基于文本简化和情感指导的观点摘要生成方法,其特征在于,所述第二预训练语言模型具体为训练好的roberta预训练语言模型,或训练好的bert预训练语言模型。
7.根据权利要求2所述基于文本简化和情感指导的观点摘要生成方法,其特征在于,s5中计算各简化后句子的重要性得分的过程包括:
8.根据权利要求7所述基于文本简化和情感指导的观点摘要生成方法,其特征在于,采用kl散度计算相似度。
9.根据权利要求7或8任一项所述基于文本简化和情感指导的观点摘要生成方法,其特征在于,s6中计算每个分组的权重的过程包括:
10.根据权利要求9所述基于文本简化和情感指导的观点摘要生成方法,其特征在于,s6中,所有分组中选取的简化后句子共同构成句子集,根据句子集中所有简化后句子的语义表征,求取语义表征平均值,进而计算得到句子集中各简化后句子的重要性得分,再按照重要性得分进行降序排列,选取前n个句子,拼接得到观点摘要;其中,n为已知人工撰写的标准观点摘要的句子数平均值。
技术总结本发明公开了一种基于文本简化和情感指导的观点摘要生成方法,属于文本摘要技术领域,具体为:对待处理数据集中的所有句子进行预处理,利用第一预训练语言模型进行文本简化,得到简化后句子,利用第二预训练语言模型进行情感极性分析,得到各简化后句子的情感分布以及所属情感极性类别,将属于相同情感极性类别的简化后句子归为一组;对每个分组,计算其中各简化后句子的重要性得分,并降序排列;计算每个分组的权重,根据权重选取简化后句子,所有分组选取的简化后句子拼接得到观点摘要。本发明可提高观点摘要的简洁性和共识性,在摘要评价指标Rouge上具有优异的效果。技术研发人员:王瑞,蓝天,刘瑶,吴祖峰,陈韬锐,佟飘受保护的技术使用者:电子科技大学技术研发日:技术公布日:2024/7/29本文地址:https://www.jishuxx.com/zhuanli/20240730/197611.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表