改进Adaboost算法的虚拟电厂短期负荷预测方法及系统与流程
- 国知局
- 2024-07-31 17:54:39
本发明涉及虚拟电厂自调度,具体为改进adaboost算法的虚拟电厂短期负荷预测方法及系统。
背景技术:
1、在当前的市场机制下,虚拟电厂不论参与电能量市场还是辅助服务市场,其竞标决策和调度决策都有赖于vpp对其服务范围内的负荷进行短期预测,vpp不仅要通过短期负荷的预测决定日前申报量,还要确定可控负荷的可调节容量以制定相应的调度方案。
2、当前电力负荷增长主要方向以及高峰用电负荷的主体构成已经由传统的工业负荷为主向降温取暖负荷和电动汽车等新型负荷转变,系统的负荷水平逐年升高,负荷峰谷差拉大,部分时段电力供应紧张。要做好电力的生产、运行、规划工作,就需要对电力负荷特性及其发展趋势进行准确把握,从而不断提高负荷特性分析的精细度、预测的精准度。电力负荷是社会生产活动和消费行为的结果,在短期内受用户行为习惯和环境因素的影响,在长期受如经济条件等宏观因素影响。
3、对于vpp的运营,短期负荷的预测直接关系到其决策的经济性与服务对象的满意度。对于短期负荷的预测,主要方法可分为传统的数理统计分析方法和以人工智能、深度学习为代表的新型智能方法。由于自调度技术要求,新型智能预测方法是vpp在应用层面的优先选择,而传统数理统计分析方法则主要提供一些优化思路和算法依据。不仅如此,考察成熟的vpp运营案例,vpp的调度决策中心实际上可以被视为一个多维智能体,通过人工智能等前沿技术,智能体不仅可以预测短期负荷给出决策优化路径,还能智能执行调度计划并调整。因此,vpp的短期负荷预测是智能体应该具备的基础能力,并且具体预测方法并非某一特定算法,而是多种预测工具或模型的整合。也就是说,多路径融合是vpp整体解决方案的必然趋势,如何将多种基于不同类型神经网络和机器学习方法结合以提高vpp对短期负荷的预测效果,是vpp自调度技术中必须解决的问题。
4、在机器学习领域,多方法融合的领域被成为集成学习,集成学习不是一种具体的机器学习方法,而是一种“组装方法”。集成学习演化自二叉树问题的解决,核心思路是从集体智慧中精选结果以提升机器学习和训练的效果。集成学习先在同一个训练数据集上训练多个弱分类器,然后把这一组弱分类器整合起来,产生一个强分类器(strongclassifier)。当前主流的集成学习方法包括bagging和boosting,两种方法都可以处理分类问题和预测问题,不同点在于bagging的强分类器是通过决策树生成过程中的投票来确定强分类器,而boosting则是通过迭代过程中调整分类器的权重来去弱留强而生成强分类器的。bagging要求样本中的特征变量必须是相互独立的,这在现实中很难把握,而boosting具有更佳的拓展性,而且有助于识别和提升vpp工具库中的各类模型的效果。
5、adaboost(adaptive boosting)自适应算法,一种被广泛采用的boosting算法,它最显著的优点在于可以生成高精度的强分类器,并且不用担心过拟合。此外,adaboost的弱分类器即可以随机生成,也可以用lstm、cnn等神经网络来生成,具有较好的可扩展性,因此非常适合解决vpp多预测模型的整合优化。
6、本发明将通过改进adaboost算法,为vpp短期负荷预测提供一种集成优化的方法。
技术实现思路
1、鉴于上述存在的问题,提出了本发明。
2、因此,本发明解决的技术问题是:如何通过改进adaboost算法,整合多种预测模型,以提高虚拟电厂(vpp)短期负荷预测的准确性和决策制定的效率。
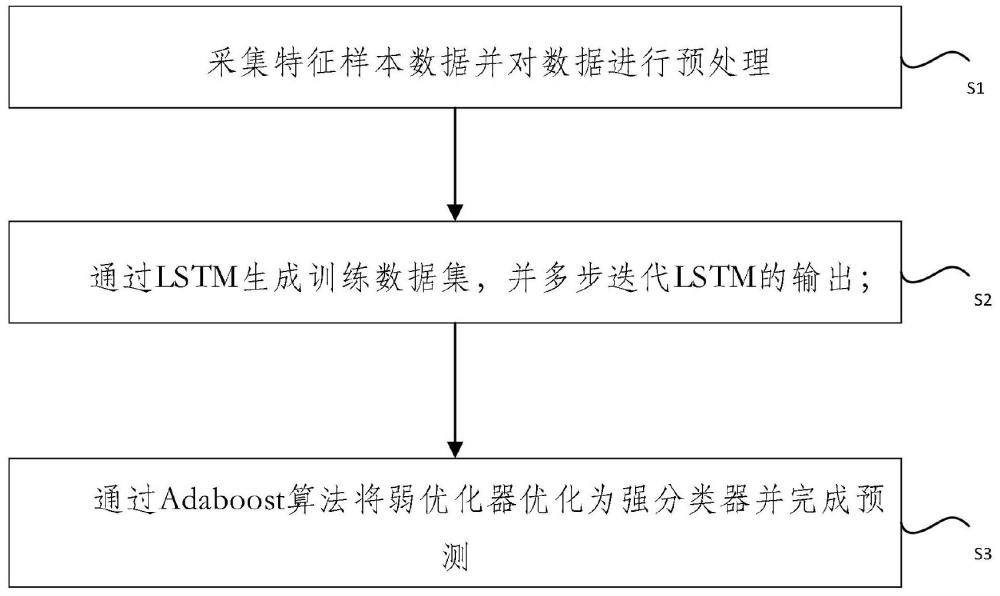
3、为解决上述技术问题,本发明提供如下技术方案:改进adaboost算法的虚拟电厂短期负荷预测方法,其包括如下步骤,
4、采集特征样本数据并对数据进行预处理;通过lstm生成训练数据集,并多步迭代lstm的输出;通过adaboost算法将弱优化器优化为强分类器并完成预测。
5、作为本发明所述的改进adaboost算法的虚拟电厂短期负荷预测方法的一种优选方案,其中:所述特征样本数据包括时间维度的特征数据和气候维度的特征数据,所述时间维度的特征数据表示为γ={m,d,h,λ},所述气候维度的特征数据表示为
6、其中,m、d、h分别代表时间维度的特征数据所处的月份、日期和时辰,λ表示虚拟变量,表示平均气温,atmax和atmin为当日最高气温和最低气温,rh为相对湿度,aq表示空气质量,wi表示天气状况,下标i={1,2,3,4,5},表示具体的天气类型,分别对应晴天、阴天、雨天、雪天和雾天,表示当日平均风速。
7、所述特征样本数据表示为,
8、
9、其中,x表示所有样本按照时间序列排布的特征样本序列整体,xi表示时间序列中第i个样本数据。
10、作为本发明所述的改进adaboost算法的虚拟电厂短期负荷预测方法的一种优选方案,其中:所述预处理包括,若样本序列xi的分量λ在时间序列第t+1个位置出现缺失,则对数据λt+1进行补齐,表示为,
11、
12、其中,λ't+1表示用平滑法、插值法预测的值,ζt为粗糙集理论中用以衡量隶属度的参数。
13、所述ζt表示为,
14、
15、基于3σ原则鉴别异常数据,表示为,
16、|λi,t-e(λi)|>3σ (4)
17、其中,λi,t表示特征序列中第i个非离散变量和非虚拟变量在t时刻的取值,e(λi)表示对应变量的期望,σ表示对应变量的标准差。
18、若样本λi,t满足3σ原则,则鉴定为异常数据,当鉴定为异常数据时,则进行修复,表示为,
19、
20、其中,表示异常数据修复后的替换数据,表示与λi,t当日性质相同的前一天同一时刻的样本数据,则表示与当日性质相同的后一天同一时刻的样本数据,α和β为权重参数。
21、作为本发明所述的改进adaboost算法的虚拟电厂短期负荷预测方法的一种优选方案,其中:所述lstm包括记忆细胞、输入门、输出门和遗忘门;
22、所述输入门表示为,
23、it=σ(wi·[ht-1,ωt]+di) (6)
24、其中,σ表示sigmoid函数,it为输入门在t时刻的输出,wi表示输入门的权重矩阵,di表示输入门与记忆细胞之间的漂移量,ht-1表示隐藏层上一步输出的状态,ωt表示第t步的输入序列,是我们初始输入样本序列x后在t步迭代后的变换。
25、输入门控制的记忆细胞的状态更新值表示为,
26、
27、其中,表示记忆细胞在t时刻由输入门决定的状态更新值,tanh表示双曲正切函数,wc表示记忆细胞状态更新的权重矩阵,dc表示细胞状态更新的漂移量。
28、所述遗忘门表示为,
29、ft=σ(wf·[ht-1,ωt]+df) (8)
30、其中,ft表示t时刻遗忘门的输出,wf表示遗忘门的权重矩阵,df表示遗忘门与记忆细胞间的漂移量。
31、通过输入门和遗忘门的输出得出记忆细胞在t时刻的状态,表示为,
32、
33、所述训练数据集表示为,
34、s={(x1,y1),(x2,y2),…,(xn,yn)} (10)
35、其中,yn为xn的预测结果。
36、作为本发明所述的改进adaboost算法的虚拟电厂短期负荷预测方法的一种优选方案,其中:所述多步迭代lstm的输出包括,将训练数据集按照样本总数n进行样本的初始等权重分布,表示为,
37、
38、其中,表示初始弱分类器的权重。
39、将样本输入lstm,得到初始弱分类器,初始弱分类器的输出表示为,
40、g(x)=w1h1(x) (12)
41、其中,w0表示初始弱分类器的权重,g(x)为分类器的输出,h(x)表示初始弱分类器的预测结果。
42、作为本发明所述的改进adaboost算法的虚拟电厂短期负荷预测方法的一种优选方案,其中:所述多步迭代lstm的输出还包括,设置分类判别阈值φ,将h(x)中的序列与测试序列进行比对,计算预测误差,若输出序列中与测试序列中元素的误差大于阈值,则表示预测错误,若小于阈值,则表示预测正确。
43、所述预测误差表示为,
44、
45、所述测试序列表示为td={z1,z2,…,zn}。
46、其中,zi表示与样本特征xi对应时间序列的真实负荷历史数据,ρi表示虚拟变量。
47、作为本发明所述的改进adaboost算法的虚拟电厂短期负荷预测方法的一种优选方案,其中:所述优化为强分类器并完成预测包括,将式(10)-式(12)以及测试序列作为迭代的初始条件,进入后续的迭代过程,通过弱分类器的权重和样本权重更新adaboost算法。
48、所述权重更新包括,当迭代进行到第t步,则样本权重分布为对第i个特征元素的输出预测值记为ht(xi),则测试集预测误差表示为,
49、
50、训练样本集在第t步总误差表示为,
51、
52、当前步分类器权重赋值表示为,
53、
54、第i个样本在第t步的权值更新为,
55、
56、当t=t时,算法收敛,得到adaboost优化后的强分类器,表示为,
57、g(x)=w1h1(x)+w2h2(x)+…+wtht(xn)
58、基于强分类器的输出结果为通过adaboost优化后的短期负荷预测结果。
59、所述预测结果通过平均绝对百分比误差进行评估,表示为,
60、
61、若评估效果不达预期,则通过调整lstm步长和adaboost的参数进行优化。
62、本发明的另外一个目的是提供改进adaboost算法的虚拟电厂短期负荷预测系统,其能通过整合长短期记忆网络(lstm)和多步迭代优化的方式,提高预测的准确性和稳定性,解决了现有预测方法在处理复杂负荷模式和动态环境变化时准确度不足的问题。
63、为解决上述技术问题,本发明提供如下技术方案:改进adaboost算法的虚拟电厂短期负荷预测系统,包括数据采集与预处理模块、lstm训练数据生成模块、预测误差计算模块以及预测结果评估模块。
64、所述数据采集与预处理模块负责采集特征样本数据,包括时间维度和气候维度的特征数据,并对数据进行预处理。
65、所述lstm训练数据生成模块利用长短期记忆网络生成训练数据集,并通过多步迭代lstm的输出。
66、所述预测误差计算模块负责计算预测误差,包括设置分类判别阈值,比对预测序列与测试序列,计算每个元素的预测误差。
67、所述预测结果评估模块基于强分类器的输出结果进行短期负荷预测,并通过平均绝对百分比误差进行评估。
68、一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现如上所述改进adaboost算法的虚拟电厂短期负荷预测方法的步骤。
69、一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如上所述改进adaboost算法的虚拟电厂短期负荷预测方法的步骤。
70、本发明的有益效果:本发明通过adaboost算法能够实现多技术手段的融合优化,在本设计中我们采用lstm来生成弱分类器,可以充分发挥lstm在挖掘中长周期样本特征方面的优势,通过多步迭代lstm来生成adaboost分类器进行决策,避免了多个神经网络并行的操作繁琐和大量成本,能够提升lstm的预测效果,避免过拟合和提升了鲁棒性。
本文地址:https://www.jishuxx.com/zhuanli/20240731/177247.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。