一种面向无信号人行横道的人-车动态博弈决策模型的建立方法
- 国知局
- 2024-07-31 21:08:46
本发明属于车路协同,特别是涉及一种面向无信号人行横道的人-车动态博弈决策模型的建立方法。
背景技术:
1、无信号人行横道的安全问题一直是城市交通管理中的一大挑战。与有信号控制的十字路口不同的是,无信号人行横道缺乏信号灯等直接的过街指导,行人与机动车之间的交互变得更加复杂和危险,经常出现行人和驾驶人必须协商决定谁应该先走的情况,极大地威胁着行人和驾驶员的人身安全。目前,针对行人与车辆交互作用的研究方法不能明确考虑驾驶员与行人之间的动态交互和认知决策的整个过程,导致无法从整个系统的角度来理解车辆与行人之间的相互作用。在没有信号控制的人行横道处,过街行人与机动车驾驶人往往根据自身对周边环境、人流、车流状况的观察与判断进行决策。当行人和机动车均选择过街决策时,则可能会产生交通冲突甚至造成碰撞损失,如果为避免风险而采取避让行为,不但会增加延误成本,还会降低路段总体通行效率。因此,寻找一种能够有效管理无信号人行横道上行人与车辆交互的方法,提高过街安全性和效率,成为了一个迫切需要解决的问题。
2、机动车和行人在无信号人行横道上的交互行为本质上是一种争夺有限时间和空间资源的游戏。因此,博弈论适用于分析车辆与行人之间的相互作用。但是传统博弈模型是在不同收益条件下分析交通参与者行为的最优决策与均衡解问题,大多是一种静态分析,缺乏对过街行为动态演化过程的考虑。为了解决过街决策过程中的动态博弈问题,演化博弈理论被提出。演化博弈假设参与者是有限理性的,并且处于不完全信息的环境中,并且在分析策略选择的动态性更有优势。随着时间的推移,各博弈主体的策略选择依次在博弈中占主导地位,行人和机动车驾驶员会改变他们的策略选择,以回应对方的策略选择。因此,演化博弈为理解行人与机动车的动态交互提供了基础,建立一种面向无信号人行横道的人-车动态博弈决策模型是相关领域内技术人员急需解决的问题。
技术实现思路
1、本发明的目的在于提供一种面向无信号人行横道的人-车动态博弈决策模型建立方法。通过引入演化博弈论,深入理解和模拟行人与机动车在复杂交通环境中的互动模式和决策过程,进而寻找双方行为的均衡点和演化稳定策略,实现个体层面的最优行为选择,为车路协同背景下城市交通管理提供一种新的思路和方法。
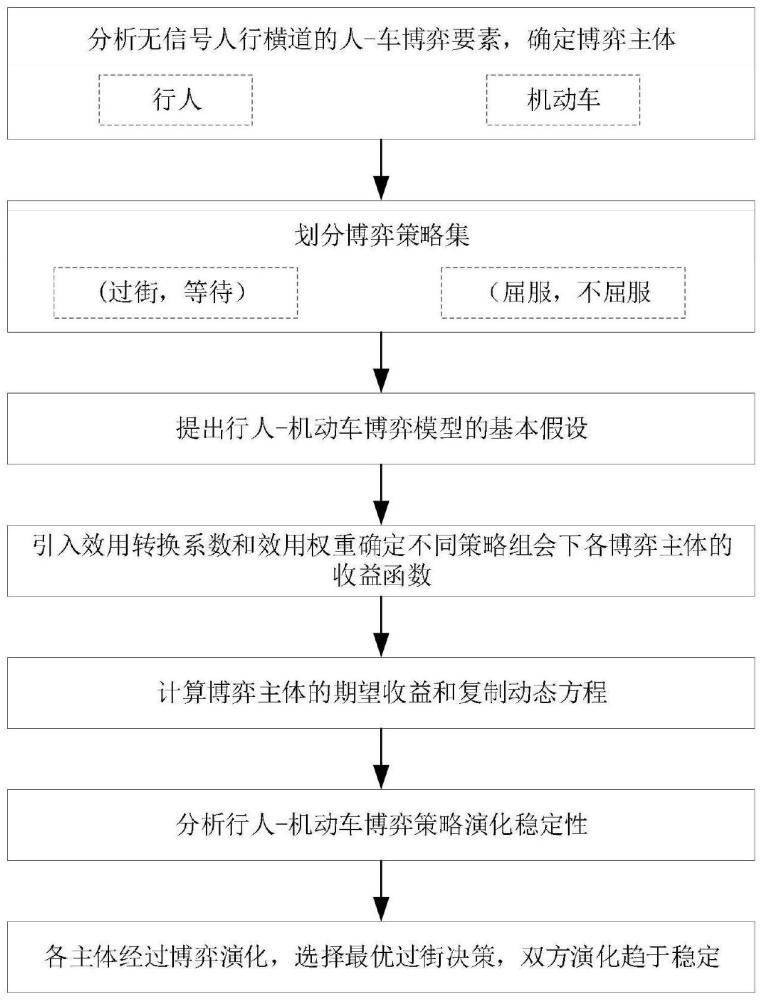
2、为了解决上述技术问题,本发明提出一种面向无信号人行横道的人-车动态博弈决策模型建立方法,该方法包括以下步骤:
3、s1:基于演化博弈模型确定博弈主体为群体i1和群体i1,设定各博弈主体的策略集,并提出博弈模型的基本假设;
4、s2:引入效用转换系数和效用权重构建不同策略组合下各博弈主体在一次博弈中的支付矩阵;
5、s3:针对不同博弈主体的期望收益建立复制动态方程,得到均衡点并确定演化稳定策略ess;
6、s4:根据所建立的复制动态方程绘制动态演化过程,结合动态演化收敛路径以及演化稳定策略ess确定人车动态交互最优决策。
7、进一步的,所述步骤s1中所述群体i1为行人,所述群体i2为机动车;行人的策略集为{过街,等待},机动车的策略集{屈服,不屈服};所述博弈模型的基本假设包括:
8、假设1:行人与机动车的运动状态发生明显改变时博弈开始。
9、假设2:博弈中的行人与机动车都是有限理性的,且彼此之间互相不了解对方的行为倾向,即决策的过程具有动态调整性,通过行为学习获取最大收益;
10、假设3:博弈过程中机动车驾选择“屈服”的概率为q,选择“不屈服”的概率为1-q;行人选择“过街”的概率为p,选择“不过街”的概率为1-p。
11、假设4:车辆和行人在通过无信号控制人行横道时往往是根据感知风险进行决策,机动车可能会选择通过,同时行人也会选择穿越人行横道,这样导致双方会面临潜在的碰撞损失为风险效用。记行人可能选择的行动的风险效用为,机动车可能选择行动的风险效用记为;行人与机动车在到达人行横道处因避免冲突而选择彼此让行所产生的过街等待时间为延误效用,即行人的延误效用为,机动车的延误效用为。犹豫过街状态下行人的延误效用记为,风险效用记为,机动车的延误效用记为,风险效用记为,
12、假设5:过街行人和机动车的延误效用和风险效用都可以统一无量纲化为某一合理数值,用来表示收益效用。
13、进一步的,所述步骤s2中确定效用转换系数与效用权重,构建支付矩阵的方法如下:
14、s2-1、确定风险效用与延误效用的转换系数
15、由于风险效用的单位和延误效用的量纲不一致,不可以简单直接相加。因此,在构建收益函数时,首先需要寻找风险效用与延误效用的转换系数。采集延误过街状态下的行为数据来估计风险效用和延误效用之间的转换系数。
16、(1)提取犹豫过街状态数据
17、采集延误过街状态下的行为数据,根据“停顿和观察”和“犹豫步伐”提取犹豫过街样本行为数据。
18、(2)效用转换系数确定
19、首先,根据过街行为数据得到风险效用和延误效用,并采用最小-最大归一化进行标准化处理;其次,根据机动车驾驶员或行人犹豫过街时,驾驶人或行人感知到的风险与延误大约相等,得到延误-风险效用转换系数方程ud'ped,i=ωiur'ped,i,ud'veh,i=γiur'veh,i。最后根据中心极限定理原理计算对犹豫状态下的转换系数均值,得到行人延误-风险效用转换系数ω,机动车延误-风险效用转换系数γ。
20、s2-2、确定收益函数中风险效用与延误效用的权重系数
21、在实际驾驶过程中,延误和风险对驾驶员/行人的收益有不同的影响。如果冲突发生时驾驶员/行人的风险感知值低于他/她可接受的风险感知水平,那么他/她将专注于改进延误;如果驾驶员的感知风险值高于他/她可接受的风险感知水平,那么他/她将专注于改变风险。然而,如果驾驶员/行人的风险感知值在可接受的风险水平范围内,那么速度和风险对驾驶员/行人的回报同样重要。因此,在构建支付矩阵时行人的风险效用考虑权重系数m,机动车驾驶员的风险效用权重系数为n,
22、行人的风险效用权重系数m为:
23、
24、机动车的风险效用权重系数n为:
25、
26、式中,m表示构建支付矩阵时行人的风险效用权重系数,m∈[0,1];n表示构建支付矩阵时机动车的风险效用权重系数,n∈[0,1];αveh,αped分别表示机动车、行人的可接受风险阈值下限;βveh,βped分别表示机动车、行人的可接受风险阈值上限;本发明推荐、αveh=0.44,αped=0.24,βveh=0.60,βped=0.47。
27、s2-3、构建不同策略组合下各博弈主体的支付矩阵
28、建立博弈主体在一次博弈中的支付矩阵:
29、
30、策略组合为行人过街机动车屈服时,行人的风险和延误抵消,故收益0,机动车驾驶员因选择减速或停车等待付出延误成本udveh,因此各博弈主体收益为:uped11=0,uveh11=-udveh;
31、策略组合为行人过街机动车不屈服时,二者可能会发生冲突乃至碰撞,此时行人和机动车驾驶员将根据风险稳态理论做出行为决策,分别付出风险成本和延误成本,故各博弈主体收益为:uped12=-(ωnurcross+(1-m)udped),uveh12=-(γnurnotyield+(1-n)udveh);
32、策略组合为行人等待机动车屈服时,二者都不会发生冲突风险,但都因减速产生了延误成本,此时行人和机动车驾驶员分别支付延误成本,故各博弈主体收益为:uped21=-udped,uveh21=-udveh;
33、策略组合为行人等待机动车不屈服时,行人因等待产生时间成本,机动车因过街收益和风险抵消,故收益为0。因此各博弈主体收益为:uped22=-udped,uveh22=0;
34、进一步的,所述步骤s3中复制动态方程构建和演化稳定策略ess分析方法如下:
35、s3-1、考虑行人、机动车过街随机性,得到各策略选择下的期望收益。
36、当行人选择过街时的期望收益为:
37、eped1=quped11+(1-q)uped12=q·0+(1-q)·[-(mωurcross+(1-m)udped)]
38、当行人选择等待时的期望收益为:
39、eped2=quped21+(1-q)uped22=q·(-udped)+(1-q)·(-udped)
40、行人的平均期望收益为:eped=peped1+(1-p)eped2
41、当机动车选择屈服时的期望收益为:
42、eveh1=puveh11+(1-p)uveh12=p·(-udveh)+(1-p)·(-udveh)
43、当机动车选择不屈服时的期望收益为:
44、eveh2=puveh21+(1-p)uveh22=p·[-(nγurnotyield+(1-n)udveh)]+(1-p)·0
45、机动车的平均期望收益为:eveh=qeveh1+(1-q)eveh2
46、s3-2、基于演化博弈理论,计算得到各方博弈主体的复制动态方程。
47、行人选择立即过街策略的复制动态方程为:
48、
49、机动车驾驶员选择屈服策略的复制动态方程为:
50、
51、s3-3、令复制动态方程得到局部均衡点:o(0,0),a(1,0),b(1,1),c(0,1),h(p*,q*)。其中,
52、s3-4:构建雅克比矩阵j分析局部均衡点的稳定性,同时满足行列式det(j)>0迹tr(j)<0时,均衡点对应的策略为演化稳定策略ess。
53、雅克比矩阵为:
54、
55、
56、
57、进一步的,所述步骤s4中确定人车动态交互最优决策的具体方法为:
58、s4-1、将求得的局部均衡点划分为相位图:
59、根据不同收敛区域面积大小得到动态演化收敛路径。不同区域收敛面积表示为:
60、
61、
62、当saoch>sabch时,过街决策收敛于局部均衡点o(0,0),当saoch≤sabch时,过街决策收敛于局部均衡点b(1,1)。
63、s4-2:结合收敛路径和演化稳定策略ess确定人车动态交互最优决策。使用matlab进行模拟仿真,分析人车博弈系统决策演化的收敛路径。
64、本发明提出了一种面向无信号人行横道的人-车动态博弈决策模型建立方法;基于演化博弈理论,引入感知风险效用和延误效用构建演化博弈模型,将行人和驾驶员在效率、安全两个维度上的感知与决策结果联系起来,展示行人/机动车过街决策的动态演变过程,实现从风险的模糊感知到行为决策的转换,更加准确的解析无信号人行横道过街决策的形成机理。这可以为车路协同背景下自动驾驶汽车过街决策提供一些启示,有助于主动预防和控制无信号路段的碰撞风险,提高行人过街安全。
本文地址:https://www.jishuxx.com/zhuanli/20240731/188557.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。