智慧交通三维数字孪生方法、装置及介质与流程
- 国知局
- 2024-07-31 21:08:48
本发明属于智慧交通,更具体地,涉及一种智慧交通三维数字孪生方法、装置及介质。
背景技术:
1、智慧交通的基石是建立可映射物理世界的虚拟世界,因此大多数交通管理平台项目通过抽象建模构造二维电子地图,并在抽象模型上集成数据及分析工具,实现运营期信息化管理。随着设计、施工、运营全生命周期细化管理日益增长的需求,传统的交通地理信息(geographic informa-tion system-transportation,gis-t)系统的压力也随之增加。交通基础设施数字化映射为三维gis信息世界的技术方案是突破二维gis-t系统局限的有效途径,其已成为交通信息化研究的热点课题,目前研究主要集中于建模、数据库协同、可视化分析。
2、随着人工智能(ai)、云计算和芯片技术的发展,ai生成的内容(aigc)正在发生令人难以置信的变化。从认知和学习的角度来看,正如人类的学习过程从模仿到改进再到创造一样,aigc正在经历从感知和孪生真实的世界(学习复制)到预测和改进现实世界(学习改变),最后到评估和创造数字世界(学习创造)的过程。凭借“自动化与高效”、“创意拓展与多样性”、“大规模个性化与定制化”等优势,aigc在智能交通系统(its)中的应用已经展开,如实时交通导航等。
3、与之比较类似的技术有交通仿真软件,如sumo(simulation of urban mobility)和transcad,然而文献《lin zhiyang,liu zheng,fang zhiming,et al.review ofpedestrian and traffic evacuation simulation software[j].china safety sciencejournal,2022,32(9):100-110.》系统梳理了已有主流软件,提出软件发展存在的问题和关键技术。首先,介绍行人和交通疏散仿真软件的发展现状,从底层模型、功能和拓展性等方面对比国内外主流软件,一般包括路网建模、车辆模拟、交通流模拟和数据输出和分析共四个流程,模拟结束后,软件提供了丰富的数据输出,包括车辆轨迹、交通流量、排队长度等。这些数据可供进一步分析和规划使用。之后,阐释发展具有自主知识产权的行人和交通疏散仿真软件存在的问题和困难。结果表明:行人和交通疏散仿真软件应用广泛;主流商业软件的底层模型不可更改,应用场景受限,自主研发行人疏散仿真软件和交通疏散仿真软件十分必要。
4、另外,也有一些在此基础上进行改进的技术和方法,如文献《赵龙刚,刘汉生,张小平,等.基于数字孪生的车路协同虚拟仿真平台研究[j].移动通信,2021,45(6):07-12.》,提出一种基于数字孪生的交通仿真平台研究方法,完成人-车-路-网的全息仿真映射,构造可配置的场景案例串联测试方式;同时在安全、环保、效率等维度设计评估优化方法,实现车路协同平台感知、决策、控制的闭环仿真测试,为车路协同方案落地提供借鉴和参考。
5、上述技术缺点很明显,首先部署和维护智慧交通管理系统需要大量资金,包括传感器安装、数据中心建设和系统维护,其设施成本与人力成本十分高昂。另外,该交通仿真平台处理大量实时数据和进行复杂的数据分析需要高度的计算资源和专业知识,实时性与准确性需要得到严格保障,稍有偏差都可能会造成严重后果。最后,其使用门槛相对较高,缺少一定的用户友好性。
技术实现思路
1、提供了本发明以解决现有技术中存在的上述问题。因此,需要一种智慧交通三维数字孪生方法、装置及介质,结合了人工智能生成内容(aigc)和数字孪生技术,为智慧交通领域提供了新的解决方案,以实现更全面的智慧交通三维模型和更友好的用户体验。
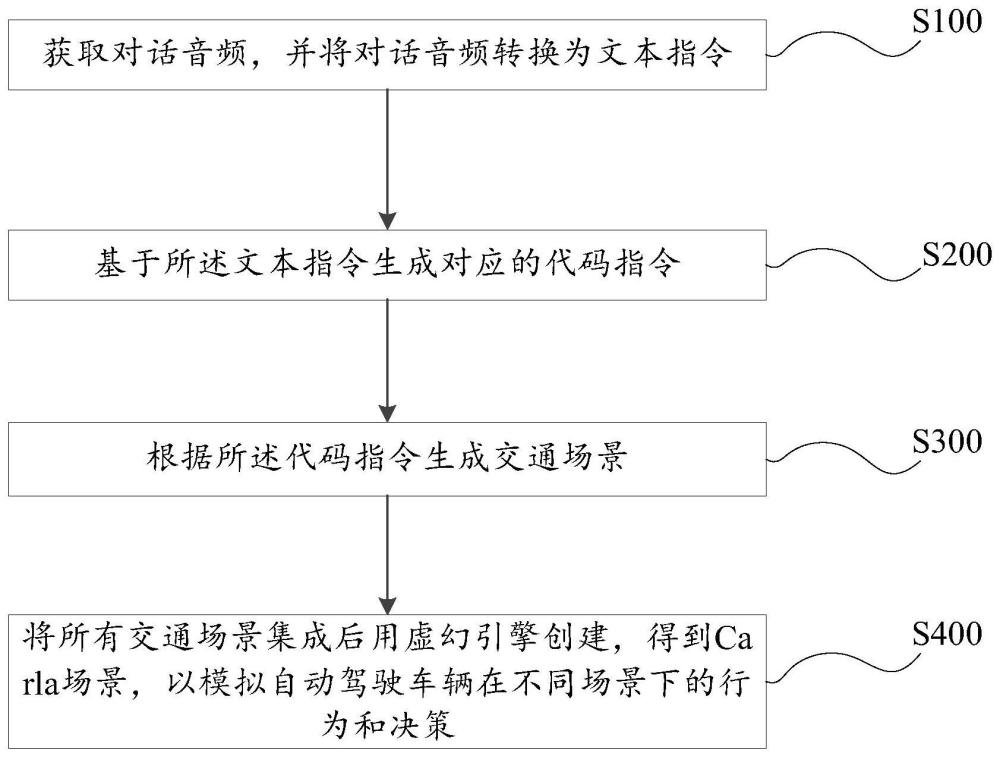
2、根据本发明的第一方案,提供了一种智慧交通三维数字孪生方法,所述方法包括:
3、获取对话音频,并将对话音频转换为文本指令;
4、基于所述文本指令生成对应的代码指令;
5、根据所述代码指令生成交通场景;
6、将所有交通场景集成后用虚幻引擎创建,得到carla场景,以模拟自动驾驶车辆在不同场景下的行为和决策。
7、进一步地,所述获取对话音频,并将对话音频转换为文本指令,具体包括:
8、获取第一音频数据,并基于所述音频数据提取特征词,若提取到的特征词包含有唤醒词,则播放问候音频,所述问候音频为预设的音频;
9、获取第二音频数据,将所述第二音频数据转换为文本指令。
10、进一步地,基于所述音频数据提取特征词,若提取到的特征词包含有唤醒词,则播放问候音频,具体包括:
11、预设声纹特征库,所述声纹特征库包括预设的声纹特征以及预设的声纹特征对应的问候音频;
12、若提取到的特征词包含有唤醒词,则基于所述音频数据提取声纹特征;
13、若声纹特征存在于预设的声纹特征库中,则播放预设的声纹特征对应的问候音频;
14、若声纹特征不存在于预设的声纹特征库中,则播放指示音频,所述指示音频用于引导当前声纹特征的预设操作。
15、进一步地,基于所述文本指令生成对应的代码指令,具体包括:
16、基于wizardcoder大模型,将所述文本指令生成对应的代码指令,所述wizardcoder大模型包括lora微调训练数据集,所述lora微调训练数据集通过人工进行标注。
17、进一步地,根据所述代码指令生成交通场景后,所述方法包括:
18、基于数字孪生技术来进行多交通场景的模拟,并在编辑器中将所有交通场景集成。
19、进一步地于,所述交通场景包括roadrunner交通场景、drivingscenario交通场景和sl3d交通场景。
20、进一步地,所述方法还包括:展示所有交通场景。
21、进一步地,所述展示所有交通场景,具体包括:
22、将所有场景通过像素流的方式输入到浏览器中进行最终展示。
23、根据本发明的第二技术方案,提供一种智慧交通三维数字孪生装置,所述装置包括:
24、文本指令获取单元,被配置为获取对话音频,并将对话音频转换为文本指令;
25、代码指令生成单元,被配置为基于所述文本指令生成对应的代码指令;
26、交通场景生成单元,被配置为根据所述代码指令生成交通场景;
27、carla场景创建单元,被配置为将所有交通场景集成后用虚幻引擎创建,得到carla场景,以模拟自动驾驶车辆在不同场景下的行为和决策。
28、进一步地,所述文本指令获取单元,被进一步配置为:
29、获取第一音频数据,并基于所述音频数据提取特征词,若提取到的特征词包含有唤醒词,则播放问候音频,所述问候音频为预设的音频;
30、获取第二音频数据,将所述第二音频数据转换为文本指令。
31、进一步地,所述文本指令获取单元,被进一步配置为:
32、预设声纹特征库,所述声纹特征库包括预设的声纹特征以及预设的声纹特征对应的问候音频;
33、若提取到的特征词包含有唤醒词,则基于所述音频数据提取声纹特征;
34、若声纹特征存在于预设的声纹特征库中,则播放预设的声纹特征对应的问候音频;
35、若声纹特征不存在于预设的声纹特征库中,则播放指示音频,所述指示音频用于引导当前声纹特征的预设操作。
36、进一步地,所述代码指令生成单元,被进一步配置为:基于wizardcoder大模型,将所述文本指令生成对应的代码指令,所述wizardcoder大模型包括lora微调训练数据集,所述lora微调训练数据集通过人工进行标注。
37、进一步地,所述carla场景创建单元被进一步配置为基于数字孪生技术来进行多交通场景的模拟,并在编辑器中将所有交通场景集成。
38、进一步地,所述交通场景包括roadrunner交通场景、drivingscenario交通场景和sl3d交通场景。
39、进一步地,所述装置还包括显示单元,所述显示单元被配置为展示所有交通场景。
40、进一步地,所述显示单元被进一步配置为:
41、将所有场景通过像素流的方式输入到浏览器中进行最终展示。
42、根据本发明的第三技术方案,提供一种可读存储介质,所述可读存储介质存储有一个或者多个程序,所述一个或者多个程序可被一个或者多个处理器执行,以实现如上所述的方法。
43、本发明至少具有以下有益效果:
44、1)本发明利用aigc将语音识别的文字转换为代码指令,再通过对静态、动态数据的感知,可以对应的创建数字孪生模型,实现基于孪生数据的情景再现。
45、2)本发明在智慧交通领域有很大的应用前景,它不仅可以提高规划、设计、施工、运营、安全方面管理水平,实现交通管理决策协同化和智能化,还可以大幅度降低使用成本,利于普遍推广。
46、3)本发明通过语音识别对应的交通指令转换为文字,基于aigc处理指令生成相应代码,通过代码模拟出对应的交通场景,其中使用到数字孪生技术进行场景的衍生和完善,最后在虚幻引擎中展现出最终场景,并将所有结果输出到浏览器中。全过程是智能一体化运行,只需使用语音即可唤醒并执行全过程,用户交互性十分友好,在如今错综复杂的高科技中降低了用户使用门槛。
本文地址:https://www.jishuxx.com/zhuanli/20240731/188561.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。