基于图神经网络和分布表征匹配的交通流量预测方法
- 国知局
- 2024-07-31 21:28:45
本发明属于交通流量预测领域,特别涉及一种基于图神经网络和分布表征匹配的交通流量预测方法。
背景技术:
1、交通流量预测是指根据历史交通数据和其他相关信息,预测未来某个地区或道路上的交通流量情况。这是一个重要的任务。在城市交通管理方面,交通流量预测可以帮助城市交通管理部门更好地了解城市道路网络的交通状况,包括高峰期和非高峰期的流量变化情况。这有助于优化交通信号控制、调整道路规划、减少交通堵塞和提高道路使用效率。在市民的出行决策方面,对交通流量的准确预测可以帮助驾驶员和出行者选择最佳的出行路线和出发时间。它可以帮助避开拥堵路段,减少交通延误,提高出行效率。
2、交通流量预测通常涉及以下几个方面的内容:建立监测站点,布置交通流量监测站点,利用传感器和设备监测交通流量数据。监测站点的位置考虑了城市地理特征和交通流量的分布,以获得全面、代表性的数据。其次,进行数据收集与分析。实时收集监测站点的交通流量数据,并进行质量控制和校准。利用数据分析技术处理和整理数据,去除异常值和噪音。利用机器学习和人工智能方法对交通流量数据进行分析和建模,使用历史数据进行训练,通过优化算法(如梯度下降)来调整模型的参数,建立预测模型。常见的算法包括回归模型、支持向量机(svm)和决策树等。最后,结合实时监测数据和预测模型,进行交通流量的预测。这样,公众和相关部门可以方便地获取准确、及时的交通流量信息。
3、虽然交通流量预测任务在实践中取得了一定的成就,但仍然存在一些问题和挑战。交通流量预测通常使用多个传感器节点收集数据,这些节点可以包括交通流量监测器、摄像头、雷达等。每个传感器节点收集的数据与其他节点的数据存在多变量关系,这些关系可能是非线性的、时变的或非常复杂的。例如,不同节点的交通流量可能受到相似的影响因素,如天气、道路状况和特殊事件,但它们的具体联系可能因节点位置、监测范围和传感器特性而异。因此,准确建模和预测传感器节点之间的多变量关系是一个具有挑战性的任务,尤其是在分布漂移的情况下。交通流量监测节点可能由于城市建设、道路改变或交通流量分布的变化而导致数据分布发生漂移。这种漂移会影响预测模型的准确性和稳定性。因此,使用历史数据训练的模型可能无法准确地适应新的环境条件,导致预测性能下降。
4、[参考文献]
5、[1]shi x,chen z,wang h,et al.convolutional lstm network:a machinelearning approach for precipitation nowcasting[j].advances in neuralinformation processing systems,2015,28.
6、[2]guo s,lin y,feng n,et al.attention based spatial-temporal graphconvolutional networks for traffic flow forecasting[c]//proceedings of theaaai conference on artificial intelligence.2019,33(01):922-929.
7、[3]song c,lin y,guo s,et al.spatial-temporal synchronous graphconvolutional networks:a new framework for spatial-temporal network dataforecasting[c]//proceedings of the aaai conference on artificialintelligence.2020,34(01):914-921.
技术实现思路
1、本发明针对上述现有技术中不足的问题,本发明提出一种基于图神经网络和分布表征匹配的交通流量预测方法,该方法考虑到了数据的分布漂移特性,基于图神经网络和分布表征匹配算法能够充分地挖掘非平稳交通数据中各节点之间的关联关系,构建了具有良好泛化效果的模型。
2、为了解决上述技术问题,本发明提出的交通流量预测方法的步骤如下:
3、步骤1)数据准备,包括:使用传感器设备,在交通路段和交叉口部署传感器节点;确保传感器能够准确地捕捉到经过该位置的车辆信息;将传感器与数据采集系统进行连接,接收数据并存储到数据库;随后,按照7:2:1的比例划分训练集、验证集、测试集;
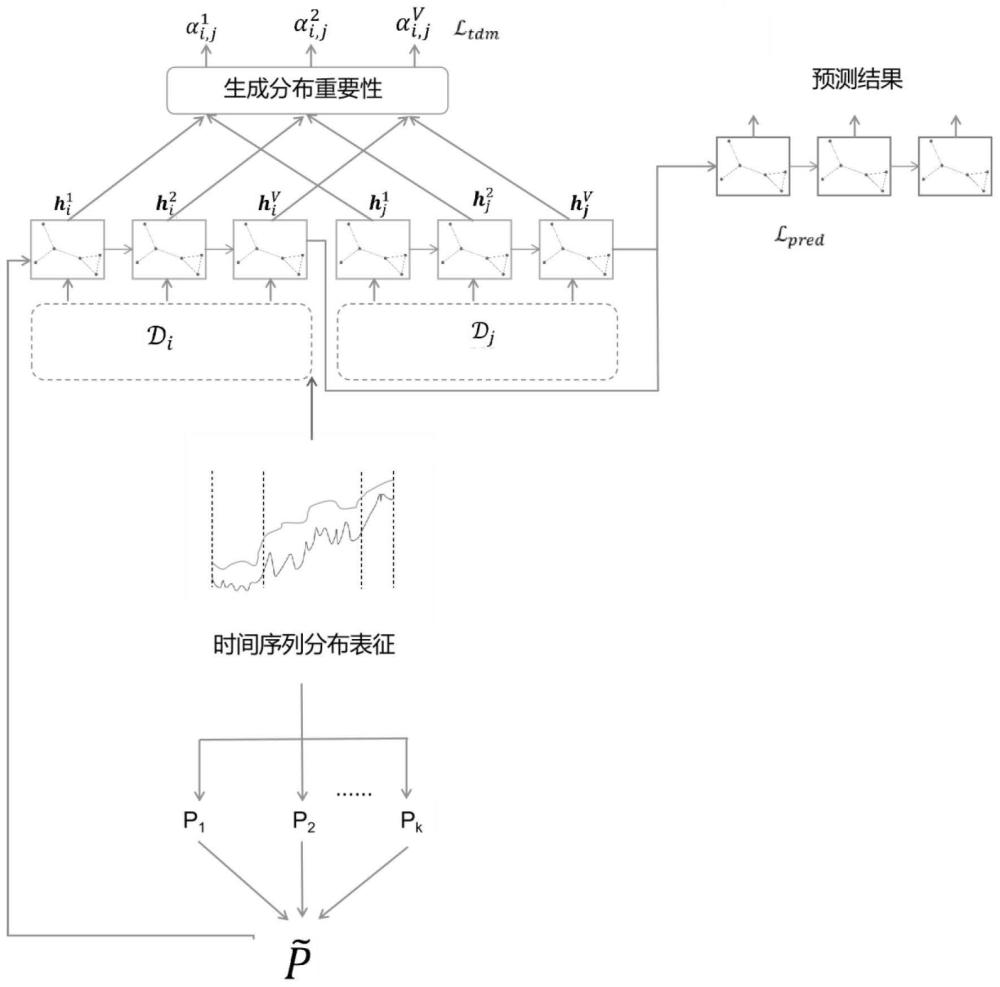
4、步骤2)时间序列分布表征,包括:根据分布距离最大化,对训练集的历史交通流量数据划分出不同的子域,即进行分段操作,以满足下式:
5、
6、式(1)中,i,j表示段的标号,表示对交通流量划分后的第i段流量数据,表示对交通流量划分后的第j段流量数据,d(·)是基于分布的距离度量函数mmd(maximum meandiscrepancy)最大均值差异;φ表示该步骤一共将原始序列分成φ段;
7、步骤3)自适图结构学习,包括:构造出一个融合多子域信息的邻接矩阵用于表示各路口数据之间的影响关系;首先,对于分布表征划分出的每个子域都构造其特定的子域图;假设当前处理的子域下标为k,其对应的子域图为pk,用皮尔逊相关系数构造邻接矩阵对子域图pk进行初始化,图中每个元素的计算方式如下:
8、
9、式(2)中,pk(i,j)代表子域图pk第i行j列个元素,代表当前子域中第i个节点的数据;代表当前子域中第j个节点的数据;cov代表协方差,var代表方差;所有子域图在训练时随着样本的迭代而更新优化;随后,用一组可学习的参数mk对各子域图pk进行融合,生成最终的图结构:
10、
11、步骤4)特征提取,具体为:将gcn(graph convolutional network)图卷积神经网络融入gru(gate recurrent unit)门控循环单元形成的gcru(graph convolutionalrecurrent unit)图卷积循环单元作为时空特征编码网络;具体内容如下:
12、用gcn(graph convolutional network)图卷积神经网络捕获交通流量时间序列的空间依赖性,如式(4),
13、
14、式(4)中,x代表输入的交通流量时间序列,h代表gcn输出的隐藏特征,代表图卷积操作,θ和wk代表用切比雪夫多项式近似的核参数;代表邻接矩阵;σ代表激活函数,k代表图卷积的阶数;
15、用gru(gate recurrent unit)门控循环单元捕获交通流量时间序列的时间依赖性;
16、将gcn(graph convolutional network)图卷积神经网络融入gru(gaterecurrent unit)门控循环单元形成gcru(graph convolutional recurrent unit)图卷积循环单元即为时空特征编码网络,该时空特征编码网络结构如式(5):
17、
18、式(5)中,u、r和c分别表示gru门控循环单元中的更新门、复位门和候选状态,θ{u,r,c}代表门参数,b{u,r,c}代表偏置项,⊙代表哈达玛积,ht代表gcru输出的隐藏特征;
19、步骤5)时间序列分布匹配,具体为:计算分布匹配损失
20、
21、式(6)中,表示段在时间步t下的隐藏特征,表示段在时间步t下的隐藏特征;假设每段共有v个时间步,表示时间步t下段和段之间的分布重要性,对于同一层gcru层,段和段之间的分布重要性αi,j可初始化为相同的值:
22、
23、步骤6)模型训练,具体为:使用训练集对模型进行训练,并进行参数调整和优化,保存在验证集上的最优模型,以提高模型在测试集上的性能;模型的整体损失函数如下式
24、
25、其中,λ是一个权衡超参数,用于控制分布匹配损失占总损失的权重,第二项中代表需计算所有成对子域的分布匹配损失的平均值;代表模型的预测损失:
26、
27、其中,θ表示模型的参数,表示中的第i个样本,l代表损失函数,m代表模型;
28、步骤7)使用训练好的模型对测试集中的数据进行预测,得到未来交通流量预测结果。
29、与现有技术相比,本发明的有意效果是:由于本发明预测方法中,考虑了数据的分布漂移特性并采用融合多子域信息的图结构挖掘交通数据中各节点之间的关联关系,而现有技术中常用的预测方法[1-3]均为基线方法,未能够考虑数据的分布漂移特性且未能准确捕捉关联关系,因此,本发明预测方法的预测结果明显好于上述现有技术中的基线方法的预测结果。
本文地址:https://www.jishuxx.com/zhuanli/20240731/189683.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表