基于用户行为的恶意爬虫识别方法及装置、介质、设备与流程
- 国知局
- 2024-08-02 14:05:04
本发明涉及爬虫识别,尤其是涉及一种基于用户行为的恶意爬虫识别方法及装置、介质、设备。
背景技术:
1、网络爬虫又称为网页蜘蛛、网络机器人,更经常的称为网页追逐者,是一种按照一定的规则自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、索自动索引、模拟程序或者蠕虫。像baidu spider这样的爬虫,我们称之为善意爬虫。这种爬取网站内容的行为,不仅没有害处,反而会让自己的网站被收录,获得来自搜索引擎的流量。但是有一些爬虫却是恶意的,它们对网站不仅没有好处,反而形成一股阻力,妨碍网站正常业务的开展。由于恶意爬虫通常只针对某一个网站,因此网站核心内容,可能在短短几分钟内,就会被恶意爬虫抓取,并悄无声息的复制到其他网站,这一过程可能比搜索引擎的爬虫更快。从而影响网站在搜索引擎中的排名,导致访问量、销量、广告收益降低。
2、竞争对手通过恶意爬虫窃取目标网站的商品价格、详情信息等内容,用于同类产品线价格的研究,从而为打价格战奠定基础。毫无疑问这样的窃取行为,会让自己的网站在竞争中出于劣势,进而影响商品销量,损失客户。恶意爬虫在注册页面不断输入号码,一旦显示“该用户已注册”,则将这一账号信息保存。恶意爬虫通过这一方法,拿到用户注册网站的手机号,打包贩卖。这时,用户可能认为是网站将信息卖给第三方,而不是恶意爬取,严重损害企业品牌及形象。
3、在当前的技术背景下,企业检测爬虫的方式一般为通过检测ip设置黑白名单或者检测user-agent,再或者是验证码校验。新型的恶意爬虫往往拥有海量的ip代理池,即使一个ip倒了还有千千万万个ip可以用,也可以通过模拟器来控制浏览器,验证码也可以通过一些验证码校验平台来识别,例如超级鹰。在这种情况下,我们的站点往往无法正确并有效地筛选出恶意爬虫,变得十分脆弱。
技术实现思路
1、针对以上至少一个技术问题,本发明实施例提供一种基于用户行为的恶意爬虫识别方法及装置、介质、设备。
2、根据第一方面,本发明实施例提供的基于用户行为的恶意爬虫识别方法包括:
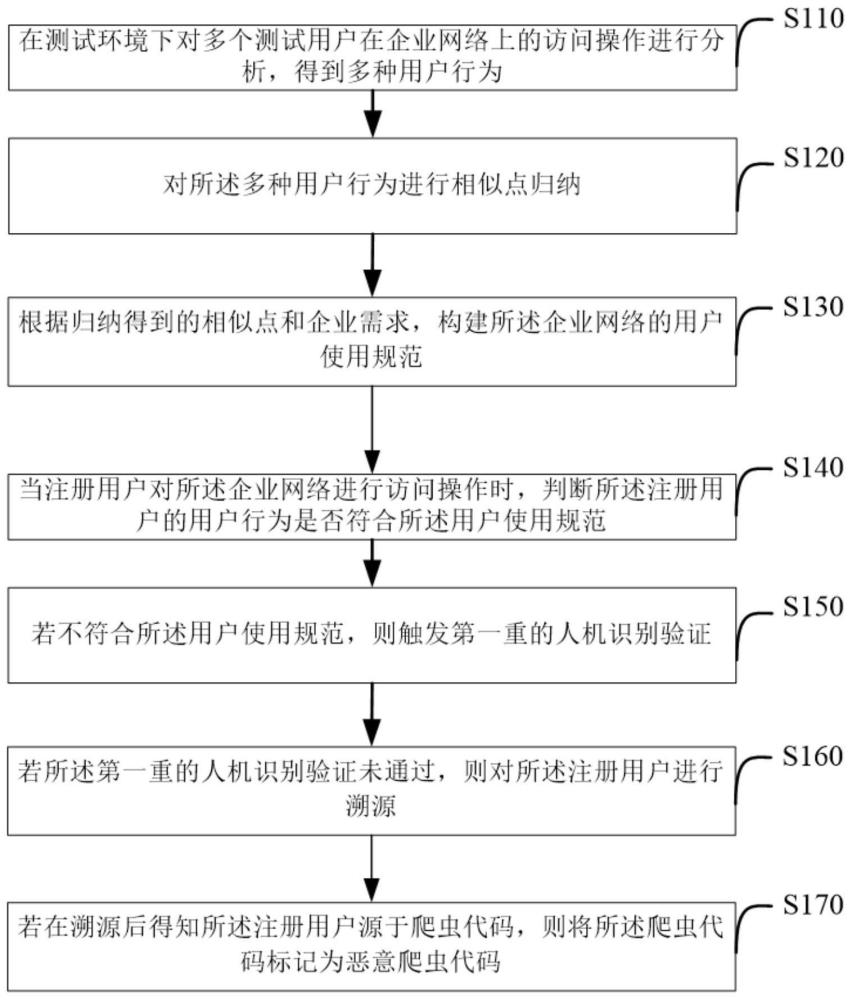
3、在测试环境下对多个测试用户在企业网络上的访问操作进行分析,得到多种用户行为;
4、对所述多种用户行为进行相似点归纳;
5、根据归纳得到的相似点和企业需求,构建所述企业网络的用户使用规范;
6、当注册用户对所述企业网络进行访问操作时,判断所述注册用户的用户行为是否符合所述用户使用规范;
7、若不符合所述用户使用规范,则触发第一重的人机识别验证;
8、若所述第一重的人机识别验证未通过,则对所述注册用户进行溯源;
9、若在溯源后得知所述注册用户源于爬虫代码,则将所述爬虫代码标记为恶意爬虫代码。
10、在一个实施例中,本发明实施例提供的方法还包括:
11、记录所述注册用户在所述企业网络的每一个应用场景下进行基本身份信息验证的单日验证次数;
12、若所述注册用户针对一个应用场景的所述单日验证次数超出针对该应用场景预先设定的单日验证次数阈值,则对所述注册用户进行异常标记,并触发第二重的人机识别验证;
13、若所述第二重的人机识别验证未通过,则对所述注册用户进行溯源;
14、若在溯源后得知所述注册用户源于爬虫代码,则将所述爬虫代码标记为恶意爬虫代码。
15、在一个实施例中,本发明实施例提供的方法还包括:
16、根据所述注册用户在每一应用场景下的所述单日验证次数,生成该应用场景对应的第一月报表,并将所述第一月报表发送至前端进行展示。
17、在一个实施例中,本发明实施例提供的方法还包括:
18、记录所述注册用户在所述企业网络的每一个应用场景下的单日浏览次数;
19、若所述注册用户针对一个应用场景的所述单日浏览次数超出针对该应用场景预先设定的单日浏览次数阈值,则对所述注册用户进行异常标记,并触发第三重的人机识别验证;
20、若所述第三重的人机识别验证未通过,则对所述注册用户进行溯源;
21、若在溯源后得知所述注册用户源于爬虫代码,则将所述爬虫代码标记为恶意爬虫代码。
22、在一个实施例中,本发明实施例提供的方法还包括:
23、根据所述注册用户在每一应用场景下的所述单日浏览次数,生成该应用场景对应的第二月报表,并将所述第二月报表发送至前端进行展示。
24、在一个实施例中,在每一重的人机识别验证中,对所述注册用户进行验证码和基本身份信息的验证,若验证码的验证未通过和/或所述基本身份信息的验证未通过,则所述人机识别验证未通过;若所述验证码的验证和所述基本身份信息的验证均通过,则所述人机识别验证通过。
25、在一个实施例中,本发明实施例提供的方法还包括:
26、确定所述注册用户在预设时间段内个人空间的开放时间段的占比;
27、若所述占比超出各个测试用户的平均占比,则对所述注册用户在所述企业网络上的各个应用场景的浏览情况进行归纳分析,得到所述注册用户的浏览方向;
28、在所述企业网络上检索与所述浏览方向相关的官方发布消息;
29、若在所述企业网络上未检索到与所述浏览方向相关的官方发布消息,则对所述注册用户的个人空间进行异常标记,并对被标记为异常的所述注册用户进行深层身份信息的验证;
30、若所述深层身份信息的验证未通过,则将所述注册用户的个人空间关闭,并对所述注册用户进行溯源;
31、若在溯源后得知所述注册用户源于爬虫代码,则将所述爬虫代码标记为恶意爬虫代码。
32、根据第二方面,本发明实施例提供的基于用户行为的恶意爬虫识别装置包括:
33、行为分析模块,用于在测试环境下对多个测试用户在企业网络上的访问操作进行分析,得到多种用户行为;
34、相似归纳模块,用于对所述多种用户行为进行相似点归纳;
35、规范确定模块,用于根据归纳得到的相似点和企业需求,构建所述企业网络的用户使用规范;
36、行为判断模块,用于当注册用户对所述企业网络进行访问操作时,判断所述注册用户的用户行为是否符合所述用户使用规范;
37、第一验证模块,用于若不符合所述用户使用规范,则触发第一重的人机识别验证;
38、第一溯源模块,用于若所述第一重的人机识别验证未通过,则对所述注册用户进行溯源;
39、第一标记模块,用于若在溯源后得知所述注册用户源于爬虫代码,则将所述爬虫代码标记为恶意爬虫代码。
40、根据第三方面,本发明实施例提供计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行实现第一方面提供的方法。
41、根据第四方面,本发明实施例提供的计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现第一方面提供的方法。
42、本发明实施例提供的基于用户行为的恶意爬虫识别方法及装置、介质、设备,首先基于大量的用户行为构建用户使用规范,然后在一个注册用户的用户行为不符合用户使用规范时,触发人机识别验证,当人机识别验证不通过时,对注册用户进行溯源,如果溯源发现注册用户源于爬虫代码,则将爬虫代码标记为恶意爬虫代码。可见,本发明实施例提供的方法基于注册用户的用户行为实现,不论恶意爬虫的ip代理池中有多少个ip可以使用,都可以一一甄别。而且基于人机识别验证、溯源等进一步确认,以保证恶意爬虫的准确识别,降低了误识别的概率,不会对正常用户造成误伤。
本文地址:https://www.jishuxx.com/zhuanli/20240801/241671.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表