基于掩码自动编码器预训练的恶意流量检测方法与流程
- 国知局
- 2024-08-02 14:42:47
本发明涉及网络空间安全与人工智能,具体来说是基于掩码自动编码器预训练的恶意流量检测方法。
背景技术:
1、如何更有效的识别恶意流量一向是研究者关注的重点,目前对恶意流量识别的研究方法主要分为三类:基于规则的方法、机器学习方法、深度学习方法。流量识别方法也经历了从基于规则的方法到机器学习方法、深度学习方法,再到多种方法并行的发展。早期的研究主要使用基于规则的方法来识别恶意流量,即利用流量数据的通讯协议、端口号、报文长度等基本属性的特征人工制定安全规则来检查异常行为。随着网络环境的发展,基于规则的方法暴露出对专家知识需求高,耗时长,难以反应新的流量加密与匿名技术等缺陷,无法满足安全人员对流量分析的需求。
2、为了适应新的网络环境下复杂的流量数据,研究者引入机器学习领域的算法来识别流量数据的高维特征。如appscanner采用随机森林(random forest, rf)对流量产生的各种统计特征(最大最小值,平均,方差等)进行分析;cumul通过将从原始流量数据计算得到的104个统计特征输入支持向量机(svm)进行流量分类。采用机器学习方法可以对复杂的流量数据进行有效分析,但这些方法依然依赖于专家设计的流量统计特征,且不同实际应用场景下特征的表现不稳定,需要手动选择调节。
3、与上述方法不同,基于深度学习的方法在分析流量时不需要事先设定的人为特征,而是利用深度学习方法直接进行端到端的分析分类,目前已经成为自动提取流量特征并改进流量检测效果方向的研究重点,应用的深度学习方法包括卷积神经网络(cnn)、递归神经网络(rnn)、长短期记忆网络()等。
4、流量识别中的深度学习方法能够忽略随机流量复杂的加密情况,最大限度避免采用专家知识导致的人力损耗与模型迁移问题。然而此类方法目前尚有对数据利用不完善,需求带标签数据量大、训练耗时长等缺陷,为这些方法的实际应用造成了阻碍。
技术实现思路
1、本发明的目的是为了解决现有技术中难以针对恶意流量进行有效检测的缺陷,提供一种基于掩码自动编码器预训练的恶意流量检测方法来解决上述问题。
2、为了实现上述目的,本发明的技术方案如下:
3、一种基于掩码自动编码器预训练的恶意流量检测方法,包括以下步骤:
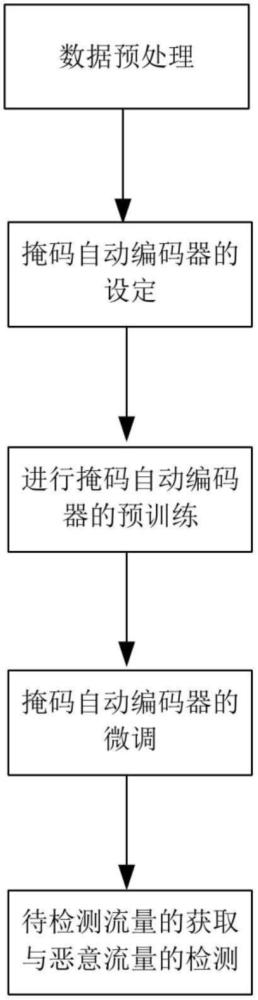
4、数据预处理:将流量数据进行分类,分成无标记数据、带标签数据,对无标记数据进行预处理为二维表示矩阵;
5、掩码自动编码器的设定:设定掩码自动编码器包括掩码模块、流量特征编码模块与投影模块三部分;
6、进行掩码自动编码器的预训练:利用二维表示矩阵对掩码自动编码器进行预训练;利用掩码模块生成随机掩码来构建增强样本,再利用流量特征编码模块进行特征提取,得到特征向量;再将特征向量利用投影模块输入并投影至单位球上进行对比学习;
7、掩码自动编码器的微调:利用带标签数据对预训练后的掩码自动编码器进行微调;
8、待检测流量的获取与恶意流量的检测:获取待检测流量,形成待检测的无标签数据,并输入微调后的掩码自动编码器,获得恶意流量的检测结果。
9、所述数据预处理包括以下步骤:
10、根据ip地址、端口号和协议类型将原始流量数据化分成流,然后删除流级及以上的封装信息,将端口号设置为零,并将各ip替换为保留收发方向随机地址,生成流量数据;
11、对流量数据进行分类,分成无标记数据、带标签数据;
12、对无标记数据进行预处理:
13、根据流量数据的特性,将表示矩阵分为流量包头行和负载行,流量包头行只包含流量的包头部分字节,而负载行只包含流量的负载部分字节;
14、针对每个流量数据包进行处理:
15、预设包级矩阵大小参数n、h、w,用每个流中前n个数据包生成大小固定为h*w的二维矩阵作为该数据流的表示矩阵;
16、对于每条流取其中前n个数据包,每个数据包生成大小固定为h * w的包级矩阵,这个包级矩阵由固定大小与位置的报头矩阵和有效载荷矩阵组成,如果有效载荷矩阵中有效字节数或数据包数不足,在不足位置用零进行填充,以确保每个包级矩阵的大小一致;
17、将得到的n个包级矩阵依序进行纵向堆叠,形成整条流最终的二维表示矩阵m,若该流数据包不足n个,进行用零填充矩阵。
18、所述进行掩码自动编码器的预训练包括以下步骤:
19、对二维表示矩阵m,通过生成随机掩码来构建增强样本,进行数据增强处理:
20、预设掩码率为k,生成与输入矩阵大小相同的二维屏蔽矩阵mask,在随机位置填入k个零,其余位置皆为1,多次生成屏蔽样本用来扩充表示矩阵的数量;屏蔽样本的生成用下式表示:
21、,
22、其中,乘号为hadamard积;
23、设定流量特征编码模块包括嵌入模块、包级提取模型和流级提取模块;
24、嵌入模块用于将屏蔽样本输入得到其补丁向量,
25、包级提取模型用于将嵌入模块生成的补丁向量输入包级提取模块的自注意编码器得到包级特征,
26、流级提取模块用于在包级提取模块输出的包级特征上添加流级别的特征,将包级提取模块的输出补丁的特征逐行池化生成行补丁,然后将行补丁输入自注意编码器得到列级特征,再将列级特征逐列池化得到最终的特征向量;
27、嵌入模块将屏蔽样本分割为固定大小的不重叠二维矩阵小块,然后用神经网络的线性层将这些不重叠二维矩阵小块映射为d维的嵌入补丁向量,这里d是预设的向量维数,最后将不重叠二维小块在表示矩阵的位置添加到嵌入补丁向量xl以保持位置信息,得到的嵌入补丁向量分为报头补丁或负载补丁;
28、包级提取模块的自注意编码器由多头自注意层msa和前反馈层交替组成,将嵌入模块得到的嵌入补丁向量输入包级提取模块以提取包级特征,
29、多头自注意层msa利用注意力函数计算每个嵌入补丁向量的头部,并根据每个嵌入补丁向量的头部学习不同补丁之间的关联程度,前反馈层通过线性变换,先映射到高维空间再映射到低维空间的方式提取更深层次的特征;
30、记为预设的注意力函数输出规模,wq、wk、wv∈为学习的网络参数,为嵌入补丁向量,注意力函数计算如下所示:
31、
32、,
33、其中,为注意力函数的中间过程矩阵;
34、流级提取模块对包级提取模块输出的嵌入补丁向量特征逐行池化生成行补丁;
35、将行补丁重新输入包级提取模块的自注意编码器提取嵌入补丁向量的列级特征;
36、最后,流级提取模块将得到的列级特征进行逐列池化得到整个表示矩阵的最终特征向量,记为lf;
37、设定投影模块,
38、设定投影模块包括由两个线性层和一个relu激活函数层所构成的全连接层,在数据输入前与输出后对其进行归一化处理;
39、投影模块将最终特征向量lf进行最大最小归一化,形成一个标准化的矢量表示,然后将该矢量表示通过全连接层来输出嵌入的特征表示,即输出向量,再将输出向量归一化为单位球上的一个向量;
40、记单位球上两个向量之间的余弦相似度为两个向量的点积,并定义如下损失函数以完成训练:
41、给定样本x作为锚点,记是来自与x相同样本的增强数据,是来自与x不同样本的增强数据,为确保相似样本对(x,)彼此接近,而不同样本对(x,)彼此远离,根据余弦相似度将对比损失函数定义为:
42、
43、其中,锚点r表示被投影模块投影到单位球后的样本x,其不同脚标代表来自不同的集合,i表示来自全样本集,p表示来自锚点ri的所有相似样本对(x,)构成的集合p(i),a表示来自锚点ri的所有样本对构成的集合a(i),loss公式里的点乘为计算余弦相似度;
44、对比损失函数通过比较正负样本对的余弦相似度,使正样本对(x,)余弦相似度最大、负样本对(x,)的余弦相似度最小来识别流量;
45、投影模块将特征向量lf映射为单位球上的一个点,随后使用向量点积得到的余弦相似度来度量两个向量之间的相似度:相似度越高的样本对应的特征向量在单位球上的距离越小;
46、完成掩码自动编码器的预训练,将得到的参数进行保存。
47、所述掩码自动编码器的微调包括以下步骤:
48、将带标签数据输入预训练后的掩码自动编码器进行微调训练,经过掩码模块、流量特征编码模块和投影模块;
49、在掩码自动编码器的投影模块中最后一个全连接层进行流量分类,并在投影阶段中令对比损失函数最大,即同标签样本对的余弦相似度最大、不同标签样本对的余弦相似度最小来识别流量。
50、有益效果
51、本发明的基于掩码自动编码器预训练的恶意流量检测方法,与现有技术相比采用了更有效的流量数据处理方式保留了更多流的信息,用掩码增强数据使模型对数据量的需求大幅降低,流量特征编码中按包级流级两个维度更有效的提取数据特征,采用包括掩码、投影的对比学习方法充分提取不同种类流量的区别特征,并利用预训练方法增强模型的迁移能力,降低了实际运行的开销,可以有效地识别恶意流量。
52、本发明通过预训练方法将流量数据有效转换为二维表示矩阵后输入预训练模型,通过掩码增强、流量特征编码提取特征、投影到单位球完成对比学习,保留预训练参数至下游任务。本发明所述方法能够大幅减轻传统深度学习对数据量的需求,有效提取流量数据的身份信息,利用少量数据达成优秀的识别准确率,并在提高流量识别效率的同时具有良好的迁移学习能力。
本文地址:https://www.jishuxx.com/zhuanli/20240801/243722.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。