基于强化学习的固定数据传输DSA方法
- 国知局
- 2024-08-02 14:43:07
本发明涉及一种认知无线电技术,尤其是涉及一种基于强化学习的固定数据传输dsa(dynamic spectrum access,动态频谱接入)方法,其适用于使用填充式传输模型如oma(orthogonal multiple access,正交多址接入)的dsa网络,其通过强化学习算法训练次级用户(su,secondary user)的智能体,以实现在dsa网络中保证主用户(pu,primary user)优先级的情况下,最大化自己的传输效率。
背景技术:
1、随着第五代无线通信技术(5g)的迅猛进步,无线设备的数量正通过无线电接入网络实现急剧增长,这进一步加剧了人们对无线通信服务的需求。尽管毫米波通信的研究日益受到重视,但其高频段特性导致的穿透能力不足和覆盖区域有限等问题依然显著。若依赖毫米波通信实现广泛覆盖,则将面临巨大的成本挑战。因此,在5g及物联网(iot)的演进中,提高中低频段的频谱效率同样至关重要。于是,认知无线电(cr,cognitive radio)应运而生,其中动态频谱接入(dsa)应用最为广泛。dsa是一种允许无线频谱更加高效使用的技术。在dsa中,一段频谱被分配给一个主用户,而主用户对频谱的使用具有最高的优先权。然而,这并不意味着频谱被主用户独占。当主用户没有使用这段频谱时,次级用户也可以使用或共享这段频谱,前提是不干扰主用户的正常使用。考虑到物联网(iot)在信息传递中的核心作用,确保物联网(iot)实体(如基站和车辆)之间建立稳固的通信链路已成为一项迫切需求。这就要求dsa网络具备高效的频谱分配策略。然而,在如此竞争激烈的场景中,设计恰当的连接策略殊为不易。每个md(移动设备)必须能够准确感知系统状态,以适应不断变化的环境动态,这包括移动设备移动模式的变迁、网络运行概况的核心特征,以及单一移动设备决策对其他设备产生的连锁效应。主用户的存在,次级用户在访问授权带宽资源时呈现出间断性,这始终需要维护主用户的优先权。
2、针对dsa提出了很多研究工作。最初被提出的信道接入方法是随机接入方法(random access),这种方法存在一个显著的缺点,即主用户与次级用户之间以及次级用户相互之间的碰撞率非常高。为了克服随机接入方法的这一缺陷,有人提出了一种myopic频谱接入方法,这种方法有效地降低了碰撞率,但是这种方法因为其“短视”策略,获得的效果并不好。也有一些研究是基于博弈论或者数学优化方法的dsa(如最小二乘法),但是这些方法通常与场景紧密相关,在其他场景中使用就需要重新设计模型,没有通用性。将强化学习应用于dsa,不仅可以得到良好的效果,而且不依赖于场景,具有通用性,所以,使用q学习或者深度q学习来进行动态频谱接入成为了主流,然而这两种算法在次级用户数量过多,或者状态信息无法完整获得的场景中效果很差,甚至会无法收敛。此外,现有的研究工作通常会假设次级用户始终处于“满载”状态,即始终有数据需要传输或接收,但在实际应用中,次级用户的数据传输需求是有限的,并且在传输完成后,现有方法往往依赖于训练来告知用户“何时停止传输”,这与实际情况脱节。更为复杂的是,当某些智能体完成传输并停止活动后,剩余次级用户所面临的环境也随之改变。
技术实现思路
1、本发明所要解决的技术问题是提供一种基于强化学习的固定数据传输dsa方法,其适用于使用填充式传输模型的dsa网络,在dsa网络中,每个次级用户拥有固定大小的数据包需要传输,其通过强化学习算法训练次级用户的智能体,以实现在dsa网络中保证主用户优先级的情况下,使次级用户接入正交信道进行数据传输,并最大化传输效率,尽可能快地完成数据传输,能够降低复杂度,更易收敛,得到的效果更好;另外,使已经传输完成的次级用户直接停止传输,能够节省不必要的信息开销。
2、本发明解决上述技术问题所采用的技术方案为:一种基于强化学习的固定数据传输dsa方法,其特征在于包括以下步骤:
3、步骤1:在认知无线电系统的dsa网络中,设定使用填充式传输模型进行数据传输,且数据传输采用时隙传输方式;设定共有一个主基站、m个主用户、n个次级用户,主基站配备有m个正交信道,m个正交信道被一一对应授权给m个主用户,每个次级用户带有一个智能体;定义连续的t个时隙为一个周期,由连续的t个时隙构成一个请求间隔;其中,m≥1,n≥1;
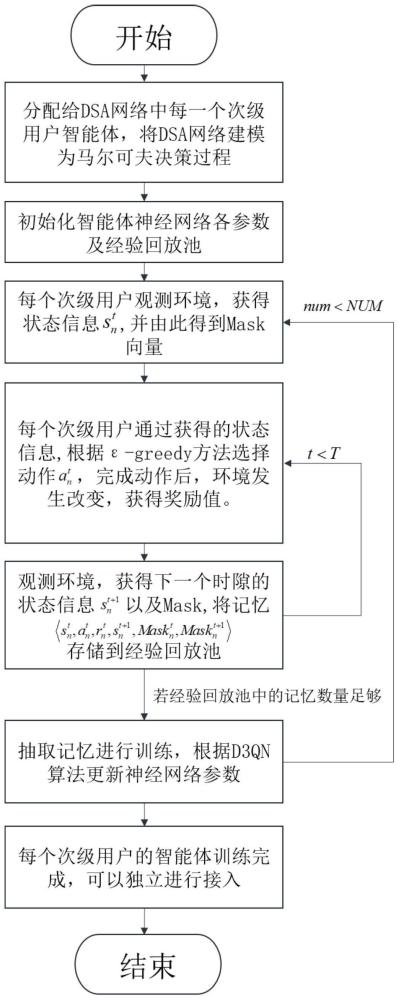
4、步骤2:将dsa网络建模为马尔可夫决策过程,在马尔可夫决策过程中,每个次级用户的智能体与一个环境交互,每个次级用户的智能体在一个时隙开始前观测环境获得观测状态,之后根据观测状态和策略,每个次级用户的智能体在这个时隙内从动作空间中选择一个动作,在动作完成后环境会发生改变,同时每个次级用户的智能体在这个时隙内得到奖励值,从而完成这个时隙的数据收集过程;其中,策略本质上是一个概率分布,用于反映观测状态下选择每个动作的概率,是次级用户的智能体在这个时隙内选择一个动作的依据;
5、步骤3:在将dsa网络建模为马尔可夫决策过程后,使用深度强化学习d3qn算法同时进行所有次级用户的智能体的训练阶段,具体过程如下:
6、步骤3.1:初始化所有次级用户的智能体使用的深度强化学习d3qn算法的算法参数;初始化所有次级用户的智能体各自对应的经验回放池;设定训练阶段共进行num个请求间隔;其中,num>1;
7、步骤3.2:对于第num个请求间隔,将这个请求间隔的第t个时隙作为当前时隙,每个次级用户的智能体在当前时隙开始前观测环境获得观测状态,第n个次级用户的智能体在当前时隙开始前观测环境获得的观测状态为中包含有由第t个时隙内所有正交信道的占用状态组成的向量ct和在当前时隙开始前第n个次级用户还剩余的需传输的数据的大小其中,num的初始值为1,1≤num≤num,t的初始值为1;
8、步骤3.3:根据每个次级用户的智能体在当前时隙开始前观测环境获得的观测状态,获取对应的mask向量,将对应的mask向量记为其中,ones(m)表示一个维度为1×m的全1行向量;
9、步骤3.4:根据每个次级用户的智能体在当前时隙开始前观测环境获得的观测状态,并使用∈-greedy方法,每个次级用户的智能体在当前时隙内从动作空间中选择一个动作,第n个次级用户的智能体在当前时隙内从动作空间中选择的动作为然后每个次级用户的智能体在当前时隙内做出动作,在动作完成后环境会发生改变,同时每个次级用户的智能体在当前时隙内得到奖励值,第n个次级用户的智能体在当前时隙内得到的奖励值为接着每个次级用户的智能体在当前时隙的末尾即下一个时隙开始前观测环境获得观测状态,第n个次级用户的智能体在当前时隙的末尾即下一个时隙开始前观测环境获得的观测状态为中包含有由第t+1个时隙内所有正交信道的占用状态组成的向量ct+1和在第t+1个时隙开始前第n个次级用户还剩余的需传输的数据的大小再根据每个次级用户的智能体在当前时隙的末尾即下一个时隙开始前观测环境获得的观测状态,获取对应的mask向量,将对应的mask向量记为
10、步骤3.5:每个次级用户的智能体在当前时隙内将自身的记忆存储在自身的经验回放池中;其中,第n个次级用户的智能体在当前时隙的记忆为
11、步骤3.6:每个次级用户的智能体根据检查数据是否已传输完毕,已传输完毕的次级用户的智能体停止,并等待其他未传输完毕的次级用户的智能体继续传输数据,对于第n个次级用户的智能体,若数据未传输完毕,则令t=t+1,将这个请求间隔的第t个时隙作为当前时隙,然后返回步骤3.4继续执行;在这个请求间隔结束时,即使有次级用户的智能体还有数据未传输完毕也停止,再执行步骤3.7;其中,t=t+1中的“=”为赋值符号;
12、步骤3.7:对于第n个次级用户的智能体,若第n个次级用户的智能体的经验回放池中的记忆已达到预设训练数量,那么第n个次级用户的智能体从自身的经验回放池中按预设训练数量随机抽取记忆;然后将抽取的所有记忆输入到深度强化学习d3qn算法的估计网络中,对估计网络进行训练,训练过程中估计网络获得每条记忆对应的q估计值,同时将抽取的所有记忆输入到深度强化学习d3qn算法的目标网络中,目标网络得到每条记忆对应的q目标值;再使每条记忆对应的q估计值和q目标值均经过softmax后乘以得到每条记忆对应的新q估计值和新q目标值;之后根据每条记忆对应的新q估计值和新q目标值,计算每条记忆对应的损失,并更新估计网络的网络参数;最后将估计网络的更新后的网络参数复制到目标网络中后执行步骤3.8;
13、若第n个次级用户的智能体的经验回放池中的记忆未达到预设训练数量,那么不进行训练,直接执行步骤3.8;
14、步骤3.8:令num=num+1,令t=1,然后返回步骤3.2继续执行,直至num个请求间隔结束,完成了所有次级用户的智能体的训练阶段,得到了每个次级用户的智能体对应的训练好的d3qn模型;其中,num=num+1中的“=”为赋值符号;
15、步骤4:将训练好的d3qn模型用于实施阶段,在实施阶段中,对于第n个次级用户的智能体,根据其对应的训练好的d3qn模型,自行在一个时隙开始前观测环境获得观测状态,在这个时隙内从动作空间中选择一个动作,并做出动作。
16、所述步骤2中,将第n个次级用户的智能体在第t个时隙开始前观测环境获得的观测状态表示为其中,n=1,2,…,n,t=1,2,…,t,当t=1时即为为未包含在动作空间中的一个动作,当t>1时表示第n个次级用户的智能体在第t个时隙内从动作空间中选择的动作,当t=1时即为当t>1时表示第n个次级用户的智能体在第t个时隙内接收到的ack信号,ct表示由第t个时隙内所有正交信道的占用状态组成的向量,ct中的每个元素的值为0或1,ct中的一个元素的值为0代表该元素对应的正交信道空闲,ct中的一个元素的值为1代表该元素对应的正交信道被占用,表示在第t个时隙开始前第n个次级用户还剩余的需传输的数据的大小,time表示当前的请求间隔中经过的时隙数,即time等于t。
17、所述步骤2中,将第n个次级用户的智能体在第t个时隙内从动作空间中选择的动作表示为根据第n个次级用户的智能体在第t个时隙内观测环境获得的观测状态和策略来选择,其中,时表示第n个次级用户的智能体在第t个时隙内没有选择接入正交信道,时表示第n个次级用户的智能体在第t个时隙内选择接入索引为m的正交信道,m=1,2,…,m。
18、所述步骤2中,将第n个次级用户的智能体在第t个时隙内得到的奖励值表示为如果第n个次级用户的智能体在第t个时隙内选择接入正交信道且成功接入,则如果第n个次级用户的智能体在第t个时隙内选择接入正交信道但接入的正交信道有其他次级用户也选择接入而未成功接入,则如果第n个次级用户的智能体在第t个时隙内没有选择接入正交信道,则其中,ν和u均为奖励权重,time表示当前的请求间隔中经过的时隙数,即time等于t,表示第n个次级用户在第t个时隙内向主基站发送的数据包的吞吐量,b表示正交信道的带宽,ptransmit表示次级用户的发射功率,表示第n个次级用户的智能体在第t个时隙内接入正交信道的信道增益,服从圆对称复高斯分布,dn表示第n个次级用户在当前的请求间隔内与主基站之间的距离,σ表示噪声的功率谱密度,ρ表示预设的负数的奖励值,η表示第n个次级用户的智能体在第t个时隙内能够得到的“分成奖励”的权重,η∈(0,1),表示取平均,表示其他成功接入的次级用户的智能体在第t个时隙内得到的奖励值之和。
19、所述步骤3中,深度强化学习d3qn算法包括估计网络和目标网络,估计网络和目标网络均由输入层、隐藏层和输出层组成,隐藏层包含两个全连接层和一个dueling层,两个全连接层的神经元个数都为256。
20、与现有技术相比,本发明的优点在于:
21、1)本发明方法在训练阶段引入了mask向量遮盖无法选择的动作,降低了选择动作和训练时的复杂度。此外,通过给奖励值一个渐变的加权值,使得前期传输成功获得的奖励值放大,鼓励尽快传输,从而使次级用户学习到尽快完成传输的策略。以上改进使深度强化学习d3qn算法更易收敛,也能训练到更好的效果。
22、2)本发明方法在训练阶段并不是让已经传输完成的次级用户通过学习来停止传输,这本身就是不符合实际的,而是直接停止次级用户的传输,节省了训练开销,也减少了不必要的传输功率消耗。
本文地址:https://www.jishuxx.com/zhuanli/20240801/243763.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表