空间音频渲染方法和装置与流程
- 国知局
- 2024-08-02 12:39:42
本技术涉及音频处理技术,尤其涉及一种空间音频渲染方法和装置。
背景技术:
1、在现实的三维空间中,声音可以具有方位感和空间感两种特性。空间音频技术通常是指实现在耳机等头戴播放设备上模拟前述两种特性的沉浸式音频体验的技术。人们对声音的方位感的判断主要受时间差、声级差、成长过程中学习到的人体滤波效应和头部晃动等因素的影响。其中,时间差、声级差、人体滤波效应这三个要素可以被综合的表述为头部相关传输函数(head related transfer functions,hrtf);头部晃动在各个方向上都对我们判断声源位置有着极大帮助。室内声场可以由直达声、早期反射声(earlyreflection,er)和后期混响声(late reverb,lr)组成,人们对声音的空间感主要是依据er和lr来建立的。
2、利用空间音频技术,可以将立体声、多声道环绕声、特殊制作的多对象音源等不同格式的声源渲染为双耳信号,即可在耳机上享受到真实的、沉浸式的听音体验。目前可以通过耳机中的陀螺仪等感应器进行头部跟踪(head tracking),进而把相应的旋转或位移变化体现在对声源的空间渲染中。
3、但是,空间音频渲染通常需要较大算力支撑,而且头动追踪需要较低时延。如果将空间音频渲染放在音频内容提供端(例如,手机、平板、pc等),虽可以满足算力需求,但会引入较高时延,尤其在头动场景下,会影响整体听音体验。
技术实现思路
1、本技术提供一种空间音频渲染方法和装置,以消除时延,从而使渲染效果正好与用户的头动位置相匹配,达成真实的、沉浸式的听音体验。
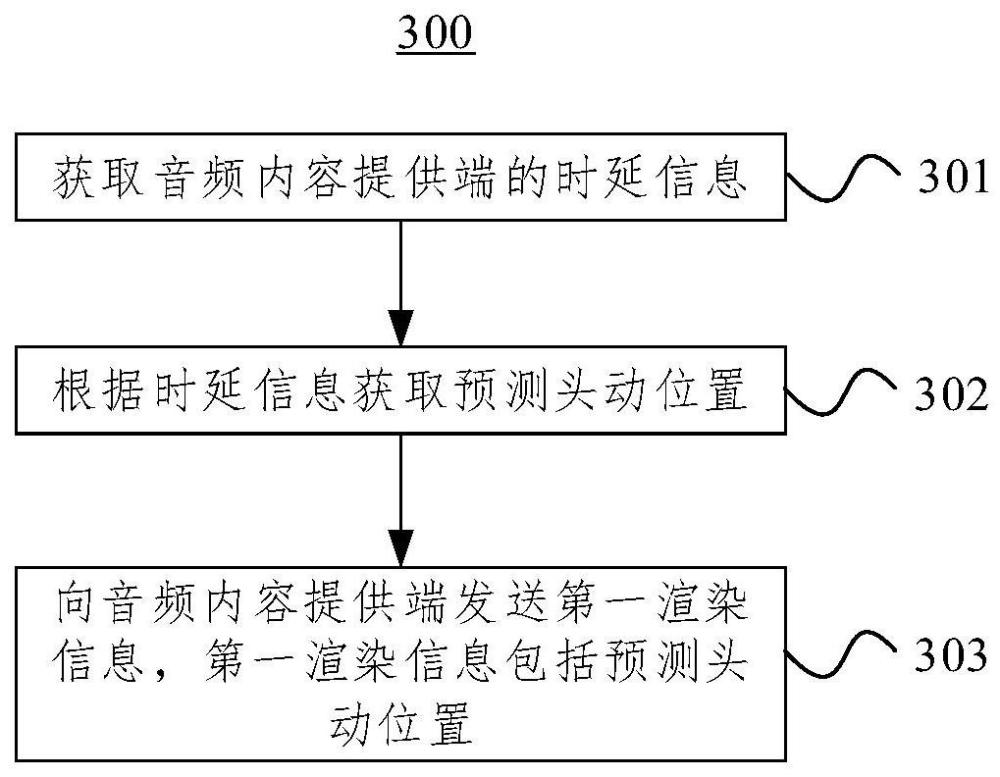
2、第一方面,本技术提供一种空间音频渲染方法,包括:获取音频内容提供端的时延信息;根据所述时延信息获取预测头动位置;向所述音频内容提供端发送第一渲染信息,所述第一渲染信息包括所述预测头动位置。
3、本技术通过对用户的头动位置进行预测以得到预测头动位置,将该预测头动位置发送给音频内容提供端后,使得音频内容提供端可以基于该预测头动位置对音频帧进行渲染,这样得到的渲染后音频帧可以提供与预测头动位置对应的听音效果。那么当该渲染后音频帧发送至音频信号播放端时,预测的时间可以与渲染处理、链路传输等导致的时延相抵消,从而在音频信号播放端播放该音频帧时,正好与用户的头动位置相匹配,达成上文所述的真实的、沉浸式的听音体验。
4、时延信息用于指示音频内容提供端的时延情况,可以包括以下几种情况:
5、第一种,时延信息包括音频内容提供端发送的时延
6、音频内容提供端在确定自己的传输链路、渲染处理等造成的时延后,可以将该时延封装于发送给音频信号播放端的第一信息中,发送给音频信号播放端。这样音频信号播放端可以从来自于音频内容提供端的第一信息中直接提取到音频内容提供端的时延。
7、第二种,时延信息包括音频内容提供端发送的第二历史头动位置
8、音频信号播放端(例如耳机)可以周期性地通过感应器(例如陀螺仪、重力传感器等)检测佩戴了耳机的用户的头在当下的位置(本文中将其称作实测头动位置),这样音频信号播放端可以将测得的实测头动位置发送给音频内容提供端。
9、音频内容提供端收到前述实测头动位置后,先不做处理,依然按照既定流程对音频帧进行相关处理。当处理完成要向音频信号播放端发送第一信息时,在第一信息中携带上前述实测头动位置,由于此时已经过去了一段时间,因此前述实测头动位置此时成为历史头动位置(本文中将其称作第二历史头动位置)。应理解,从数学意义上讲,前述实测头动位置和前述第二历史头动位置是相同的。
10、基于此,音频信号播放端可以根据接收到第二历史头动位置的时间和发送实测头动位置的时间获取到二者的时间差(亦即计算同一头动位置的接收时间和发送时间的时间差),从而间接获取到音频内容提供端的时延。
11、第三种,时延信息包括音频内容提供端发送的第二历史头动位置和第一不确定系数第二历史头动位置可以参照上文第二种情况的描述,此处不再赘述。
12、第一不确定系数是kalman滤波器中的一个重要参数,有助于提高预测结果的准确性。
13、为了让用户通过音频信号播放端(例如耳机)享受到真实的、沉浸式的听音体验,可以利用空间音频技术,可以将立体声、多声道环绕声、特殊制作的多对象音源等不同格式的声源渲染为双耳信号。在真实世界中,当我们的头部发生转动或位移时,声源本身的绝对位置不会改变,而声源与头部的相对方向会产生变化。例如,在你前方有一把吉他正在演奏,如果你转向右边,吉他的声音就会相对的变到你的左边。又例如,舞台左侧有一把吉他,右侧有一支萨克斯,当你移动到舞台的侧面,吉他与萨克斯的声音会重合到一起,来自同一个方向。可见,所谓的真实的、沉浸式的听音体验,是正如前述描述的对吉他或者舞台表演的听音体验,随着用户的头的位置的转变(包括但不限于头的上下左右位移、头部转动等),来自同一音频源的声音会在用户的耳朵里被渲染成不同的听音效果,而这种渲染即为带头动效果的渲染方法,即通过耳机中的感应器进行头部跟踪(head tracking),进而把相应的旋转或位移变化体现在对声源的空间渲染中。
14、与此同时,虽然音频内容提供端可以提供较高算力,从而实现上述带头动效果的渲染算法,但是由于音频内容提供端本身的特性,会引入较高时延,从而造成方位等重要空间信息错乱,例如,某一物体的声像设计在空间正前方,如果用户的头发生转动,声像先移动至其面部正前方,再恢复至空间正前方,有明显延迟“阻尼感”,影响听感。
15、为了解决上述时延导致的问题,音频信号播放端可以对用户的头动位置进行预测,然后将该预测头动位置发送给音频内容提供端,使得音频内容提供端可以基于该预测头动位置对音频帧进行渲染,这样得到的渲染后音频帧可以提供与预测头动位置对应的听音效果。那么当该渲染后音频帧发送至音频信号播放端时,预测的时间可以与渲染处理、链路传输等导致的时延相抵消,从而在音频信号播放端播放该音频帧时,正好与用户的头动位置相匹配,达成上文所述的真实的、沉浸式的听音体验。
16、本技术中,音频信号播放端可以先获取与时延信息对应的第一历史头动位置;再通过传感器获取实测头动位置;然后根据第一历史头动位置和实测头动位置获取预测头动位置。
17、根据上文中时延信息的三种情况,音频信号播放端可以采用三种方法获取第一历史头动位置,即:
18、1、当时延信息包括音频内容提供端发送的时延(上文第一种情况)时,从缓存中提取与时延对应的第一历史头动位置,缓存中预先存储了多组时延和历史头动位置的对应关系。
19、如上文所述,音频信号播放端可以周期性地通过感应器检测佩戴了音频信号播放端的用户的实测头动位置,为了便于后续使用,音频信号播放端可以将存储下实测头动位置和检测时间的对应关系。这样当获取到上述时时延,可以通过查询前述对应关系得到与该时延对应的当时的实测头动位置(本文中将其称作第一历史头动位置)。
20、2、当时延信息包括音频内容提供端发送的第二历史头动位置(上文第二种情况)时,将第二历史头动位置作为第一历史头动位置。
21、参照上文第二种情况的描述可知,音频内容提供端直接将第二历史头动位置封装于第一信息中发送给音频信号播放端。这样音频信号播放端直接可以得到对应于时延的当时的实测头动位置(第二历史头动位置),因此音频信号播放端可以直接将该第二历史头动位置确定为第一历史头动位置。
22、3、当时延信息包括音频内容提供端发送的第二历史头动位置和第一不确定系数(上文第三种情况)时,将第二历史头动位置作为第一历史头动位置。
23、参照上文2的描述,在时延信息的第三种情况下,音频信号播放端也可以直接将该第二历史头动位置确定为第一历史头动位置。
24、音频信号播放端可以通过传感器获取实测头动位置,该实测头动位置是最新检测到的用户的头动位置。
25、本技术中,根据第一历史头动位置和实测头动位置获取预测头动位置可以包括以下两种算法:
26、第一种,在上述1和2的基础上,音频信号播放端可以获取第一历史头动位置和实测头动位置的差值;获取头动变化率,头动变化率是根据之前得到的n个实测头动位置得到的,n>1;根据差值和头动变化率获取预测头动位置。
27、第一历史头动位置和实测头动位置的差值可以是指第一历史头动位置和实测头动位置之间的距离。例如,在三维世界中,头动位置可以采用xyz坐标轴的方式进行表示,因此上述差值可以是第一历史头动位置和实测头动位置各自的坐标值之间的距离。此外,头动位置还可以采用其他方式表示,本技术对此不做具体限定。
28、如上文所述,音频信号播放端可以周期性地通过感应器检测佩戴了音频信号播放端的用户的实测头动位置,因此音频信号播放端可以根据之前得到的n个实测头动位置得到头动变化率,n个实测头动位置可以包括从当前的实测头动位置开始向前数n个。
29、音频信号播放端可以根据差值和头动变化率,使用三次样条插值等手段,预测得到头动变化值,然后将该头动变化值与当前的实测头动位置相加得到预测头动位置。
30、第二种,在上述3的基础上,音频信号播放端获取头动变化率,头动变化率是根据之前得到的n个实测头动位置得到的,n>1;根据头动变化率和第一不确定系数获取第二不确定系数;将第二不确定系数、第一历史头动位置和实测当前头动位置输入kalman滤波器以得到预测头动位置。
31、头动变化率的获取方式可以参照上文描述。
32、头动变化率结合第一不确定系数可以得到第二不确定系数。将第二不确定系数、第一历史头动位置和实测当前头动位置输入kalman滤波器。在kalman滤波器中,可以根据第二不确定系数和上一轮迭代的估计不确性确定kalman增益系数,并将kalman增益系数作为最新的增益系数。这样kalman滤波器可以输出预测头动位置。
33、需要说明的是,除了上述两种方法,本技术还可以采用其他算法根据第一历史头动位置和实测头动位置获取预测头动位置,对此不做具体限定。
34、音频信号播放端向音频内容提供端发送第一渲染信息,该第一渲染信息包括预测头动位置,使得音频内容提供端可以根据预测头动位置对音频帧进行带头动效果的渲染。这样得到的渲染后音频帧可以提供与预测头动位置对应的听音效果。那么当该渲染后音频帧发送至音频信号播放端时,预测的时间可以与渲染处理、链路传输等导致的时延相抵消,从而在音频信号播放端播放该音频帧时,正好与用户的头动位置相匹配,达成上文所述的真实的、沉浸式的听音体验。
35、在一种可能的实现方式中,当采用第一渲染模式时,音频内容提供端获取当前帧。当音频源的音频格式为非立体声格式时,音频内容提供端获取预测头动位置。音频内容提供端根据预测头动位置对当前帧进行渲染以得到第一双耳信号。当音频源的音频格式为立体声格式时,音频内容提供端不对音频源进行空间渲染。音频内容提供端向音频信号播放端发送第一信息,该第一信息包括第一音频流、音频源的音频格式和时延信息。当音频格式指示为立体声格式时,音频信号播放端通过传感器获取实测头动位置。音频信号播放端根据实测头动位置对当前帧渲染得到的第二双耳信号。音频信号播放端根据目标双耳信号播放音频,目标双耳信号包括第一双耳信号或第二双耳信号。
36、第一渲染模式可以是非低时延链路模式,在该模式下音频内容提供端可以基于预测头动位置对音频帧进行带头动效果的渲染。用户可以通过操作安装于音频内容提供端上的应用程序(application,app),选择是否选择第一渲染模式。相应的,本技术还包括第二渲染模式,在该模式下音频内容提供端对音频帧进行不带头动效果的渲染,该过程可以参见下文描述。同理,用户可以通过操作安装于音频内容提供端上的app,选择是否选择第二渲染模式。用户的操作可以参照下文实施例。
37、上述当前帧可以是音频源的其中一帧,通常可以是指音频内容提供端当前正在处理的音频帧。
38、音频源的音频格式包括立体声格式或者非立体声格式,其中,非立体声格式可以包括但不限于5.1、7.1、3da等多声道、多对象格式的音频。
39、本技术中,音频内容提供端可以对5.1、7.1、3da等多声道、多对象格式(非立体声格式)的音频进行高算力渲染,这样可以充分发挥音频内容提供端的算力优势。基于此,当音频源的音频格式为非立体声格式时,音频内容提供端可以对音频帧进行带头动效果的渲染,因此需要获取预测头动位置。
40、音频内容提供端可以从之前接收到的来自音频信号播放端的渲染信息中获取预测头动位置,可选的,该渲染信息可以是最新接收到的渲染信息,这样可以提高预测头动位置的准确性。预测头动位置的获取可以参照图3所示实施例,此处不再赘述。
41、本技术中,音频内容提供端可以根据预测头动位置分别对当前帧中的直达声部分、早期反射声(early reflection,er)部分和后期混响声(late reverb,lr)部分进行带头动效果的渲染,以得到第一双耳信号。
42、可选的,具有头动效果的直达声和具有头动效果的混响(由er和lr混合后得到)分别经过音频效果器渲染后进行混音,混音后的输出结果再次经过音频效果器渲染后,以第一双耳信号的形式传递。前述音频效果器包括但不限于均衡效果器、动态压缩效果器、低频增强效果器等。
43、本技术中,音频内容提供端不用对立体声格式的音频源进行渲染,交由音频信号播放端进行带头动效果的渲染,因此处理可以对5.1、7.1、3da等多声道、多对象格式(非立体声格式)的音频进行高算力渲染,这样可以充分发挥音频内容提供端的算力优势。基于此,当音频源的音频格式为非立体声格式时,音频内容提供端可以对音频帧进行带头动效果的渲染,因此音频内容提供端在第一音频流中封装入音频源即可。
44、如上文所述,当音频格式指示为非立体声格式时,第一音频流包括经音频内容提供端渲染的第一双耳信号;当音频格式指示为立体声格式时,第一音频流包括音频源。
45、立体声格式的音频源,由音频信号播放端对其进行带头动位置的渲染,由于音频信号播放端的imu数据传输链路时延较低,因此音频信号播放端可以实时地通过传感器获取当下的头动位置(本文中称作实测头动位置)。
46、音频信号播放端可以根据实测头动位置对当前帧中的直达声部分进行带头动效果的渲染,并对当前帧中的er和lr进行不带头动效果的渲染,以得到第二双耳信号。
47、可选的,具有头动效果的直达声和没有头动效果的混响(由er和lr混合后得到)分别经过音频效果器渲染后进行混音,混音后的输出结果再次经过音频效果器渲染后再次混音以得到第二双耳信号。前述音频效果器包括但不限于均衡效果器、动态压缩效果器、低频增强效果器等。
48、经过上述步骤的处理,音频信号播放端得到目标双耳信号,该目标双耳信号可以是第一双耳信号(音频源为非立体声格式),或者也可以是第二双耳信号(音频源为立体声格式)。
49、在一种可能的实现方式中,当采用第二渲染模式时,音频内容提供端获取当前帧;对当前帧进行不带头动效果的渲染以得到第二双耳信号(该第二双耳信号区别于上文中的第二双耳信号,为区分下文将其称作第三双耳信号);向音频信号播放端发送第二信息,第二信息包括第二音频流,第二音频流包括第三双耳信号。音频信号播放端音频信号播放端通过传感器获取实测头动位置,根据实测头动位置对当前帧(该当前帧是经过音频内容提供端进行前述不带头动效果的渲染后的音频帧)渲染得到的第四双耳信号。音频信号播放端根据目标双耳信号播放音频,目标双耳信号包括第四双耳信号。
50、第二渲染模式下,音频内容提供端对音频帧进行不带头动效果的渲染,可以充分发挥音频内容提供端的算力优势,不带头动效果可以缩短渲染时延,转而由音频信号播放端进行低算力的带头动效果的渲染,相较于第一渲染模式其时延更低,但头动效果的渲染效果较差。
51、第二方面,本技术提供一种空间音频渲染装置,包括:获取模块,用于获取音频内容提供端的时延信息;预测模块,用于根据所述时延信息获取预测头动位置;发送模块,用于向所述音频内容提供端发送第一渲染信息,所述第一渲染信息包括所述预测头动位置。
52、在一种可能的实现方式中,所述预测模块,具体用于获取与所述时延信息对应的第一历史头动位置;通过传感器获取实测头动位置;根据所述第一历史头动位置和所述实测头动位置获取所述预测头动位置。
53、在一种可能的实现方式中,所述时延信息包括所述音频内容提供端发送的时延;所述预测模块,具体用于从缓存中提取与所述时延对应的所述第一历史头动位置,所述缓存中预先存储了多组时延和历史头动位置的对应关系。
54、在一种可能的实现方式中,所述时延信息包括所述音频内容提供端发送的第二历史头动位置,所述第二历史头动位置为发送第二渲染信息时的实测头动位置,所述第二渲染信息早于所述第一渲染信息发送;所述预测模块,具体用于将所述第二历史头动位置作为所述第一历史头动位置。
55、在一种可能的实现方式中,所述预测模块,具体用于获取所述第一历史头动位置和所述实测头动位置的差值;获取头动变化率,所述头动变化率是根据之前得到的n个实测头动位置得到的,n>1;根据所述差值和所述头动变化率获取所述预测头动位置。
56、在一种可能的实现方式中,所述时延信息包括所述音频内容提供端发送的第二历史头动位置和第一不确定系数,所述第二历史头动位置为发送第二渲染信息时的实测头动位置,所述第一不确定系数来自于所述第二渲染信息,所述第二渲染信息早于所述第一渲染信息发送;所述预测模块,具体用于将所述第二历史头动位置作为所述第一历史头动位置。
57、在一种可能的实现方式中,所述预测模块,具体用于获取头动变化率,所述头动变化率是根据之前得到的n个实测头动位置得到的,n>1;根据所述头动变化率和所述第一不确定系数获取第二不确定系数;将所述第二不确定系数、所述第一历史头动位置和所述实测当前头动位置输入kalman滤波器以得到所述预测头动位置。
58、在一种可能的实现方式中,还包括:接收模块,用于接收所述音频内容提供端发送的第一信息,所述第一信息包括音频格式、第一音频流以及所述时延信息;其中,所述音频格式指示音频源为立体声格式或者非立体声格式;当所述音频格式指示为所述非立体声格式时,所述第一音频流包括经所述音频内容提供端渲染的第一双耳信号;当所述音频格式指示为所述立体声格式时,所述第一音频流包括所述音频源;渲染模块,用于当所述音频格式指示为所述立体声格式时,通过传感器获取实测头动位置;根据所述实测头动位置对当前帧渲染得到的第二双耳信号,所述当前帧是所述音频源的其中一帧;播放模块,用于根据目标双耳信号播放音频,所述目标双耳信号包括所述第一双耳信号或所述第二双耳信号。
59、在一种可能的实现方式中,所述渲染模块,具体用于根据所述实测头动位置对所述当前帧中的直达声部分进行带头动效果的渲染,并对所述当前帧中的早期反射声er和后期混响声lr进行不带头动效果的渲染,以得到所述第二双耳信号。
60、第三方面,本技术提供一种空间音频渲染装置,包括:获取模块,用于当采用第一渲染模式时,获取当前帧,所述当前帧是音频源的其中一帧;当所述音频源的音频格式为非立体声格式时,获取预测头动位置;渲染模块,用于根据所述预测头动位置对所述当前帧进行渲染以得到第一双耳信号;发送模块,用于向音频信号播放端发送第一信息,所述第一信息包括第一音频流、所述音频源的音频格式和时延信息,所述第一音频流包括所述第一双耳信号。
61、在一种可能的实现方式中,所述渲染模块,具体用于根据所述预测头动位置分别对所述当前帧中的直达声部分、早期反射声er部分和后期混响声lr部分进行带头动效果的渲染,以得到所述第一双耳信号。
62、在一种可能的实现方式中,所述获取模块,具体用于从所述音频信号播放端发送的渲染信息中得到所述预测头动位置。
63、在一种可能的实现方式中,所述时延信息包括时延。
64、在一种可能的实现方式中,所述渲染信息还包括所述音频信号播放端发送所述渲染信息时的实测头动位置;相应的,所述时延信息包括所述实测头动位置。
65、在一种可能的实现方式中,所述渲染信息还包括所述音频信号播放端发送所述渲染信息时的实测头动位置和第一不确定系数;相应的,所述时延信息包括所述实测头动位置和所述第一不确定系数。
66、在一种可能的实现方式中,当所述音频源的音频格式为立体声格式时,所述第一音频流包括所述音频源。
67、在一种可能的实现方式中,所述获取模块,还用于当采用第二渲染模式时,获取所述当前帧;所述渲染模块,还用于对所述当前帧进行不带头动效果的渲染以得到第二双耳信号;所述发送模块,还用于向所述音频信号播放端发送第二信息,所述第二信息包括第二音频流,所述第二音频流包括所述第二双耳信号。
68、第四方面,本技术提供一种音频信号播放设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序;当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如上述第一方面中任一项由音频信号播放端实施的所述方法。
69、第五方面,本技术提供一种音频内容提供设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序;当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如上述第一方面中任一项由音频内容提供端实施的所述方法。
70、第六方面,本技术提供一种计算机可读存储介质,包括计算机程序,所述计算机程序在计算机上被执行时,使得所述计算机执行上述第一方面中任一项所述的方法。
71、第七方面,本技术提供一种计算机程序产品,所述计算机程序产品包括计算机程序代码,当所述计算机程序代码在计算机上运行时,使得计算机执行上述第一方面中任一项所述的方法。
本文地址:https://www.jishuxx.com/zhuanli/20240802/237179.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。