基于多模态融合的学习意图推理方法及系统、程序产品
- 国知局
- 2024-08-05 11:41:52
本发明属于一种学习意图推理方法,具体涉及一种基于多模态融合的学习意图推理方法及系统、程序产品。
背景技术:
1、目前,线上/线下教学过程中会产生大量的学习过程数据,例如,课堂教学视频、音频、在线学习操作日志等,这些多模态数据通常是互补的,从多个不同角度描述学习行为,能够反映出学习的状态。通过多模态学习行为表征学习,旨在从多种异质模态的数据中提取学习行为的表征,缩小不同模态之间的异质性差距,这是进行学习分析的基础。
2、近几年,通过人工智能和计算机视觉等技术进行学习行为分析的研究愈发受到关注。线下课堂学习行为的分析主要基于课堂监控视频开展,提取视频中的图像进行分析,通过提取图片中学生的人体骨架关键点来识别单个学习者的动作。如董琪琪等在《基于改进ssd算法的学生课堂行为状态识别》中,使用改进的ssd算法进行多学习者的动作识别。还有研究者将骨架信息与手部动作信息或rgb图像特征融合来实现课堂行为识别,以提高识别精度。近年来,越来越多的研究者使用迁移的深度神经网络模型,如vgg16、resnet、fast-cnn等进行学习者动作识别。上述方法都是在单帧图像上进行的学习行为识别,忽略了学习行为的时序特征。因此,一些研究者在课堂视频数据集上实现了实时课堂学习行为识别,如谢伟等在《基于yowo的课堂学习行为实时识别》中,提出了一种实时识别单个学生的yowo模型;黄勇康等在《基于深度时空残差卷积神经网络的课堂教学视频中多人课堂行为识别》中,提出了一种实时识别多个学生的深度时空残差卷积神经网络模型。在线上教学中,除了上述线下课堂中使用的基于监控视觉的识别方法外,还有利用在线学习日志分析学习行为的方法。如胡锦林等在《基于时空图卷积网络的学生在线课堂行为识别》中,针对线上学习场景设计了一种融合全局注意力机制和时空图卷积网络的人体骨架行为识别方法;张敬然在《基于面部识别技术的在线学习行为深度感知方法研究与应用中》,公开了一种基于卷积神经网络构建了结合人脸关键点检测、眼睛状态检测、情绪识别的在线学习行为综合评估方法;王慧芬在《基于hadoop的学习者在线学习行为研究》中,利用hadoop大数据分析工具,从学习者的在线学习行为日志数据中挖掘学习者的有效信息进行在线学习行为特征分析。
3、但是,上述方法大多使用单一模态来表征学习行为,不仅对于学习行为的表征不够全面,而且影响了学习状态分析的准确性。另外,若将现有的大型多模态预训练模型迁移到学习行为表征领域,除了多模态本身需解决的关联性和互补性的问题外,还存在教学场景的多模态数据间异质性间隙大的问题,导致多模态数据对齐成为基于多模态数据进行行为分析的难点。
技术实现思路
1、本发明针对现有的学习行为分析方法中,大多是基于单一模态的方法,存在学习行为表征不够全面,学习状态分析准确性低的技术问题,若直接迁移使用现有的大型多模态预训练模型,又存在多模态数据对齐困难的技术问题,提供一种基于多模态融合的学习意图推理方法及系统、程序产品。
2、为了实现上述目的,本发明采用以下技术方案予以实现:
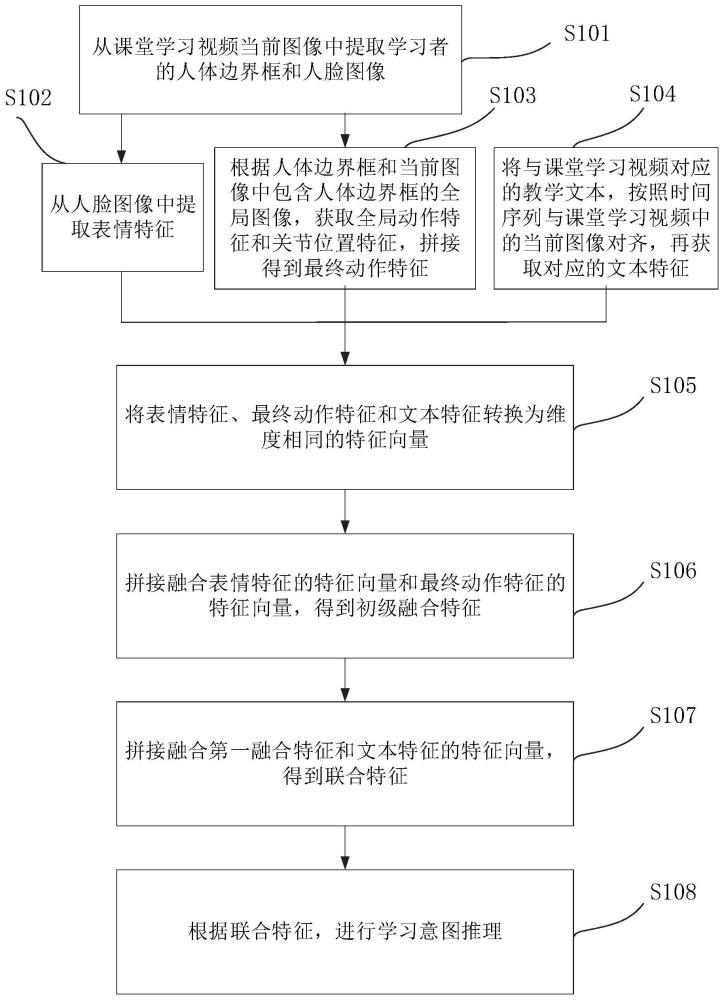
3、第一方面,本技术提出一种基于多模态融合的学习意图推理方法,包括以下步骤:
4、s1,从课堂学习视频当前图像中提取学习者的人体边界框和包含人体边界框的局部图像;
5、s2,从所述局部图像中提取表情特征;
6、s3,根据所述人体边界框和局部图像,获取全局动作特征和关节位置特征,拼接得到最终动作特征;
7、s4,将与课堂学习视频对应的教学文本,按照时间序列与课堂学习视频中的当前图像对齐,再获取对应的文本特征;
8、s5,将所述表情特征、最终动作特征和文本特征转换为维度相同的特征向量;
9、s6,拼接融合表情特征的特征向量和最终动作特征的特征向量,得到初级融合特征;
10、s7,拼接融合第一融合特征和文本特征的特征向量,得到联合特征;
11、s8,根据所述联合特征,进行学习意图推理。
12、进一步地,步骤s1中,所述人体边界框通过以下方式提取:
13、s1.1.1,从课堂学习视频当前图像中提取学习者的图像特征;
14、s1.1.2,对所述图像特征执行二分类任务和边界框回归任务,生成候选区坐标;
15、s1.1.3,从所述图像特征中提取候选区坐标,生成候选区特征图谱;
16、s1.1.4,根据候选区特征图谱,计算各区域类别,通过回归法获得人体边界框。
17、进一步地,步骤s1中,所述人脸图像通过以下方式提取:
18、s1.2.1,从课堂学习视频当前图像中获取包含学习者的局部图像;
19、s1.2.2,若所述局部图像中存在人脸部分,则通过mtcnn算法从局部图像中提取人脸图像,并将各局部图像中的人脸图像归一化至相同尺寸、相同位置和相同方向,再执行步骤s1.2.3,否则,生成固定尺寸的图像作为人脸图像;
20、s1.2.3,通过图像区域随机擦除、直方图均衡化或图像水平翻转,对人脸图像进行数据增强;
21、s1.2.4,从增强后的人脸图像中提取表情特征。
22、进一步地,步骤s3具体为:
23、s3.1,将所述人体边界框和当前图像中包含人体边界框的全局图像输入sppe网络,得到学习者的全局动作特征;
24、s3.2,将当前图像中包含人体边界框的全局图像划分为多个区域,分别将第i个区域ri输入sppe网络,得到对应的热图pi;其中,1<i≤n,n为区域总数;
25、s3.3,分别从热图pi中检测出图上关键点pi′,得到关节点;
26、s3.4,对关节点进行分类,得到关节节点集合和人节点集合其中,表示第j个k类节点,k表示节点类别,nk表示k类节点的数量;hi表示第i个人节点,m表示人节点的数量;
27、s3.5,逐一判断集合中的各关节节点是否包含集合中的元素,若是,则将该关节节点保留并作为候选节点保留,否则,放弃该关节节点;
28、s3.6,连接候选节点,得到多个边
29、s3.7,设计如下目标函数:
30、
31、其中,表示人-关节图,ε表示所有边的集合;表示第k类关节点i和j之间边的权重;表示第k类关节点i和j之间的距离;且:
32、
33、
34、
35、s3.8,根据目标函数,将热图pi转化为与全局动作特征维度相同的特征向量,再与全局动作特征拼接,得到最终动作特征。
36、进一步地,步骤s4中,所述获取对应的文本特征具体为:
37、将对齐后的教学文本输入bert模型,获得教学文本中每个字的嵌入向量、语句分块向量和位置编码向量,再加和嵌入向量、语句分块向量和位置编码向量,得到文本特征。
38、进一步地,步骤s5中,所述维度为512维;
39、步骤s8具体为,通过意图推理网络,进行学习意图推理;所述意图推理网络包括依次连接的全连接层、批标准化层、dropout层和输出层;
40、所述全连接层,用于将所述联合特征映射至256维的特征向量中,得到256维特征向量;
41、所述批标准化层,用于对所述256维特征向量进行标准化处理;
42、所述dropout层,用于将部分神经元的输出设置为零;
43、所述输出层,用于将标准化处理后的特征向量映射至二维的向量中,所述二维的向量分别表征学习和不学习。
44、进一步地,所述将部分神经元的输出设置为零,具体为:将60神经元的输出设置为零。
45、第二方面,本技术提出一种基于多模态融合的学习意图推理系统,包括:
46、图像提取模块,用于从课堂学习视频当前图像中提取学习者的人体边界框和人脸图像;
47、表情识别模块,用于从所述人脸图像中提取表情特征;
48、动作识别模块,用于根据所述人体边界框和当前图像中包含人体边界框的全局图像,获取全局动作特征和关节位置特征,拼接得到最终动作特征;
49、文本识别模块,用于将与课堂学习视频对应的教学文本,按照时间序列与课堂学习视频中的当前图像对齐,获取对应的文本特征;
50、转换模块,用于将所述表情特征、最终动作特征和文本特征转换为维度相同的特征向量;
51、初级融合模块,用于拼接融合表情特征的特征向量和最终动作特征的特征向量,得到初级融合特征;
52、二次融合模块,用于拼接融合第一融合特征和文本特征的特征向量,得到最终融合特征;
53、推理模块,用于根据所述最终融合特征,进行学习意图推理。
54、进一步地,所述表情识别模块为训练后的vggface人脸识别模型;
55、所述vggface人脸识别模型包括依次连接的5个卷积块、3个全连接层和1个softmax层,所述卷积块包括2个或3个卷积单元,所述卷积单元包括依次连接的卷积层、relu激活函数单元和池化层,所述卷积层的卷积核尺寸为3*3,所述池化层的步长为2。
56、第三方面,本技术提出一种计算机程序产品,包括计算机程序/指令,其特征在于,该计算机程序/指令被处理器执行时实现上述方法的步骤。
57、与现有技术相比,本发明具有以下有益效果:
58、1.本发明提出一种基于多模态融合的学习意图推理方法,分别提取表情特征、最终动作特征和文本特征,通过对学习行为进行语义级别的特征提取,将学习者的行为转化为向量表征,再通过语义级别的融合,将独立的各模态语义信息,使用线性变换对齐的方法,在统一的表征空间中进行初步对齐,再拼接融合对齐后的特征向量,从而对学习者的学习行为进行表征,解决了学习情境表示难和计算难的问题。
59、2.本发明中引入混合融合的多模态融合机制,利用多模态学习行为表征语义知识,分析不同学习行为之间的相关性,获取不同特征对意图的影响,进而推理出教学场景中学生的学习意图,丰富了意图特征的信息,提高了识别的准确率。经实验证明,在教学场景下的学习意图推理任务中,本发明的识别效果优于基于单模态数据的意图推理方法。
60、3.本发明还提出了一种基于多模态融合的学习意图推理系统,以及相应的计算机程序产品,能够结合硬件实现本发明的学习意图推理方法,便于本发明方法的推广应用。
本文地址:https://www.jishuxx.com/zhuanli/20240802/258872.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。