一种基于超图嵌入的社交网络账号对齐方法
- 国知局
- 2024-08-05 11:41:43
本发明涉及一种基于超图嵌入的社交网络账号对齐方法。
背景技术:
1、随着互联网的迅速发展,人们的生活方式发生了巨大的变化。在社交方面,社交网络服务已经成为当代人不可或缺的交流方式。人们在社交网络上分享自己的见闻、心情、状态、对某件事的看法等等,这也就产生了大量的有价值的信息。同时社交网络上的发言是具有匿名性的,只要用户不想透露自己的真实信息,其他人就无法知道这个账号的使用者到底是谁,并且同一个使用者可能在多个社交网络都拥有相应的账号。因此如何通过某个目标用户实体匹配其在多个社交网络上相关联的账号与信息,实现相应的跨社交网络账号对齐具有重要意义。
2、在对社交网络研究中,传统的图表征方法难以表示非成对关系这类用户特征,而这些特征往往可以有效地提供账号对齐的信息。超图作为近几年提出的新概念,其实是普通图的一种泛化。普通图在对社交网络中的用户及其关系进行表述时,默认所有的关系为二元关系,这种表示方法往往过分简化了真实数据的复杂性。并且实际情况下的社交网络,存在的用户之间的大多数关系都无法用简单的二元关系进行表达。因此,针对这一问题,社交网络超图引入了能够与任意数量的点相连的超边这一概念,相较于普通图,通过灵活地对超边进行定义,可以捕获社交网络中的非成对关系等高阶用户特征。此外,不同社交平台中的用户也可能通过非成对关系而互相联系。
3、现有技术致力于在引入更多用户数据的基础上发掘额外的用户特征,藉此提高账号对齐的准确率。首先,通过账号资料来提取用户特征是一类不需要复杂的算法模型的直观的技术,有方法(《liu l,cheung w k,li x,et al.aligning users across socialnetworks using network embedding[c].ijcai,2016:1774-1780》)使用账号中填写的用户名、性别、头像等账号资料来进行账号对齐。随着图嵌入技术的发展,有方法(《徐庆婷,洪宇,潘雨晨,等.属性抽取研究综述[j].软件学报,2023,34(2):690-711》、《narayanan a,shmatikov v.de-anonymizing social networks[c].2009 30th ieee symposium onsecurity and privacy,2009:173-187》、《vaswani a,shazeer n,parmar n,etal.attention is all you need[j].arxiv e-prints,2017:arxiv:1706.03762》、《kipf tn,welling m.semi-supervised classification with graph convolutional networks[j].arxiv preprint 2016:arxiv:1609.02907》)在社交网络拓扑结构数据的基础上使用图嵌入的方法分别表征不同的社交网络,并有监督地利用用户的拓扑特征进行账号对齐。此外,从贴文、评论、转发等用户生成内容中也可以提取独特的用户特征,有方法(《zhangy,tang j,yang z,et al.cosnet:connecting heterogeneous social networks withlocal and global consistency[c].proceedings of the 21th acm sigkddinternational conference on knowledge discovery and data mining,2015:1485-1494》、《胡三宁,李玉祥.基于多源数据整合的跨社交网络用户匹配方法[j].计算机仿真,2021,38(4):352-355》、《man t,shen h,jin x,et al.cross-domain recommendation:anembedding and mapping approach[c].ijcai,2017:2464-2470》、《zhan q,zhang j,wangs,et al.influence maximization across partially aligned heterogenous socialnetworks[c].advances in knowledge discovery and data mining:19th pacific-asiaconference,pakdd 2015,ho chi minh city,vietnam,may 19-22,2015,proceedings,part i 19,2015:58-69》、《zhang j,yu p s.pct:partial co-alignment of socialnetworks[c].proceedings of the 25th international conference on world wideweb,2016:749-759》、《zhang z,wen j,sun l,et al.efficient incremental dynamiclink prediction algorithms in social network[j].knowledge-based systems,2017,132:226-235》)使用了用户长期的主题兴趣、语言风格、emoji使用习惯等用户特征来进行账号对齐。
4、然而,现有账号对齐方法还普遍存在一些缺陷。首先,在模型中融合更多的用户特征可以帮助模型辨别用户,但受限于算法模型对于多源社交网络中复杂数据的融合与表征能力,现有方法很少可以统一地利用多种用户特征进行账号匹配;其次,现有基于社交网络拓扑数据的图表征方法依赖于大量有监督的匹配对来将不同的社交网络对齐至同一嵌入空间,然而,该过程通常会在模型中引入不必要的噪声,且有监督的匹配对在真实世界中不易获取。并且在处理大规模数据时,时间复杂度较高,需要耗费大量资源。
技术实现思路
1、本发明的目的在于克服现有技术的不足,提供一种在构建社交网络超图的基础上,提出一种基于超边权重的超图随机游走方法,得到游走序列后使用词嵌入的方法对超图节点嵌入,得到节点的嵌入向量并聚类,随后在缩小后的范围内基于账号的属性相似度计算实现跨社交网络账号的对齐。
2、本发明的目的是通过以下技术方案来实现的:一种基于超图嵌入的社交网络账号对齐方法,包括以下步骤:
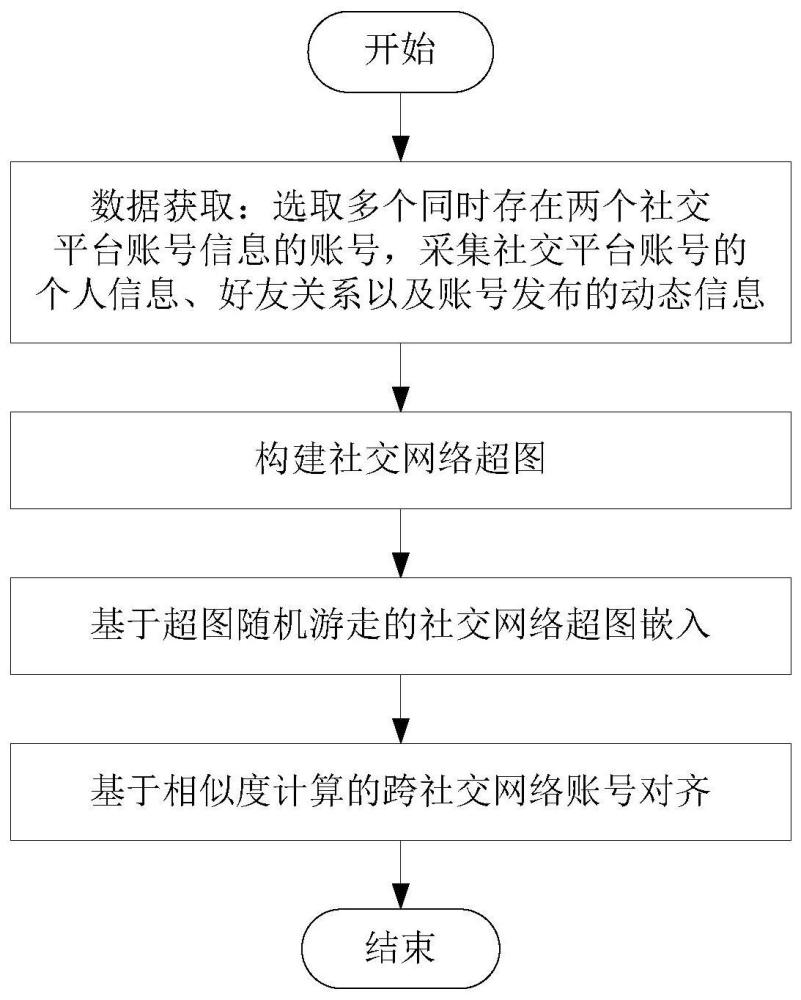
3、s1、数据获取:选取多个同时存在两个社交平台账号信息的账号,以这些账号为中心,采集相关的社交平台账号的个人信息、好友关系以及账号发布的动态信息;
4、s2、构建社交网络超图,社交网络超图由多个用户节点及以下四种超边组成:
5、(1)关注关系超边:根据采集到的用户之间的关注关系数据,定义如果任何两个用户节点之间都存在相互关注关系,即双向完全图,就认为这些用户处于同一条超边;
6、(2)位置超边:使用地理位置信息来构建超图,处于同一城市的账号为一条超边;
7、(3)语言超边:因此根据用户使用语言,使用同一种语言的账号为一条超边;
8、(4)兴趣超边:对用户生成内容进行主题提取,并获得用户的主题特征向量α=[t1,t2,…,tk],α每一维的取值ti代表用户a在谈论主题i的概率;将每个主题都视为一种非成对关系,有相同兴趣的账号为一条超边;
9、s3、基于超图随机游走的社交网络超图嵌入:在已经获得的社交网络超图基础上,开始超图随机游走;得到游走序列后,使用word2vec模型进行训练,输出超图中每个节点的嵌入向量,随后使用kmeans方法对用户节点进行聚类,将具有相似特征的用户节点聚为一类;
10、s4、基于相似度计算的跨社交网络账号对齐:对社交网络账号的用户描述、用户名和头像信息进行处理,分别计算不同社交网络平台账户在用户描述、用户名和头像信息之间的相似度,并计算总相似度。并且在聚类得到的每一类里,只有当某对账号彼此都是对方总相似度最高的节点时才视为匹配成功,以此实现跨社交网络账号的对齐;
11、用户描述的相似度:计算用户描述字段的短文本数据短之间的相似度sdesc;使用句向量技术来将用户描述文本转化为句向量,并通过句向量来衡量用户描述的相似度;具体地,对于用户描述文本a和b,使用sbert模型首先将其处理为词元序列[w1,w2,...,wn]和[w′1,w′2,...,w′n],接着使用bert提取其中每一个词元wi和w′i的词向量vi和v′i,再通过池化技术来聚合所有词向量vi和v′i,从而得到用户描述文本a和b最终的n维句向量表示sa和s′a;对于用户描述文本a和b,通过余弦相似度来计算对应的句向量之间的相似度sdesc;
12、用户名的相似度:通过用户名单词在字符上的差异来判断它们的相似性,使用levenshtein编辑距离来处理用户名属性;具体地,对于去除了特殊字符的用户名a和用户名b,它们之间的相似度sname计算为:
13、
14、其中,operation(·)代表在两个字符串之间进行转换所需要的最少操作数;max_len(·)代表字符串中最大的长度;
15、用户头像相似度:利用vgg-16预训练模型来计算用户头像的相似度,记为spic;该模型通过卷积神经网络提取图像特征,并基于这些特征来判断图像的相似度;对于头像图像a和头像图像b,vgg-16模型在其神经网络中逐层传递图像特征,并在最后一层输出它们的1000维特征向量fa和fb,然后利用余弦相似度来计算fa和fb之间的相似度spic;
16、总的相似度sattr由它们的平均值得到,即sattr=(sname+spic+sdesc)/3;基于总相似度在聚类后的小范围内寻找相似度最高的用户节点视为对齐。
17、本发明的有益效果是:本发明在构建社交网络超图的基础上,提出一种基于超边权重的超图随机游走方法,得到游走序列后使用词嵌入的方法对超图节点嵌入,得到节点的嵌入向量并聚类,随后在缩小后的范围内基于账号的属性相似度计算实现跨社交网络账号的对齐。能够降低时间复杂度,降低资源需求,提高对齐效率。
本文地址:https://www.jishuxx.com/zhuanli/20240802/258857.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表