一种基于时间平滑的加权平均日出库量计算方法与流程
- 国知局
- 2024-08-05 11:43:03
本发明涉及日出库量计算,尤其涉及一种基于时间平滑的加权平均日出库量计算方法。
背景技术:
1、随着全球经济的快速发展和供应链管理的复杂化,库存管理和出库量计算成为企业运营中的关键环节。准确预测日出库量对于优化库存水平、减少过剩或缺货、提高财务效率及客户满意度等方面至关重要。特别是在高度动态的市场环境中,如何快速且准确地处理和分析出库数据,已成为提升企业竞争力的核心问题。
2、在现有技术中,传统的日出库量计算方法通常采用简单的历史平均或移动平均模型,这些方法虽然操作简单,但在面对快速变化的市场需求和供应状况时,往往无法提供准确和及时的预测。具体来说,现有技术在以下几个方面存在明显的不足:
3、1.缺乏动态适应能力:传统出库量计算方法大多基于固定历史数据,难以适应市场需求的快速变化。当市场条件发生变化时,这些方法无法即时反映这些变化,从而影响决策的及时性和准确性。
4、2.处理数据波动性的能力不足:现有方法在处理数据时往往忽视了数据中的随机波动和噪声,这导致出库量预测易受偶发事件的影响,准确度不高。
5、3.权重分配的静态性:传统模型在权重分配上采用静态方法,即过去每天的数据被赋予相同的权重,这种做法忽视了最近数据对预测的重要性,降低了预测模型的反应灵敏度和准确性。
6、4.缺乏高效的数据处理和实时更新机制:在大数据环境下,传统出库量计算方法未能有效利用现代信息技术,如实时数据处理和自动更新机制,导致数据处理效率低下,无法实时反映最新数据变化。
7、因此,如何提供一种基于时间平滑的加权平均日出库量计算方法是本领域技术人员亟需解决的问题。
技术实现思路
1、本发明的一个目的在于提出一种基于时间平滑的加权平均日出库量计算方法。本发明充分利用了时间平滑技术和加权平均理论,详细描述了如何结合这两种技术来提高日出库量预测的准确性和及时性。通过引入动态权重调整机制,根据数据的时效性和重要性自动调整权重,从而提升预测模型的适应性和精确性。此外,本发明还通过实现实时数据更新和历史数据比较功能,优化了数据处理性能,提高了数据的稳定性和可靠性。本发明具备动态适应市场变化、处理数据波动性强、实时更新数据以及高效率数据处理的优点,有效支持了复杂和动态的库存管理需求。
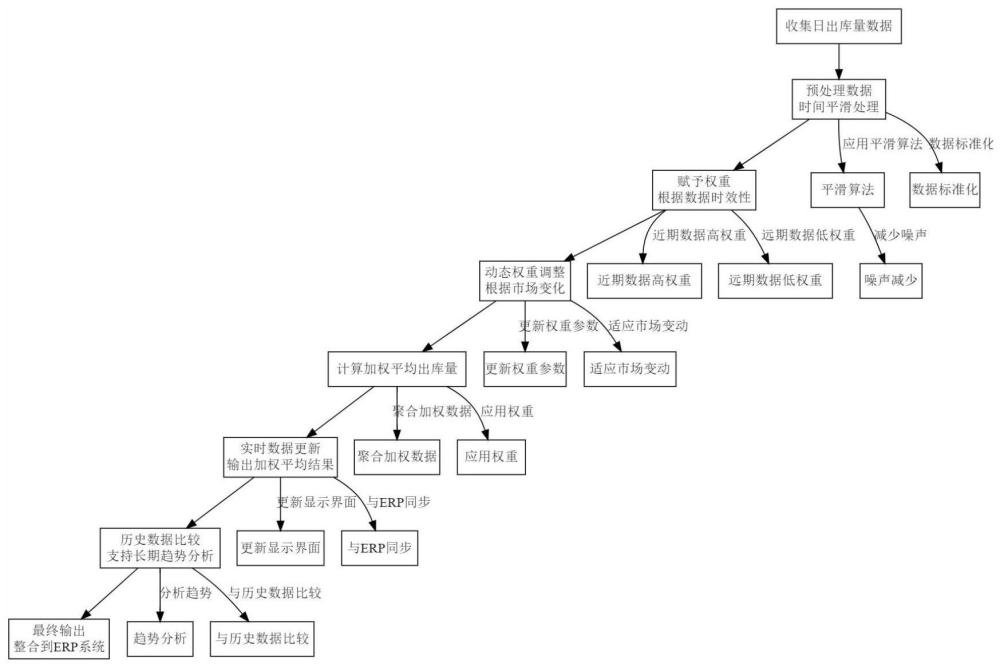
2、根据本发明实施例的一种基于时间平滑的加权平均日出库量计算方法,其特征在于,包括如下步骤:
3、s1、收集特定时间周期内的日出库量数据;
4、s2、应用时间平滑技术处理所收集的日出库量数据,减少随机波动和噪声的影响,增强数据的平稳性;
5、s3、根据数据的收集时间距离当前时间的远近,赋予每个数据点不同的权重,其中近期数据点赋予较高的权重;
6、s4、计算加权平均日出库量,利用赋予的权重,综合各数据点的日出库量和相应权重,得到加权平均结果;
7、s5、动态调整权重,根据最新获取的出库数据和市场环境变化,实时调整历史数据点的权重;
8、s6、输出加权平均日出库量的计算结果,并通过系统界面提供实时数据更新和历史数据比较。
9、可选的,所述s1具体包括:
10、s11、根据业务需求设定定义时间周期t,其中t为数据收集周期;
11、s12、确定数据收集的起始时间tstart和结束时间tend,其中tstart和tend均为日期时间格式,确保覆盖完整的周期t;
12、s13、使用数据采集系统自动从库存管理系统中提取出库记录,每个出库记录包含出库时间ti和相应的出库量qi,其中i表示记录索引;
13、s14、对每个数据点的时间ti进行标准化处理,将时间转换为相对于周期开始的时间差,使数据点相对于周期t进行标准化:
14、δti=ti-tstart;
15、s15、验证数据完整性和一致性,检查每个数据点的出库时间ti是否在tstart和tend之间,以及出库量qi是否为非负数;
16、s16、根据业务需求和数据分析目标,对收集到的数据进行预处理,将每个数据点的出库量qi标准化,消除不同量级的影响:
17、
18、其中,μq和σq分别代表出库量数据的平均值和标准差,对于超出正常范围的异常出库量,进行调整和剔除处理。
19、可选的,所述s2具体包括:
20、s21、选择指数平滑方法的时间平滑技术,处理收集到的日出库量数据的质量和准确性;
21、s22、若采用指数平滑技术对每个收集到的数据点qi实施时间平滑处理:
22、
23、其中,α代表平滑系数,该系数定义了当前数据点与历史数据平滑值之间的权重比例,取值范围为0<α≤1,qi是在时间点ti的实际出库量,而是前一时间点的平滑出库量;
24、s23、设定平滑窗口w,平滑后的出库量计算为前w个时间点出库量的算术平均:
25、
26、其中,w表示平滑窗口的宽度;
27、s24、根据数据集的表现自动调整平滑参数,参数优化过程根据预设的性能指标,自动调整以最小化误差:
28、
29、
30、其中,αnew和wnew为调整后的平滑系数和窗口宽度,η为学习率,控制参数调整的步长,和分别表示mape对α和w的偏导数;
31、s25、对选定的平滑方法进行性能验证,通过比对原始数据与处理后数据的统计分析,使所应用的平滑处理在减少随机波动和噪声,性能验证通过计算平滑后数据的均方误差来评估平滑效果:
32、
33、其中,n为数据点的总数,为第i个数据点经过平滑处理后的出库量预测值,qi为第i个数据点的实际出库量。
34、可选的,所述s3具体包括:
35、s31、定义权重分配函数,根据数据点与当前时间的相对距离δt来赋予不同的权重wi,其中权重赋值依据数据点时间ti的近远程度进行调整:
36、
37、其中,k是调节因子,控制权重随时间衰减的速率,δti=tcurrent-ti,tcurrent为当前时间,ti为数据点的时间;
38、s32、确定权重的正则化处理,使所有权重之和为1:
39、
40、其中,wi'为正则化后的权重,wj为每个数据点的原始权重,n为数据点的总数;
41、s33、应用赋予权重的数据点进行加权平均计算,得到加权平均日出库量:
42、
43、其中,qi为第i个数据点的出库量;
44、s34、根据实际业务需求和市场情况调整调节因子k,适应不同的业务环境和市场动态:
45、
46、其中,knew为调整后的调节因子,η为学习率,控制参数调整的步长,表示误差相对于调节因子k的偏导数,误差通过比较实际出库量与预测出库量之间的差异来计算;
47、s35、对加权平均计算结果进行实时更新,反映最新的数据输入和市场变化:
48、weightedaveragenew=weightedaverage+λ·(qnew-weightedaverage);
49、其中,weightedaveragenew为更新后的加权平均出库量,weightedaverage为当前的加权平均出库量,qnew为最新收到的出库量数据点,λ为调整系数。
50、可选的,所述s4具体包括:
51、s41、收集并应用正则化后的权重wi′和相应的日出库量数据qi进行加权平均计算:
52、
53、其中,n为数据点的总数,wi′为第i个数据点的正则化权重,qi为对应的出库量;
54、s42、计算加权平均出库量,根据数据的时效性和重要性赋予的权重,加权平均出库量通过除以权重的总和得到:
55、
56、s43、采用反馈机制,调整权重分配模型,使模型反映最近的市场和操作条件,基于周期性的误差评估,误差通过比较预测的出库量与实际出库量来计算:
57、δwi′=γ·(qi-weightedaverage);
58、wi′=wi′+δwi′;
59、其中,γ是调整率,控制权重更新的速度,δwi′是权重的调整量,wi′是更新后的权重;
60、s44、根据加权平均出库量的计算结果不断更新,适应新的数据输入和变化的出库情况:
61、weightedaveragenew=weightedaverage+β·(qnew-weightedaverage);
62、其中,weightedaveragenew为更新后的加权平均出库量,weightedaverage为当前的加权平均出库量,qnew为最新收到的出库量数据点,β为调整系数,控制新数据点对加权平均值的影响程度;
63、s45、将加权平均日出库量的计算结果整合到企业资源计划系统中,实现数据的自动更新和同步:
64、erpupdated=erpcurrent+δ·(weightedaverage-erpcurrent);
65、其中,erpupdated为更新后的erp系统中的出库量数据,erpcurrent为erp系统当前记录的出库量数据,weightedaverage为最新计算的加权平均出库量,δ为数据同步率,决定erp系统数据更新的频率和敏感性。
66、可选的,所述s5具体包括:
67、s51、设置动态权重调整机制,根据最新获取的出库数据和市场环境变化,实时调整历史数据点的权重:
68、
69、其中,wi,new是调整后的权重,wi是原始权重,α是权重更新速率,k是调节因子,δti,new是更新后的时间差tcurrent-ti;
70、s52、实施权重正则化,确保调整后的权重之和为1,保持加权平均计算的一致性:
71、
72、其中,wi,norm是正则化后的权重,n是数据点的总数;
73、s53、采用更新后的权重重新计算加权平均日出库量,使计算结果能反映最新的数据和市场情况:
74、
75、其中,qi是第i个数据点的出库量;
76、s54、监控和评估动态权重调整机制的效果,通过比较调整前后的加权平均出库量和实际出库量,以及通过数据驱动的方法优化权重调整参数α和k:
77、
78、其中,error表示均方根误差,评估加权平均预测与实际数据的偏差;
79、s55、将更新后的加权平均日出库量反馈到系统的决策支持工具中,支持更精确的库存和供应链管理决策:
80、decisionsupportupdated=decisionsupportcurrent+θ·(weightedaveragenew-decisionsupportcurrent);
81、其中,decisionsupportupdated为更新后的决策支持数据,decisionsupportcurrent为当前的决策支持数据,weightedaveragenew为最新计算的加权平均日出库量,θ为调整系数,控制新计算结果对决策支持数据的影响程度。
82、可选的,所述s6具体包括:
83、s61、将最终加权平均日出库量计算结果集成到用户界面,使用户可以直观地看到当前的出库量预测;
84、s62、实现数据比较功能,使用户能够通过界面对比不同时间点和不同参数设置下的加权平均日出库量;
85、s63、提供历史数据存储和访问功能,支持长期数据分析和趋势预测,允许用户存储每次的预测结果及其相关参数,并能够查询特定日期范围内的历史数据;
86、s64、实现自动更新功能,在用户界面上显示的数据始终是最新的,定期自动刷新界面数据,无需用户手动操作;
87、s65、启用用户定制功能,允许用户根据个人和企业特定需求调整显示设置和计算参数。
88、本发明的有益效果是:
89、(1)本发明通过结合时间平滑技术与动态权重调整,能够根据最新的市场数据和业务需求实时调整日出库量的预测权重。这不仅使得预测模型能够快速适应市场变化,也提高了对突发事件和季节性波动的响应能力。动态权重的调整根据数据的时效性和重要性自动进行,从而确保预测结果始终保持最高的准确性和相关性。
90、(2)本发明通过时间平滑处理大量出库数据中的随机波动和噪声,显著提高了数据处理的稳定性和可靠性。这种优化对于处理大规模数据集特别重要,如在大型零售或制造业中,有效地支持了复杂的数据分析任务,并减少了误差率。此外,通过自动化的数据处理和实时更新机制,本发明提高了数据处理和分析的效率。
91、(3)本发明通过实时数据更新和历史数据比较功能,为用户提供即时和历史数据视图,支持快速和精确的库存及供应链管理决策。这些功能使企业能够及时调整采购和库存策略,应对市场需求变化,从而减少库存成本并提升客户满意度。
92、(4)本发明通过集成先进的用户界面,提供了直观的数据显示、比较和分析功能,允许用户根据个人或企业特定需求调整显示设置或计算参数。这种高度的系统定制性不仅提高了用户体验,也使得系统能够更好地服务于各种不同的业务需求和操作环境。
93、(5)本发明通过高效的历史数据存储和访问功能,支持长期数据分析和趋势预测。企业可以利用这一功能追踪和分析长期销售和库存趋势,从而制定更有效的业务策略和市场进入计划。
本文地址:https://www.jishuxx.com/zhuanli/20240802/258983.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。