一种基于多属性融合的APT攻击检测方法
- 国知局
- 2024-08-05 11:56:29
本发明涉及网络安全与机器学习,具体涉及一种基于多属性融合的apt攻击检测方法。
背景技术:
1、随着互联网和信息技术的不断发展,高级持续性威胁(advanced persistentthreats,apt)攻击已成为当前网络安全领域面临的最大挑战之一。apt攻击的特点是高度隐蔽、持续时间长、威胁性大,往往不易被发现和防范。apt攻击者通常会在攻击前进行详细的调查和分析,寻找目标企业的弱点和漏洞,制定出精心策划的攻击方案。这些攻击者具备极高的技术水平和专业知识,能够使用各种复杂的技术手段,如零日漏洞攻击、社交工程、恶意软件等,来窃取企业的关键数据和机密信息。因此,我们需要采取一系列更加有效的措施来应对apt攻击。
2、目前许多apt检测的方法都是基于溯源图进行的,使得溯源图的重要性日益增加。系统溯源图是一种有向无环图,图中节点用于表示系统中主体(如进程、线程等)和客体(如文件、注册表、网络套接字等),边表示主体和客体之间的控制流和数据流的关系,溯源图能够保留系统执行操作的所有历史信息,便于检测长期且隐蔽的apt攻击。
3、随着网络攻击的日益频繁和复杂,入侵检测系统(intrusion detection system,ids)成为了保护组织安全的重要手段。ids通过监测网络流量或系统行为,来识别潜在的恶意活动和安全漏洞。目前大多数ids都是采用基于图学习的方法,通过分析系统运行过程中产生的溯源图来区分正常和异常的活动。然而,大多数ids也面临着被攻击者逃避的风险。模拟攻击是一种常见的逃避策略,它通过在攻击行为中加入与正常行为相似的子结构,来混淆基于图学习的ids的分类器。这些子结构可以从目标系统的历史日志中提取,或者通过执行无害的系统调用来生成。目前的研究表明,这种模拟攻击方法能够有效地绕过多种现有的ids,如基于特征匹配、基于状态匹配、基于异常统计等,给网络安全带来了严峻的挑战。
4、针对以上问题,如何设计和实现一种能够抵抗模拟攻击的ids,将溯源图进行更细粒度的划分,并采用集成学习的方法将节点嵌入、边嵌入以及子图嵌入所得结果进行加权融合,以抵御模拟攻击的入侵,是一个亟待解决的研究问题。
技术实现思路
1、针对现有技术的不足,本发明提供了一种基于多属性融合的apt攻击检测方法,包括如下步骤:
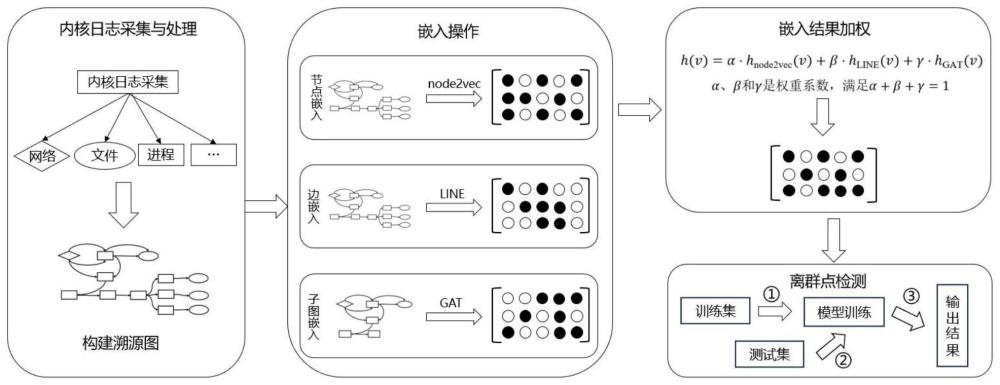
2、步骤1:采集系统内核日志数据,通过分析系统实体之间的交互关系,构建溯源图;
3、步骤2:通过对溯源图节点、边以及子图进行嵌入,将溯源图转换为低维向量空间,捕捉溯源图中不同维度的信息;
4、步骤3:综合不同维度的嵌入信息,采用集成学习方法,把节点、边和子图的嵌入结果进行加权操作;
5、步骤4:对加权后结果采用孤立森林算法进行离群点检测,找出与正常行为不一致的异常行为。正常行为通常指用户或主机在网络上的合法操作或交互,如登录、文件传输、电子邮件发送等,这些操作是由授权的用户或主机进行的,且符合网络使用政策和规定。异常行为指的是违反网络使用政策或规定的行为,通常表现为对网络资源的未授权访问、对系统进行的恶意攻击或试图绕过安全控制等。
6、进一步的,步骤1中,采集系统内核日志数据,通过分析系统实体之间的交互关系构建溯源图的详细步骤如下:
7、步骤1-1:溯源图定义:溯源图是一种在网络安全领域被广泛使用的概念,用于表示系统对象之间的交互关系;具体而言,溯源图描述了系统中不同实体(如进程、线程、服务、用户等)之间的数据流和控制流关系,无论这些节点之间相隔多少其他节点,或者发生时间相差多少,溯源图都可以将存在因果联系的节点连接起来。
8、步骤1-2:建立系统实体和事件之间交互关系:对日志采集工具采集到的数据进行分析与提取,利用分析结果建立系统实体之间的溯源图,其中节点代表系统实体,边表示它们之间的交互关系。
9、进一步的,步骤2中,通过对溯源图节点、边以及子图进行嵌入,将溯源图转换为低维向量空间,捕捉溯源图中不同维度信息的详细步骤如下:
10、步骤2-1:采用node2vec方法对溯源图中节点进行嵌入:node2vec是一种用于学习节点嵌入的方法,它基于随机游走来捕捉节点之间的结构信息;通过对溯源图节点嵌入可以将实体映射到连续的向量空间中,使得实体可以用向量来表示;在溯源图中,希望节点的嵌入能够保留图的信息,例如通过某个节点的嵌入向量能够找到它在图中的邻居;同时,希望可以将某个节点的嵌入向量直接用作下游任务的输入。
11、node2vec算法是通过随机游走来获取节点序列,然后使用skip-gram模型来学习节点的向量表示;
12、首先,构建随机游走序列,对于一个给定的节点v,用node2vec方法生成一组随机游走序列;随机游走的起点是节点v,每次从当前节点的邻居节点中按照设定的概率选择下一个节点;
13、之后,使用skip-gram模型来学习节点嵌入向量;对于每个节点v,将其随机游走序列作为训练数据输入到skip-gram模型中,然后,模型会学习出每个节点的向量表示;skip-gram模型的目标是最大化节点序列中相邻节点的共现概率,目标函数公式如下:
14、
15、其中,n(vt)表示节点vt的邻居节点集合,p(vj|vt)表示节点vj在给定vt的条件下出现的概率,logp(vj|vt)表示计算给定节点vt,预测节点vj出现的对数似然概率,max表示选择所有节点最大值作为最终的目标函数;
16、最终,node2vec算法通过随机游走和skip-gram模型来学习节点的向量表示,学习到的节点向量表示用作节点嵌入:vt=skipgram(vt),从而实现节点嵌入操作。
17、步骤2-2:采用line方法对溯源图中边进行嵌入:line(large-scale informationnetwork embedding)算法适用于各种类型的信息网络,包括无向、有向和加权网络;它通过优化一个目标函数来学习节点的向量表示,同时保留了局部和全局的网络结构信息;因此,使用line算法对系统溯源图中的边进行嵌入,将溯源图中各条边嵌入到低维向量空间中,得到每条边的向量表示,以便在后续任务中使用这些向量表示,line算法可以同时考虑节点和边的信息,从而提高图结构的表达能力。
18、首先,对于有向边(i,j),需要初始化节点和边的嵌入向量:对于每个节点i,有两个嵌入向量:和表示节点i的出度嵌入向量,表示节点i的入度嵌入向量,定义一阶相似度和二阶相似度:其中,一阶相似度公式表示如下:
19、
20、其中,是sigmoid函数,表示节点i的出度嵌入向量,表示节点j的入度嵌入向量;
21、二阶相似度公式表示如下:
22、
23、其中,|v|是节点的总数,的邻居节点为k;
24、之后,进行梯度的计算与更新,对于每条有向边(i,j),计算梯度并更新嵌入向量;
25、对于
26、
27、对于
28、
29、之后,更新嵌入向量:
30、
31、
32、最终,对于每条有向边(i,j)输出边嵌入后的结果:
33、
34、步骤2-3:采用gat方法对溯源图进行子图嵌入:对于子图嵌入,该方法采用图注意力网络(graph attention network,gat)方法来生成图嵌入;gat是一种用于图嵌入的神经网络模型,它能够有效地学习节点的嵌入向量,并且在处理图结构数据时表现出色;gat首先利用自注意力机制来聚合节点的邻居信息,之后对于每个节点,gat计算其邻居节点的权重,然后将邻居节点的特征向量加权平均得到节点的嵌入向量。
35、对于每个子图,采用以下方式进行嵌入:
36、首先进行节点表示,对于每个节点i,初始化其特征向量
37、之后进行自注意力计算,对于每个节点i,计算其邻居节点的注意力权重,计算公式为:
38、
39、其中,αij表示节点i和节点j之间的注意力权重,是可学习的权重向量,用于计算注意力权重,和分别表示节点i和节点j的特征向量,是可学习的参数矩阵,用于将特征向量映射到一个新的空间,∣∣表示连接操作,将两个向量按列连接成一个新的向量,leakyrelu(x)是一个激活函数;
40、公式(9)首先将节点i和节点j的特征向量联系起来,之后计算连接后的向量与权重向量的内积,然后将内积结果传入leakyrelu(x)激活函数,最后用指数函数将leakyrelu(x)的输出转化为正数,并将其归一化为注意力权重:
41、之后进行特征聚合,对于每个节点i,使用注意力权重对邻居节点的特征进行加权平均:
42、
43、最后,对于每个子图,将所有节点的嵌入向量进行池化,得到最终子图的嵌入向量。
44、进一步的,步骤3中,综合不同维度的嵌入信息,采用集成学习方法,把节点、边和子图的嵌入结果加权操作的详细步骤如下:
45、集成学习方法是一种使用多个学习算法来获得比单独使用任何单一学习算法更好的预测性能的方法,这些方法通过组合多个模型来提高整体性能;因此,本方法将三种不同嵌入方式所获得的嵌入向量进行加权集成,得到每个节点的综合向量表示;通过线性加权,我们可以将不同嵌入方法的优势结合起来,从而获得更全面和更鲁棒的节点表示。
46、进一步的,所述步骤4中,对加权后结果采用孤立森林算法进行离群点检测,找出与正常行为不一致的异常行为的详细步骤如下:
47、将步骤3所得出加权后的嵌入向量作为输入数据,构建样本集合,每个嵌入向量代表溯源图中的一条边或节点,将这些嵌入向量视作高维空间中的数据点;之后将样本集合划分为训练集和测试集,使用孤立森林算法构建模型,并使用训练集对孤立森林模型进行训练;
48、首先构建孤立森林模型,孤立森林是一种基于树的异常检测方法,它通过构建随机划分的二叉树来实现异常点的快速检测;随机选择一个特征(维度)和一个随机切分点,然后将我们的数据集划分为两个子集:一个在切分点的一侧,另一个在另一侧;之后递归地重复前两步操作,直到每个子集中只包含一个数据点或达到树的最大深度,最后构建多棵这样的随机数,模型就已经构建完毕。
49、之后使用训练集对模型进行训练,每棵树都会学习不同的划分规则,以便更好地捕捉异常点,训练过程中,孤立森林会计算每个数据点在树中的平均路径长度。
50、模型训练好后,对测试集中的节点应用训练好的孤立森林模型,对于每个节点,计算其在每棵树中的平均路径长度,将这些平均路径长度取平均,作为节点的异常得分;如果节点的平均路径长度较短,则视为异常节点。
51、最终进行阈值设置,将在模型训练过程中最大的异常得分作为阈值;在最终测试阶段,如果数据点的异常得分超过设定的阈值,则将其视为异常。
52、本发明的有益效果主要表现在:
53、1、系统内核日志包含了系统运行时的各种事件、行为和状态信息。通过提取并分析这些日志,可以获得关于系统的详细信息,将这些信息构建成溯源图,可以更全面地描述系统的结构和行为,有助于发现潜在的攻击或异常节点。
54、2、通过对溯源图进行节点嵌入、边嵌入和子图嵌入操作,可以从不同的角度和层面捕捉到系统中的特征和关系。节点嵌入可以反映每个节点的重要性和特征,边嵌入可以表示节点之间的连接关系,而子图嵌入则能够捕捉到整体的结构信息。综合这三种嵌入方式可以提高异常检测的准确性和鲁棒性。
55、3、本方法采用更细粒度的节点和边进行检测,使得攻击者使用模拟攻击添加的附加子结构将很难影响攻击图中异常节点的分类,对入侵检测系统的可靠性和准确性有很大提升。
56、4、使用了多种嵌入方式和集成学习的方法,不同的嵌入方式可能会有不同的判断标准和权重,通过综合考虑这些信息,系统能够更准确地检测出潜在的攻击行为,减少对正常行为的错误判定,降低误报率。
本文地址:https://www.jishuxx.com/zhuanli/20240802/260186.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。