基于注意力机制的多尺度特征融合光场图像深度估计方法
- 国知局
- 2024-08-19 14:17:27
本发明属于光场图像,具体涉及基于注意力机制的多尺度特征融合光场图像深度估计方法。
背景技术:
1、光场图像是一种用于捕捉场景中所有方向上光线信息的先进图像类型,不同于传统的二维图像,光场图像记录了从各个视角射入相机的光线,使观察者能够在后期从不同视点重新合成图像,这为虚拟现实、增强现实、计算摄影学等领域提供了广泛的应用潜力。
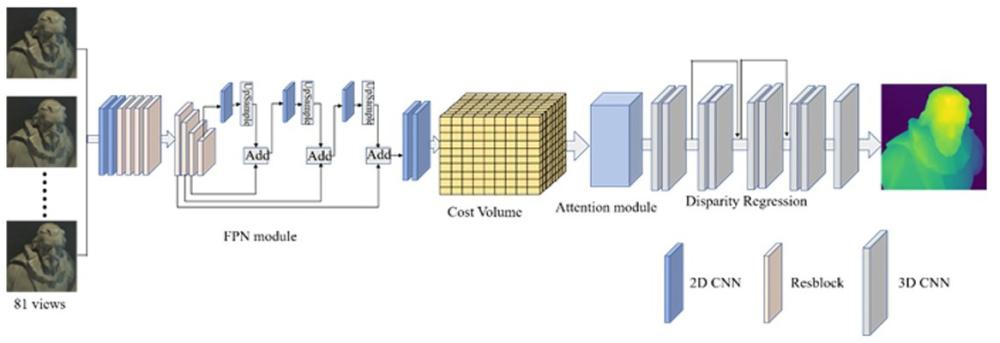
2、在计算机视觉领域,深度估计是一项关键任务,旨在从图像中推测出场景中物体的距离信息,准确的深度估计对于虚拟环境重建、3d建模、物体识别和姿态估计等任务至关重要。然而,由于图像中的信息有限,并受到遮挡、纹理等因素的影响,深度估计一直是一个具有挑战性的问题;另一个挑战是光场相机的子孔径图像之间的基线较窄,可能会引入视差图像的噪声,从而影响深度估计的准确性,由于图像传感器受到硬件限制,光场相机的空间分辨率和角度分辨率之间存在权衡。
3、基于卷积神经网络(cnn)的深度估计方法通常使用水平视图、垂直视图和对角视图构建双极几何图像(epi),虽然部分视图可以有效减少计算时间,但这可能无法充分利用光场的全部信息,因此深度估计的准确性提高有限。
4、光场图像具有特殊性质,导致数据量巨大且复杂,传统的深度估计方法难以直接应用于光场图像,此外,光场图像中的视角信息要求在深度估计过程中考虑更多的空间变化,因此,亟待一种专门针对光场图像的深度估计方法,充分利用其独特的信息,以此来提高对光场图像深度估计的精度,并且可以在3d显示器上播放。
技术实现思路
1、为解决现有技术无法充分利用光场图像的全部信息,来提高对光场图像的深度估计的精度,并且可以在3d显示器上播放的技术问题,本发明提供基于注意力机制的多尺度特征融合光场图像深度估计方法。
2、具体方案如下:
3、基于注意力机制的多尺度特征融合光场图像深度估计方法,具体包括以下步骤:
4、步骤s1:获取光场图像数据集输入网络,并对数据进行增强处理;
5、步骤s2:利用卷积块和残差块提取特征,构建残差网络,并使用空洞卷积扩大感受野,来捕获光场图像中的全局信息;
6、步骤s3:利用特征金字塔fpn捕获光场图像的全局上下文信息,以克服卷积神经网络在弱纹理或遮挡区域提取特征的限制,聚合场景的上下文信息,对不同层级的特征图进行相加,构建特征金字塔网络;
7、步骤s4:将特征金字塔的输出特征图,沿着通道维度在视差范围内进行平移,并进行拼接,以构建成本体积;
8、步骤s5:将cbam模块集成到网络中,结合通道注意力模块和空间注意力模块,以自适应地重新校准每个视图的特征响应;
9、步骤s6:使用3d卷积网络对成本体积进行聚合,并进行视差回归,得到视差估计;
10、步骤s7:对深度图进行处理得到点云数据,利用点云数据进行建模;
11、步骤s8:在3dmax设置虚拟相机阵列得到视差图,利用像素映射算法得到合成图像,并在3d显示器进行显示。
12、所述的步骤s1包括:
13、s11:获取视点图像数据集,输入网络的数据集为光场数据集,包含81个视点图像,每个视点图像的分辨率为512×512像素;
14、s12:对光场图像数据进行数据增强处理,包括数据集中光场图像的整体旋转、翻转和缩放操作。
15、所述的步骤s3包括:
16、s31:对来自不同层级的特征图进行处理,通过使用不同大小的卷积核来生成对应的特征金字塔;
17、s32:使用2d卷积对输入的特征图进行下采样,以生成不同层级的特征金字塔;
18、s33:使用双线性插值方法对生成的特征金字塔进行上采样,将上采样后的特征图与来自上一层级的特征图进行相加,以融合不同层级的特征图,构建特征金字塔。
19、所述的步骤s5包括:
20、s51:计算通道注意力权重;
21、s511:使用全局平均池化层对输入特征进行通道维度上的平均池化,得到通道的平均权重;
22、s512:将平均权重进行维度扩展,经过1×1×1的卷积核处理,得到通道的平均权重特征图;
23、s513:使用relu激活函数对卷积结果进行非线性处理,增强特征的表达能力,经过1×1×1的卷积核处理,得到通道的最终平均权重特征图;
24、s514:使用sigmoid激活函数对最终特征图进行处理,将权重限制在[0, 1]之间;
25、s52:计算空间注意力权重;
26、s521:使用全局最大池化层对输入特征进行空间维度上的最大池化,得到空间的最大权重;
27、s522:将最大权重进行维度扩展,经过1×1×1的卷积核处理,得到空间的最大权重特征图;
28、s523:使用relu激活函数对卷积结果进行非线性处理,增强特征的表达能力,经过1×1×1的卷积核处理,得到空间的最终最大权重特征图;
29、s524:使用sigmoid激活函数对最终特征图进行处理,将权重限制在[0, 1]之间;
30、s53:合并通道注意力权重和空间注意力权重,即,将通道注意力权重和空间注意力权重进行相加,得到最终的通道和空间注意力特征图,经过sigmoid激活函数处理,将特征图中的数值限制在[0, 1]之间。
31、所述的步骤s6包括:
32、s61:构建一个包含八个3 × 3 × 3卷积层的3d卷积神经网络,从成本体积中提取特征信息;
33、s62:使用一个3d卷积层对特征进行分类,并得到视差图的初始估计;
34、s63:确定17个候选视差值的数组,将视差值数组转换为张量,并在其基础上扩展维度以与特征图匹配;
35、s64:将成本体积图与视差值张量相乘并求和,以得到最终的视差估计值;
36、s65:对数据进行网络训练和结果测试。
37、本发明的有益效果为:
38、本发明中特征金字塔网络从多个视角提取不同层次的特征,以便更好的捕捉场景的上下文全局信息,利用空洞卷积扩大网络感受野,提高对光场图像深度估计的准确性;利用注意力机制,根据场景为光场图像每个视图分配不同的权重,以提高深度估计的性能;采用多尺度特征融合策略,以提高光场图像在遮挡区域的深度估计精度;通过视差回归,像素映射算法得到合成图像,利用裸眼全光场3d显示器对合成图像进行清晰的显示。
技术特征:1.基于注意力机制的多尺度特征融合光场图像深度估计方法,其特征在于:
2.根据权利要求1所述的基于注意力机制的多尺度特征融合光场图像深度估计方法,其特征在于:所述的步骤s1包括:
3.根据权利要求1所述的基于注意力机制的多尺度特征融合光场图像深度估计方法,其特征在于:所述的步骤s3包括:
4.根据权利要求1所述的基于注意力机制的多尺度特征融合光场图像深度估计方法,其特征在于:所述的步骤s5包括:
5.根据权利要求1所述的基于注意力机制的多尺度特征融合光场图像深度估计方法,其特征在于:所述的步骤s6包括:
技术总结本发明提供一种基于注意力机制的多尺度特征融合光场图像深度估计方法,利用特征金字塔网络从多个视角提取不同层次的特征,以便更好的捕捉场景的上下文全局信息,利用空洞卷积扩大网络感受野,提高对光场图像深度估计的准确性;利用注意力机制,根据场景为光场图像每个视图分配不同的权重,以提高深度估计的性能;采用多尺度特征融合策略,以提高光场图像在遮挡区域的深度估计精度;通过视差回归,像素映射算法得到合成图像,利用裸眼全光场3D显示器对合成图像进行清晰的显示。技术研发人员:刘晓旻,肖敏,杨长伟,徐云飞受保护的技术使用者:郑州大学技术研发日:技术公布日:2024/8/16本文地址:https://www.jishuxx.com/zhuanli/20240819/274597.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表