说话视频生成方法、装置、电子设备及可读存储介质与流程
- 国知局
- 2024-08-19 14:26:17
本发明涉及人机交互,尤其涉及一种说话视频生成方法、装置、电子设备及可读存储介质。
背景技术:
1、在现代社会,数字媒体得到了广泛的应用,人们越来越依赖视频内容进行沟通交流。这种趋势促使了视频生成技术的需求,特别是对虚拟人说话视频合成技术的需求。在电商领域,直播销售已经成为一种重要的销售方式,然而现实中的直播销售人员由于工作强度和人力资源的成本问题,无法实现每天24小时的全天候工作,使用说话视频生成技术,就可以用逼真的虚拟人形式全天候进行产品演示和销售,无需休息和人工干预;在旅游行业,虚拟导游的说话视频可以提供生动和细致的解说和导览体验,且不受时间、地点和语言的限制;博物馆可以利用说话视频生成技术制作虚拟讲解员,为游客提供专业的展品历史介绍和讲解。随着人工智能生成内容技术的发展,图像和视频的合成技术取得了显著的进步。说话视频生成的技术通常需要输入一段人物的说话音频和一个待合成形象的图像或视频,通过音视频处理输出合成形象的说话视频,并尽可能保持唇形与输入音频的同步。然而,目前的说话人视频生成技术仍存在一些局限和挑战,主要在于:生成的视频需要达到足够的清晰度,以满足4k或更高分辨率的视频和直播需求;生成的说话视频需要足够逼真和自然的唇形同步,以实现更好的互动效果和用户体验。
2、因此,现有技术存在缺陷,需要改进。
技术实现思路
1、本发明要解决的技术问题是:提供一种说话视频生成方法、装置、电子设备及可读存储介质,解决说话视频中生成中嘴型同步不够自然和合成清晰度较低的问题。
2、本发明的技术方案如下:提供一种说话视频生成方法,包括以下步骤:
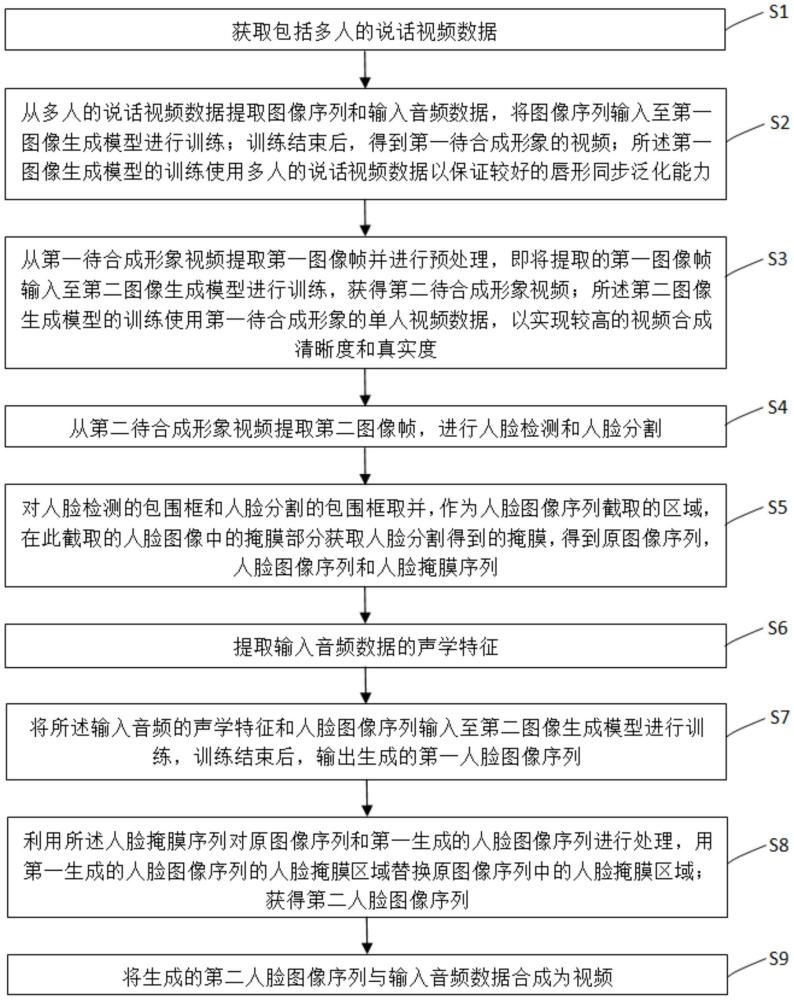
3、s1:获取包括多人的说话视频数据。
4、s2:从多人的说话视频数据提取图像序列和输入音频数据,将图像序列输入至第一图像生成模型进行训练;训练结束后,得到第一待合成形象的视频;所述第一图像生成模型的训练使用多人的说话视频数据以保证较好的唇形同步泛化能力。
5、s3:从第一待合成形象视频提取第一图像帧并进行预处理,即将提取的第一图像帧输入至第二图像生成模型进行训练,获得第二待合成形象视频;所述第二图像生成模型的训练使用第一待合成形象的单人视频数据,以实现较高的视频合成清晰度和真实度。
6、s4:从第二待合成形象视频提取第二图像帧,进行人脸检测和人脸分割。
7、s5:对人脸检测的包围框和人脸分割的包围框取并,作为人脸图像序列截取的区域,在此截取的人脸图像中的掩膜部分获取人脸分割得到的掩膜,得到原图像序列,人脸图像序列和人脸掩膜序列。
8、s6:提取输入音频数据的声学特征。
9、s7:将所述输入音频的声学特征和人脸图像序列输入至第二图像生成模型进行训练,训练结束后,输出生成的第一人脸图像序列。
10、s8:利用所述人脸掩膜序列对原图像序列和第一生成的人脸图像序列进行处理,用第一生成的人脸图像序列的人脸掩膜区域替换原图像序列中的人脸掩膜区域;获得第二人脸图像序列;
11、s9:将生成的第二人脸图像序列与输入音频数据合成为视频。
12、本发明说话视频生成方法包括:在包含不同说话人的视频数据中提取人脸数据用于模型训练;基于在包含不同说话人的视频数据训练好的模型,对单个特定人物的待合成说话视频提取人脸数据进行训练;对待合成形象视频提取图像帧,进行人脸检测和人脸分割,得到原图像序列、人脸图像序列和人脸掩膜序列;利用训练好的图像生成模型输出生成人脸图像序列,替换原图像序列中的人脸掩膜区域为生成的人脸图像的人脸掩膜区域;将生成的人脸图像序列合成为视频。
13、本发明的说话视频生成方法包含两个模型训练的阶段,第一图像生成模型的训练使用多人的说话视频数据以保证较好的唇形同步泛化能力,第二图像生成模型的训练使用待合成形象的单人视频数据,以实现较高的视频合成清晰度和真实度。实现了融合人脸检测和人脸分割算法的掩膜区域替换方法,能同时达到较好的人脸检测性能与精确的人脸分割效果,从而可以把生成的人脸图像精准替换到对应区域,避免了边框伪影等问题。
14、通过两阶段的模型训练策略,达到高清晰度和自然的说话视频生成效果,通过生成视频模型推断阶段的人脸分割、人脸图像生成,融合人脸检测和人脸分割算法的掩膜区域替换方法,精确逼真地还原了说话人唇形,避免了边框伪影等问题。
15、进一步地,在第一图像生成模型的基础上,训练第二图像生成模型。
16、进一步地,在步骤s9中,第二人脸图像序列经过图像编码器编码、输入音频数据经过音频编码器编码,然后进行合并,合并完成后,通过图像解码器进行解码,从而获得视频。
17、进一步地,第二人脸图像序列在图像编码器编码前,需要进行图像预处理。
18、进一步地,所述图像预处理包括:依次进行的灰度化、几何变换、图像增强。
19、进一步地,本发明还提供一种说话视频生成装置,包括:样本获取单元,用于获取步骤s1中的多人说话视频数据;第一图像生成模型;第二图像生成模型;图像检测分割单元,用于对人脸进行检测和分割;掩膜处理单元,用于获取人脸掩膜序列。
20、进一步地,本发明还提供一种电子设备,包括:存储器,所述存储器存储执行指令;以及处理器,所述处理器执行所述存储器存储的执行指令,使得所述处理器执行前述的说话视频生成方法。
21、进一步地,本发明还提供一种可读存储介质,所述可读存储介质中存储有执行指令,所述执行指令被处理器执行时用于实现前述的说话视频生成方法。
22、采用上述方案,本发明提供一种说话视频生成方法、装置、电子设备及可读存储介质,说话视频生成方法采用两阶段的模型训练策略,达到高清晰度和自然的说话视频生成效果,通过生成视频模型推断阶段的人脸分割、人脸图像生成,融合人脸检测和人脸分割算法的掩膜区域替换方法,精确逼真地还原了说话人唇形,避免了边框伪影等问题。
技术特征:1.一种说话视频生成方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种说话视频生成方法,其特征在于,在第一图像生成模型的基础上,训练第二图像生成模型。
3.根据权利要求1所述的一种说话视频生成方法,其特征在于,在步骤s9中,第二人脸图像序列经过图像编码器编码、输入音频数据经过音频编码器编码,然后进行合并,合并完成后,通过图像解码器进行解码,从而获得视频。
4.根据权利要求3所述的一种说话视频生成方法,其特征在于,第二人脸图像序列在图像编码器编码前,需要进行图像预处理。
5.根据权利要求4所述的一种说话视频生成方法,其特征在于,所述图像预处理包括:依次进行的灰度化、几何变换、图像增强。
6.一种说话视频生成装置,其特征在于,包括:
7.一种电子设备,其特征在于,包括:
8.一种可读存储介质,其特征在于,所述可读存储介质中存储有执行指令,所述执行指令被处理器执行时用于实现如权利要求1-5任一项所述的说话视频生成方法。
技术总结本发明公开一种说话视频生成方法、装置、电子设备及可读存储介质。所述说话视频生成方法包括:在包含不同说话人的视频数据中提取人脸数据用于模型训练;基于在包含不同说话人的视频数据训练好的模型,对单个特定人物的待合成说话视频提取人脸数据进行训练;对待合成形象视频提取图像帧,进行人脸检测和人脸分割,得到原图像序列、人脸图像序列和人脸掩膜序列;利用训练好的图像生成模型输出生成人脸图像序列,替换原图像序列中的人脸掩膜区域为生成的人脸图像的人脸掩膜区域;将生成的人脸图像序列合成为视频,精确逼真地还原了说话人唇形,避免了边框伪影等问题。技术研发人员:王孙平,邹琼,高斌,周双全受保护的技术使用者:深圳市瑞云科技股份有限公司技术研发日:技术公布日:2024/8/16本文地址:https://www.jishuxx.com/zhuanli/20240819/275195.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。