一种水基润滑剂循环热轧时润滑剂浓度的智能调节方法与流程
- 国知局
- 2024-08-19 14:30:00
本发明属于冶金自动化,智能化领域,涉及一种水基润滑剂循环热轧时润滑剂浓度的智能调节方法。
背景技术:
1、轧制是金属板材最常见的加工方式。热轧轧制过程就是将加热到一定温度的轧件利用工作辊辊缝形成的变形区进行塑性压延的过程。在塑性变形过程中,摩擦起着非常重要的作用,直接影响到轧制过程中的各种参数,如:咬入角、轧制力、前滑值与后滑值,也关系到轧制过程的稳定性,决定着产品的品质,尤其是在孔型轧制过程中,对摩擦的调控可均匀化轧辊磨损,改善产品质量,提高轧辊辊期的轧制公里数,降低生产成本,提高生产效率。
2、热轧工艺润滑轧制技术是指在轧制变形区内建立一层润滑膜,改变辊面与轧件间的直接接触,从而有效地减少摩擦和磨损、降低轧制力、提高生产效率并改善轧件表面质量。
3、专利cn102604730a公开了一种环保型纳米水溶性非油金属热轧轧制润滑剂制备方法,该水基润滑剂不仅可实现低能耗、低污染、低排放、高环保的现代文明生产的要求,还可以提高耐磨性能、不断地自修复破损的摩擦副表面、延长轧辊的使用寿命、提高轧材的光洁度。
4、专利cn202555589u公开了一种轧制润滑液循环装置,该装置可有效的解决轧制生产线上轧制润滑液回收循环利用的问题,可节省生产成本,实现保护环境的外在要求,对提升生产效率也具有良好的作用。
5、由于在水基润滑剂循环轧制过程中,随着轧制长度的增加,作为溶质的水基润滑剂原液以及作为溶剂的净环水都将因蒸发或烧蚀而损耗,使得水基润滑剂浓度发生变化。为更好地确定水基润滑剂的使用制度和服务产品生产,提前预报水基润滑剂循环轧制过程中高温摩擦系数的变化是十分必要的,可根据高温摩擦系数预报值与目标值的偏差来确定是否调整水基润滑剂的浓度。
技术实现思路
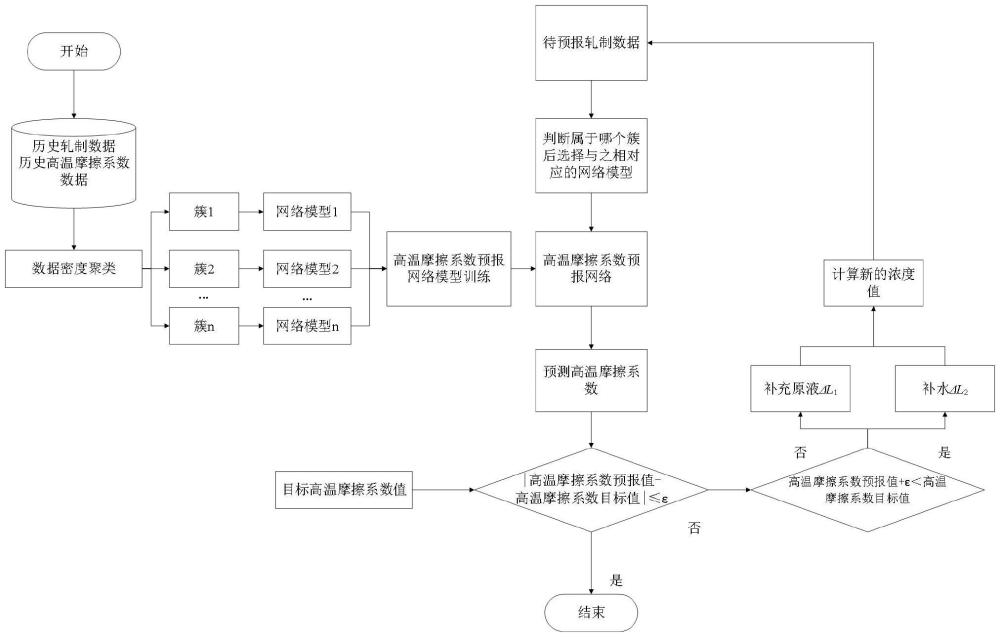
1、为了解决上述问题,本发明采用的技术方案是:一种水基润滑剂循环热轧时润滑剂浓度的智能调节方法,其特征在于:包括以下步骤:
2、s1:采用密度聚类方法对高温摩擦系数集进行密度聚类,获得n个簇;
3、s2:基于bp神经网络,针对每个簇的数据,建立水基润滑剂循环热轧高温摩擦系数预报网络,基于网络训练数据进行离线训练;
4、s3:根据待预报轧制数据判断属于哪个簇后,选择与之相对应、已经进行训练的预报神经网络模型,将经标准化处理的待轧钢板轧制数据输入到所述高温摩擦系数预报网络进行预测,预报高温摩擦系数;
5、s4:将预报的高温摩擦系数值与目标高温摩擦系数值进行对比,当预报的高温摩擦系数值与目标高温摩擦系数值的偏差满足收敛条件,即|高温摩擦系数预报值-高温摩擦系数目标值|≤ε,则继续进行轧制,不需要调整浓度值;当预报的高温摩擦系数值与目标高温摩擦系数值的偏差不满足收敛条件,则在调整水基润滑剂浓度后,返回s3,重新计算高温摩擦系数预报值,直至将现场水基润滑剂的浓度逐步调整至满足高温摩擦系数偏差要求的浓度值。
6、进一步地:所述水基润滑剂循环热轧高温摩擦系数预报网络的输入层包括8个神经元,分别为水基润滑剂的浓度、入口厚度或入口断面面积、出口厚度或出口断面面积、带钢宽度或断面周长、轧制温度、轧制力、轧制力矩和轧制长度;
7、所述高温摩擦系数预报网络的输出层包括1个神经元,输出高温摩擦系数值;所述的高温摩擦系数预报网络的隐藏层有p个神经元组成,p的值由高温摩擦系数预报网络模型的模型寻优来确定隐藏层最佳神经元个数,若高温摩擦系数预报网络的决定系数r2≥0.9,则证明p值满足网络预报精度,若决定系数(r2)<0.9,则p=p+1,直至高温摩擦系数网络预报精度满足要求;
8、隐含层神经元均采用公式(1)所示的tanh激活函数。
9、
10、进一步地:所述训练数据的准备包括以下步骤:
11、(a)创建样本数据,根据密度聚类后的结果,选出簇中的样本数据,即为该簇下的高温摩擦系数集;
12、(b)采用z-score方法对样本数据进行标准化处理;
13、z-score是数据标准化中常用的一种方式,如式(2)所示。
14、
15、式中,x*,μ,σ分别是标准化后的样本数据,所有样本数据的均值,所有样本数据的标准差。
16、(c)将样本数据划分为训练集数据和验证集数据两类。
17、进一步地:所述建立水基润滑剂循环热轧高温摩擦系数预报网络,基于网络训练数据进行离线训练的过程如下:
18、s21:将训练集中的样本标准化数据输入到所述的高温摩擦系数预报网络,通过网络前向传播与误差反向传播,得到训练后的网络权值和阈值;
19、s22:将验证集中的样本标准化数据输入到已完成训练的高温摩擦系数预报网络,通过网络计算获得高温摩擦系数预报值,并与样本期望的高温摩擦系数值进行比较,计算预报偏差指标,如果满足高温摩擦系数误差的收敛条件,即高温摩擦系数预报值-目标值≤ε,则完成所述高温摩擦系数预报网络的训练,否则对网络隐藏层最佳神经元个数p进行调整,返回到步骤s21重新进行训练。
20、进一步地:所述根据待预报轧制数据判断属于哪个簇,采用下列公式:
21、m=min(distance(a-bi)) (3)
22、式中,a为待轧钢板的轧制数据,bi为第i个簇的中心数据点,distance(a-bi)为a与bi的欧式距离,m为距离a最近的簇。
23、进一步的:所述当|高温摩擦系数预报值-高温摩擦系数目标值|≤ε成立时,则继续进行轧制,不需要调整浓度值;
24、当高温摩擦系数预报值-ε>高温摩擦系数目标值成立时,表示此时的高温摩擦系数值过高,因此需要在水基润滑剂中逐次补充原液以增加润滑剂浓度,进而减小轧制过程中高温摩擦系数值的过程如下:
25、假设每次补充原液的体积为δl1,每次补充原液后润滑剂的浓度计算如式4所示
26、a*=(δl1+a·v)/(v+δl1) (4)
27、式中,a*为调整后的水基润滑剂的浓度,a为调整前的水基润滑剂的浓度,v为轧制时水箱中润滑剂的总体积,δl1为每次补充原液的体积。
28、当高温摩擦系数预报值+ε<高温摩擦系数目标值时,表示此时的高温摩擦系数值过低,因此需要在水基润滑剂中逐次补水以降低润滑剂浓度,进而增大轧制过程中高温摩擦系数值。假设每次补充水的体积为δl2,每次补充水后润滑剂的浓度计算如式5所示:
29、a*=av/(v+δl2) (5)
30、式中,a*为调整后的水基润滑剂的浓度,a为调整前的水基润滑剂的浓度,v为轧制时水箱中润滑剂的总体积,δl2为每次补充水的体积。
31、每次调整水基润滑剂的浓度后,返回步骤3,重新计算高温摩擦系数预报值,直至将现场水基润滑剂的浓度逐步调整至满足高温摩擦系数偏差要求的浓度值。
32、一种水基润滑剂循环热轧时润滑剂浓度的智能调节方法,该方法可以实现轧制生产过程中水基润滑剂浓度的智能调节,避免循环轧制过程中高温摩擦系数的急剧变化,确保生产的稳定性。首先对采集的高温摩擦系数相关数据进行密度聚类,根据数据的分布将其划分为多个簇,然后针对每个簇的数据分别进行bp神经网络建模及离线训练;在轧制之前,根据待预报轧制数据判断属于哪个簇后选择与之相对应的神经网络模型进行预测;将预报的高温摩擦系数值与目标高温摩擦系数值进行对比,如果两者偏差满足要求则结束,不满足要求则在调整水基润滑剂浓度后再重新预报高温摩擦系数值,直至两者偏差满足控制要求为止。
本文地址:https://www.jishuxx.com/zhuanli/20240819/275397.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
上一篇
双主轴数控铣床的制作方法
下一篇
返回列表