一种基于用户级别资源跟踪的分账计费方法与流程
- 国知局
- 2024-08-22 15:10:48
本发明属于数据库系统,具体涉及一种基于用户级别资源跟踪的分账计费方法。
背景技术:
1、在当今日益复杂的金融市场中,实时数据处理和高效计算是保持竞争力的关键。金融机构不仅需要能够快速响应市场波动,还需要确保数据的准确性和安全性。面对这一挑战,将数据库系统dolphindb作为中台技术,开放给其他业务组,可以为金融机构提供一种高效、灵活且可扩展的数据处理解决方案,从而更好地满足不断增长的业务需求。
2、然而,尽管数据库系统dolphindb在大规模数据处理和实时分析方面表现出色,但在对分账计费方面存在一定挑战。当前的系统难以实现对不同业务组的资源使用情况进行准确跟踪和计费,这导致了资源的不合理分配和计费不公,进而影响了业务运营的效率和透明度,例如:cpu使用量无法统计;内存使用量需要用户编写定期收集的脚本,并不方便;而sql查询的数据访问量,可以通过任务日志查看sql查询的次数,但不能统计数据访问量。为了解决这一问题,需要一种新的方法来跟踪和管理用户级别的资源使用情况。
技术实现思路
1、为解决现有技术的不足,实现数据库系统中跟踪用户级别的资源使用情况,并进行相应的分账计费的目的,本发明采用如下的技术方案:
2、一种基于用户级别资源跟踪的方法,包括如下步骤:
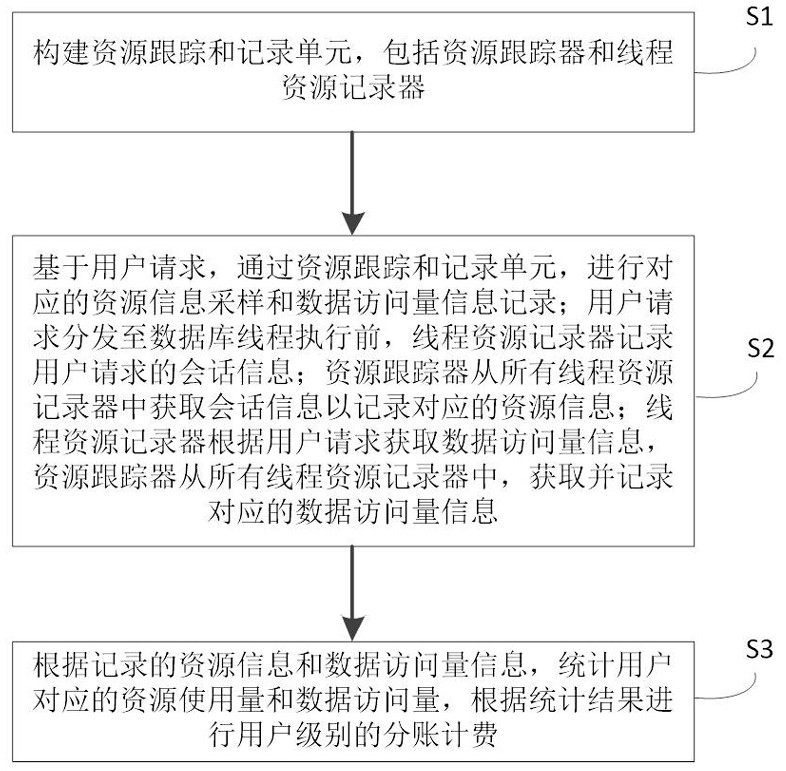
3、步骤s1:构建资源跟踪和记录单元,包括资源跟踪器resourcetracker和线程资源记录器,线程资源记录器用于收集各个线程中的资源信息和数据访问量信息,资源跟踪器resourcetracker对线程资源记录器收集的信息进行统计;
4、步骤s2:基于用户请求,通过资源跟踪和记录单元,进行对应的资源信息采样和数据访问量信息记录;用户请求分发至数据库线程worker执行前,线程资源记录器记录用户请求的会话信息session,在数据库线程worker执行结束后,线程资源记录器会清空对应的本线程的会话信息session;资源跟踪器resourcetracker从所有线程资源记录器中获取会话信息session以记录对应的资源信息;线程资源记录器根据用户请求获取数据访问量信息,资源跟踪器resourcetracker从所有线程资源记录器中,获取并记录对应的数据访问量信息;
5、步骤s3:根据记录的资源信息和数据访问量信息,统计用户对应的资源使用量和数据访问量。
6、进一步地,所述会话信息session包括用户id和用户堆heap的信息,资源跟踪器resourcetracker按用户id,统计会话信息session个数作为该用户cpu使用量,统计每个用户堆heap中所有变量作为内存使用量。
7、进一步地,所述资源信息包括cpu使用量,cpu使用量通过采样每个用户当前时刻占用的数据库线程worker数量得到;先记录用户id,当数据库线程worker执行结束后,再将用户id的记录取消,通过这样的方法可以在定时采样时扫描所有数据库线程worker记录的用户id,从而记录用户级别的cpu使用量。
8、进一步地,所述资源信息包括内存使用量,数据库线程worker开始处理请求时,记录用户堆heap,用户堆heap用于记录用户创建的变量,当数据库dolphindb脚本执行过程中需要获取变量,执行器从用户堆heap中取出相应的c++对象,定时资源信息的采样过程,通过扫描用户堆heap中的所有变量,并计算每个对象的内存分配大小,以此记录该时刻用户的内存使用量。
9、进一步地,所述用户请求包含用户发起的sql查询,线程资源记录器从sql查询中记录当前查询相关信息,包括时间、用户id、数据库名、数据表名、根查询rootqueryid和sql查询的脚本,对于sql查询的分布式执行过程,用户发起的sql查询请求会发送到集群中的某个节点,该当前节点上,sql查询会按分区情况拆分出多个单分区的查询,记录拆分出的单分区查询的数据访问量信息,这些单分区的查询会分发到各个节点上执行,最后,通过根查询rootqueryid将所有由同一个sql查询拆分出的查询关联起来,如果没有rootqueryid,则无法知晓某个拆分的查询是由哪个sql查询拆分得到的,当前节点将查询结果合并为最终的用户查询结果。
10、进一步地,数据访问量信息记录在线程资源记录器,当本分区的查询结束后,才会将数据访问量信息展示给资源跟踪器resourcetracker,这是因为如果在查询过程中,如果resourcetracker触发了日志记录,那么会把部分数据写入日志,造成信息不一致。
11、进一步地,当数据节点执行拆分出的单分区查询时,根据当前存储引擎不同,采用不同的记录方式:
12、对于olap引擎,其获取数据的逻辑有三种:
13、1、通过扫描文件获取数据;
14、2、通过chunk_cache_engine读分区缓存获取数据;
15、3、通过列缓存获取数据;
16、资源跟踪将记录上述三种情况实际读出的行数,其他情况,如从元数据中读取行数,都不会记录下来;
17、对于tsdb引擎,其获取数据的逻辑有两种:
18、1、通过扫描文件获取数据;
19、2、通过高速缓存引擎cache engine获取数据;
20、资源跟踪将记录这里实际读出的行数,其他情况,如从zone map里读取预聚合结果(如sum),都不会记录下来;
21、对于pkey引擎,其获取数据的逻辑有:
22、1、通过扫描文件获取数据;
23、2、通过高速缓存引擎cache engine获取数据;
24、资源跟踪将记录这里实际读出的行数。
25、进一步地,所述资源跟踪器resourcetracker用于定时触发资源信息(cpu和内存)采样、定时触发数据量日志的落盘以及资源跟踪的启停;当采样时间到时,资源跟踪器resourcetracker定时触发资源信息采样,本次记录完成后进行资源信息落盘,以csv格式记录在资源采集日志文件hardware.log中;资源跟踪器resourcetracker定时触发数据量日志的落盘,此时收集所有线程资源记录器记录的信息,并对数据访问量信息(用户id、rootqueryid、数据库名、数据表名)做一次聚合,目的是减少写入的日志数量,最后会以csv格式记录在访问日志文件access.log中;
26、为了方便运维,资源跟踪需要自动切分日志文件并定期回收过时日志文件,在资源跟踪器resourcetracker定时触发采样和落盘时,先检查资源采样日文件志hardware.log和访问日志文件access.log是否存在,如果不存在则创建文件并写入csv文件头;当采样和落盘结束后,资源跟踪器resourcetracker检查日志文件是否超过阈值(默认1gb),并做日志切分;当日志需要切分时,资源跟踪器resourcetracker会将当前日志文件重命名为以时间戳为前缀的日志文件。
27、一种基于用户级别资源跟踪的分账计费方法,根据所述的一种基于用户级别资源跟踪方法统计的用户资源使用量和数据访问量,根据统计结果进行用户级别的分账计费。
28、进一步地,构建用户资源获取单元和访问记录获取单元,通过用户资源获取单元,按时间范围,查询用户对应的节点的cpu使用量和内存使用量的日志记录,收集被拆分为多个文件的采样结果;通过用户访问记录获取单元,按时间范围,查询用户对应的节点的sql表访问日志记录。
29、本发明的优势和有益效果在于:
30、本发明提出了一种基于用户级别资源跟踪的分账计费方法,旨在解决当前数据库系统dolphindb在分账计费方面的挑战,该方法通过记录每个用户的资源消耗情况,包括cpu、内存使用量和查询数据量,实现了对用户级别的资源消耗的跟踪。该方法不仅可以确保资源的合理分配和利用,还可以为用户提供公平的计费信息,从而提高了系统的可观测性和运营效率。通过引入本发明的方法,使得数据库系统dolphindb能够更好地满足金融机构的需求。
本文地址:https://www.jishuxx.com/zhuanli/20240822/281512.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。