异构系统中的数据副本选择方法、系统、设备及存储介质与流程
- 国知局
- 2024-08-30 14:26:45
本发明涉及计算机,尤其涉及一种异构系统中的数据副本选择方法、系统、设备及存储介质。
背景技术:
1、在大数据平台建设当中,impala是一种高性能的分布式sql查询引擎,专为处理存储在hadoop、kudu等集群上的大规模数据设计。在大数据环境中,数据副本的有效管理对于查询性能至关重要。传统方法通常只依赖于副本位置或简单的负载均衡策略,这可能不足以应对复杂的数据访问模式和动态变化的系统负载;而且impala只能针对同构存储系统中的数据进行查询,无法对目前主流的异构系统中的数据进行查询。
技术实现思路
1、鉴于此,本发明提供一种异构系统中的数据副本选择方法、系统、设备及存储介质,能有均衡选取多个副本,提高了存储系统的资源利用效率。
2、本发明公开了一种异构系统中的数据副本选择方法,适用于lmpala查询调度器,其包括:
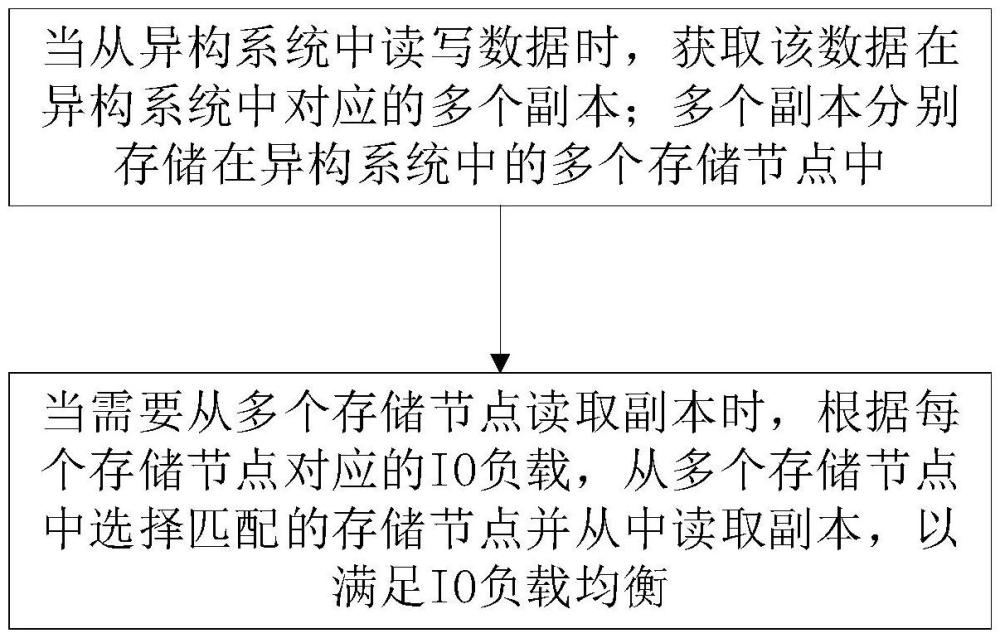
3、当从异构系统中读写数据时,获取该数据在异构系统中对应的多个副本;多个副本分别存储在异构系统中的多个存储节点中;
4、当需要从多个存储节点读取副本时,根据多个副本所在的存储节点对应的io负载,从多个存储节点中选择匹配的存储节点并从中读取副本,以满足io负载均衡。
5、进一步地,所述根据多个副本所在的存储节点对应的io负载,从多个存储节点中选择匹配的存储节点并从中读取副本,包括:
6、获取多个副本所在的每个存储节点的数据读取速度,根据数据读取速度,选取匹配的存储节点中的副本。
7、进一步地,所述获取多个副本所在的每个存储节点的数据读取速度,包括:
8、获取待读取的数据量、每个存储节点的io数据的最大吞吐量,计算待读取的数据量与每个存储节点的io数据的最大吞吐量的比值,并将该比值作为对应存储节点的数据读取速度。
9、进一步地,所述根据数据读取速度,选取匹配的存储节点中的副本,包括:
10、获取每个存储节点最近一段时间内的平均负载,基于数据读取速度和平均负载,得到每个存储节点的io负载,根据io负载选取匹配的存储节点中的副本。
11、进一步地,所述基于数据读取速度和平均负载,得到每个存储节点的io负载,包括:
12、将每个存储节点的数据读取速度和平均负载进行求和,得到每个存储节点的io负载。
13、进一步地,所述将每个存储节点的数据读取速度和平均负载进行求和,得到每个存储节点的io负载,包括:
14、获取每个存储节点对应的调节因子,调节因子用于调节io负载量;
15、将调节因子与求和的结果进行相乘,得到每个存储节点的io负载。
16、进一步地,所述根据io负载选取匹配的存储节点中的副本,包括:
17、比较所述多个存储节点对应的io负载;将io负载最小的存储节点中的副本作为最终选择的副本。
18、本发明还公开了一种数据副本的选择系统,用于实现上述任一项所述的异构系统中的数据副本选择方法,其包括:
19、获取模块,用于当从异构系统中读写数据时,获取该数据在异构系统中对应的多个副本;多个副本分别存储在异构系统中的多个存储节点中;
20、选择模块,用于当需要从多个存储节点读取副本时,根据多个副本所在的存储节点对应的io负载,从多个存储节点中选择匹配的存储节点并从中读取副本,以满足io负载均衡。
21、本发明还公开了一种计算机设备,其包括:处理器和用于存储所述处理器的可执行指令的存储器;其中,所述处理器用于执行所述可执行指令,以实现任一项所述的异构系统中的数据副本选择方法。
22、本发明还公开了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述任一项所述的异构系统中的数据副本选择方法。
23、由于采用了上述技术方案,本发明具有如下的优点:
24、1.更准确的负载评估:通过结合磁盘性能和最近的数据读写活动,能够更准确地评估系统当前的负载情况。
25、2.更有效的资源利用:优化的数据副本选择策略有助于更均匀地分配系统负载,提高资源利用效率。
26、3.性能提升:对于大数据应用,尤其是在查询hadoop存储的场景中,这种改进的方法可以显著提升性能。
27、4.本发明适用于需要高效数据存取策略的大数据处理和存储应用,同时也可以应用在需要数据读写的不同的异构系统中。
技术特征:1.一种异构系统中的数据副本选择方法,适用于lmpala查询调度器,其特征在于,包括:
2.根据权利要求1所述的异构系统中的数据副本选择方法,其特征在于,所述根据多个副本所在的存储节点对应的io负载,从多个存储节点中选择匹配的存储节点并从中读取副本,包括:
3.根据权利要求2所述的异构系统中的数据副本选择方法,其特征在于,所述获取多个副本所在的每个存储节点的数据读取速度,包括:
4.根据权利要求3所述的异构系统中的数据副本选择方法,其特征在于,所述根据数据读取速度,选取匹配的存储节点中的副本,包括:
5.根据权利要求4所述的异构系统中的数据副本选择方法,其特征在于,所述基于数据读取速度和平均负载,得到每个存储节点的io负载,包括:
6.根据权利要求5所述的异构系统中的数据副本选择方法,其特征在于,所述将每个存储节点的数据读取速度和平均负载进行求和,得到每个存储节点的io负载,包括:
7.根据权利要求4所述的异构系统中的数据副本选择方法,其特征在于,所述根据io负载选取匹配的存储节点中的副本,包括:
8.一种异构系统中的数据副本选择系统,用于实现权利要求1-7任一项所述的异构系统中的数据副本选择方法,其特征在于,包括:
9.一种计算机设备,其特征在于,包括:处理器和用于存储所述处理器的可执行指令的存储器;其中,所述处理器用于执行所述可执行指令,以实现权利要求1-7中任一项所述的异构系统中的数据副本选择方法。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现权利要求1-7中任一项所述的异构系统中的数据副本选择方法。
技术总结本发明公开了一种异构系统中的数据副本选择方法、系统、设备及存储介质,适用于lmpala查询调度器,该方法包括当从异构系统中读写数据时,获取该数据在异构系统中对应的多个副本;多个副本分别存储在异构系统中的多个存储节点中;根据多个副本所在的存储节点对应的IO负载,从多个存储节点中选择匹配的存储节点并从中读取副本,以满足IO负载均衡。本发明考虑副本的位置和负载均衡,显著提高了查询性能;综合了磁盘性能以及近期的数据读写活动,能够更精确地评估系统负载,从而更有效和更快地选择副本。技术研发人员:冯勇,王士峰,傅强,鄢秀庆,李会超,田涛,舒虎,曾珂,李治,蒋艾町,罗刚,陈浩,乔俏,骆俊林,罗倩倩,朱华磊,姚枫,曹芯竹,汪展鸿,李雨帆受保护的技术使用者:中国电力工程顾问集团西南电力设计院有限公司技术研发日:技术公布日:2024/8/27本文地址:https://www.jishuxx.com/zhuanli/20240830/282057.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。