一种面向数据异构与设备异构的个性化模型搜索框架
- 国知局
- 2024-08-08 16:59:04
本发明属于个性化联邦学习,具体涉及一种面向数据异构与设备异构的个性化模型搜索框架。
背景技术:
1、随着联邦学习技术的进步,其相关算法在各种应用场景中的使用也变得越来越广泛,服务器作为中心节点,可以将客户端的训练结果聚合为一个全局模型供所有客户端使用。然而,在联邦学习的实际部署中,常常会面临着客户端数据分布特征不同,即non-iid的问题。在数据分布差异过大的情况下,全局模型并不能适用于每一个客户端的本地数据。于是个性化联邦学习这一研究方向被人们提出,它区别于传统联邦学习最明显的特征是:中心服务器不再进行统一的准确率测试,而是由客户端独立完成个性化模型的准确率测试。个性化不再追求高质量的全局模型,而是为每一个客户端找到最优的个性化模型,这样的目标更为合理,而且能激励更多的用户参与到系统当中。至于如何满足客户端的不同需求,以实现个性化,目前已经有许多解决方案,每个解决方案都有自己的定义。
2、现有的个性化联邦学习方案普遍存在以下几点缺陷:1)基于统一规定的神经网络架构进行训练。这就会导致每个客户端仅能获得个性化权重参数,无法获得最佳的个性化模型。2)在实现个性化方面,现有的方案普遍都存在人为干预,例如方案本身的超参数、人为划分神经网络的共享部分与个性化部分。这些人为干预进一步导致了次优模型的产生。3)在联邦学习的实际部署中,设备异构与数据异构是同时发生并且相互影响的,现有的个性化方案普遍忽视了设备异构性。
3、神经架构搜索(neural architecture search,nas)是对于神经网络架构进行动态调整的技术,在固定的搜索空间内,通过搜索算法自动地寻找最优的神经网络架构。基于该项技术,可以动态地为每个客户端调整模型结构,以找出最优的个性化模型。将nas技术引入到联邦学习中,参与客户端在协同训练模型参数的同时,也可动态调整模型结构,从而产生更好的模型性能。
4、现有的联邦nas工作中,普遍存在以下几点缺陷:1)搜索空间内包含的可能架构数量庞大,如果将架构搜索的过程放置在客户端上,会给客户端增加计算负载,延长本地训练时间。2)大部分联邦nas工作仍然以获得最佳的全局模型为目标,忽视了客户端的个性化需求。
5、因此,利用nas技术来为每个客户端定制个性化模型结构,并通过联邦学习对模型参数进行协同训练,能够为每个客户端获得最优个性化模型,提高参与积极性。
技术实现思路
1、本发明的目的在于克服现有技术的不足,提供一种面向数据异构与设备异构的个性化模型搜索框架。
2、本发明解决其技术问题是通过以下技术方案实现的:
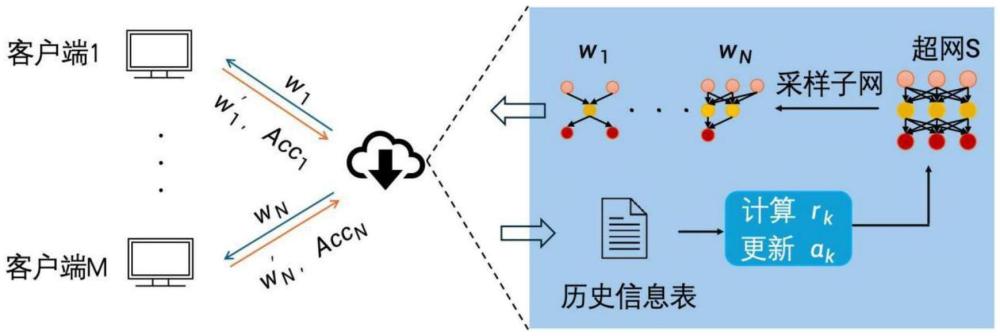
3、一种面向数据异构与设备异构的个性化模型搜索框架,其特征在于:所述框架旨在为每个客户端提高最佳个性化模型,并排除人为干预影响,所述框架将个性化联邦学习的问题求解过程视为多智能体强化学习过程,每个智能体单独负责一个客户端的架构搜索任务,所述若干智能体集中在服务器上由服务器直接为每个客户端分配不同结构的个性化模型,所述强化学习的组成部分包括:
4、状态:包括超网s和表示为客户端k的架构参数αk,存储和处理过程被放置在服务器上的历史信息表中,αk的初始值全部设置为0,表示所有候选操作被选中的概率一致;
5、智能体:对于每一个客户端,需要在服务器上分配一个代理智能体来负责搜索架构,每个代理智能体将根据αk给对应的客户端分配个性化模型,并由客户端进行本地训练,客户端完成本地训练后,向服务器报告准确率结果,从而完成αk的更新;
6、动作:每个客户端利用本地数据集进行模型参数训练,并将训练好的模型连同测试准确率结果一起报告给服务器,随后代理智能体需要执行动作,再次完成个性化模型的采样过程,用ak来表示每个代理智能体的动作,动作空间包括所有可能的模型结构。
7、而且,所述框架的搜索策略为:
8、主流的搜索策略基于损失梯度对架构参数αk完成更新,客户端需要在本地训练过程中完成模型参数与架构参数的更新过程,采用策略梯度的方式直接更新架构参数αk,将架构搜索过程与模型训练过程解耦,允许架构搜索任务部署于服务器上;
9、所述架构参数αk的更新方法为:
10、在每一轮通信中,需要为每个客户端分配一个奖励函数,并利用奖励函数rk来更新策略,该策略由架构参数αk参数化,而αk的更新是通过梯度上升的方式,进而使得从超网中采样的子模型对应期望奖励最大化,
11、强化学习的目标用j表示,即:
12、
13、其中:ηr表示为强化学习的学习率;
14、的计算公式为:
15、
16、其中:rk是奖励函数;
17、以搜索维度为d,计算得到:
18、
19、其中:vd表示由0和1组成的二进制掩码,若在搜索维度d上确定了某个候选操作,则该候选操作为1,否则为0;
20、架构参数αk的更新公式为:
21、αk=αk+ηrrk(vk-pk)。
22、而且,所述每个客户端分配的奖励函数rk针对每个客户端都是单独计算的,奖励函数的设计与两个指标有关,分别是客户端的测试准确率与每轮所需的通信时间(roundtime,rt),rt是本轮中从发送模型到接收客户端更新的模型参数所花费的时间,即客户端的训练时间与传输时间之和;
23、每个客户端在每轮通信中都得到一次奖励来反映各自的表现,每次客户端更新模型时,应该结合其它客户端的表现去计算奖励,最终奖励函数设置为:
24、
25、其中:表示当前参与客户端的平均准确率;
26、min(rt)表示当前参与客户端的最短通信时间;
27、λ作为超参数,平衡准确率与效率。
28、而且,所述超网s作为全局模型,当进行个性化模型采样时,只需要根据确定的候选操作,从全局模型中获取对应的子网架构和权重参数,而超网的权重参数更新过程,则依赖于各个客户端的训练结果,服务器通过聚合客户端的模型参数,实现超网上的权重参数更新;
29、在聚合过程中,首先将所有子网模型以填充0的方式扩展至超网结构,随后遵循fedavg算法,对各个模型参数依次进行平均计算;各个参数相加后需要除以非0出现的次数,而非客户端的参与数,从而完成超网权重参数的更新。
30、而且,所述框架的工作流程为:
31、s1、服务器初始化超网和架构参数αk,其中αk的初始值均为0,表示每个候选操作被选中的概率相等;
32、s2、随机抽取m个客户端开始本轮学习训练,服务器为这些客户端分配不同架构的子网模型,即根据αk采样出的子网wk发送给客户端k;
33、s3、客户端k接收到来自服务器的子网wk后,利用自己的本地训练集对权重参数进行更新训练,得到w′k;
34、s4、客户端对w′k进行准确率测试,得到准确率结果acck,并将w′k与acck共同报告给服务器;
35、s5、服务器收集到m个客户端的结果报告之后,从历史信息表中获取当前每个客户端的架构参数αk,计算每个客户端对应的奖励rk,并更新αk;
36、s6、服务器得到更新之后αk,更新历史信息表,并对所有客户端的训练结果执行权重参数的聚合操作,从而完成超网的权重参数更新;
37、s7、重复s2~s6,直至所有客户端的准确率结果达到收敛状态。
38、本发明的优点和有益效果为:
39、1、本发明采用基于强化学习的个性化模型搜索框架,对于客户端而言,仅需要对服务器分配的模型进行训练和报告准确率结果,这不会给客户端增加额外的负担,与fedavg保持一致,对于移动设备场景有很好的适配性。
40、2、本发明的每个客户端均可获得独特结构的个性化模型,强化学习不断为每个客户端搜索最优的模型结构,结合联邦学习的形式,各客户端协同训练模型参数。最终每个客户端均可获得最佳个性化模型。
41、3、经过实验证明,本发明的个性化模型搜索框架与fedavg对比,可提高6.59%~17.79%的平均准确率;与首篇联邦nas方法fednas对比,可减少70.52%~72.02%的系统运行时间。
本文地址:https://www.jishuxx.com/zhuanli/20240808/271627.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。