一种面向多源异构数据的Hudi数据摄取方法及系统与流程
- 国知局
- 2024-08-22 14:38:41
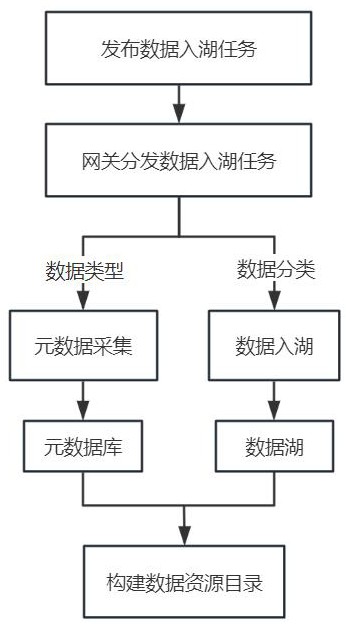
本发明属于数据处理,具体涉及一种面向多源异构数据的hudi数据摄取方法及系统。背景技术::1、随着大数据技术的发展,一些企业和机构面临的数据类型越来越多样化,包括结构化数据、半结构化数据和非结构化数据,这些数据分别来自不同的数据源。例如,高校智慧教育平台,其中涉及到的数据来源包含关系型数据库、日志文件、传感器数据、监控视频流等。数据湖作为一种新兴的数据管理架构,提供了一个集中化的数据存储仓库,能够存储和管理不同来源、不同类型的数据。元数据管理对于数据湖至关重要,缺乏适当的元数据管理会导致数据湖成为数据沼泽,使得用户无法有效的分析和利用湖内数据。2、为了处理大量多源异构数据,需要采用先进的数据处理技术和数据湖框架。apache flink是目前非常流行的开源流处理框架,用于实时数据流的处理和分析。flink支持事件驱动的流处理和批量数据处理,能够在各种集群环境中运行;flink提供丰富的api进行数据处理,如streaming api、table api,并且支持多种与外部系统的连接器。3、apache hudi是当前最主流的开源数据湖框架之一,专为存储大规模分析类数据而设计,支持插入、更新和删除操作。hudi支持高效的增量数据处理,允许用户只处理自上次查询以来变化的数据;hudi提供数据版本控制机制,能够追踪数据的历史变化;hudi可以与flink、spark、presto等多种计算引擎集成,提供端到端的数据流处理和分析解决方案。4、现有技术中对于多源异构数据的入湖处理存在以下问题:5、1、数据管理复杂性。数据来源错综复杂,难以适配各种数据的连接和传输。6、2、实时性要求。数据处理效率低下,影响数据入湖的实时性和准确性。7、3、数据安全性。入湖数据在传输过程中的安全性易受威胁,会增加数据泄露的风险。8、4、数据血缘与元数据管理。数据入湖过程中,维护数据血缘和元数据是一个挑战,影响着数据的可追溯性和管理性。9、针对上述问题,可以引入网关架构对数据入湖进行优化,网关将数据进行统一管理和分发入湖,大大提高了工作效率。技术实现思路1、为了解决背景技术:中提出的问题,本发明提供一种面向多源异构数据的hudi数据摄取方法及系统,能够集中管理和处理来自不同数据源的数据,允许不同系统和应用程序通过统一的接口与数据湖进行交互,简化了数据集成和数据访问的过程,有助于降低系统的复杂性和总体拥有成本。网关架构作为数据入湖的统一入口,将结构化数据、半结构化数据和非结构化数据分发给适配的入湖控制器执行数据入湖,同时根据数据类型调用适配的元数据采集程序对元数据进行采集,将元数据持久化存储至元数据库中。系统能够构建数据资源目录,该数据资源目录向用户展示数据湖中存储的各种数据的详细信息,方便用户查询和使用数据。2、术语解释:3、flink:flink是一个开源的流处理框架,它允许用户在无限数据流上进行有状态的计算。4、hudi:hudi(hadoop upserts deletes and incrementals)是一个开源的数据湖框架,用于管理存储在分布式文件系统或云存储服务上的大规模数据集。5、flink cdc:flink cdc(change data capture)是基于数据库日志变化的实时数据集成框架,它可以捕捉数据库中的数据变动,并将这些变动作为事件流在flink程序中进行处理、分析和转换。6、hdfs:hdfs(hadoop distributed file system)是一个分布式文件系统,用来存储大量数据,并且可以分布在多个物理机上。7、minio:minio是一个高性能的对象存储服务器,兼容amazon s3云存储服务的api。8、本发明的技术方案为:9、一种面向多源异构数据的hudi数据摄取方法,包括:10、发布数据入湖任务:上传入湖任务的相关信息,发布入湖任务,入湖任务的相关信息包括任务标题、数据连接配置和数据类型;11、网关分发数据入湖任务:由apache flink作为数据入湖处理引擎,由网关统一管理和分发数据入湖任务,根据数据类型进行适配的元数据采集,根据数据分类执行适配的数据入湖;12、执行数据入湖任务:采用apache hudi作为数据湖架构,通过数据入湖处理引擎将原始数据从数据源传输到数据湖中进行存储,同时采集原始数据的元数据信息,并将原始数据的元数据信息持久化存储到元数据库中;13、构建数据资源目录:根据采集的元数据以及元数据在数据湖中的相关信息构建数据湖的数据资源目录。14、进一步优选的,数据类型包括mysql数据、json数据、日志文件、视频流数据、图像数据、音频数据和文本文档,每种数据类型具有唯一标识id,且可扩展。15、根据本发明优选的,网关用于数据源适配、数据中转和数据传输;16、数据源适配用于与不同的数据源进行交互,抽取原始数据;17、数据中转用于对入湖数据进行转发,用于适配的元数据采集和数据入湖;18、数据传输用于将数据处理后的数据传输到数据湖中。19、根据本发明优选的,元数据采集过程中,每一种数据类型对应一个元数据采集程序,不同数据类型的数据分别由与之适配的元数据采集程序进行元数据采集;数据类型即入湖任务中的数据类型,具有唯一的标识id,并且可以进行扩展。网关根据用户上传的入湖任务中的数据类型调用适配的元数据采集程序,实现元数据的自动采集;20、数据入湖过程中,由apache flink作为数据入湖处理引擎,入湖数据按照数据的组织形式和特点划分为结构化数据、半结构化数据和非结构化数据三类,每类数据的入湖方式不同,通过不同的入湖控制器进行数据入湖。21、进一步优选的,mysql数据属于结构化数据,由结构化入湖控制器负责数据入湖;json数据和日志文件属于半结构化数据,由半结构化入湖控制器负责数据入湖;视频流数据、图像数据、音频数据和文本文档属于非结构化数据,由非结构化入湖控制器负责数据入湖。22、进一步优选的,结构化入湖控制器采用flink cdc方式进行数据入湖。23、进一步优选的,半结构化入湖控制器负责数据入湖,入湖方式包括数据格式转换和映射关系建立;数据格式转换是指将半结构化数据解析、转换成结构化数据,根据转换后的数据结构定义hudi表的结构,将转换后的数据存储到hudi表中,以hdfs作为底层存储,方便用户查询和分析数据;映射关系建立是指创建半结构化数据的原始文件与对应hudi表之间的映射关系。24、进一步优选的,非结构化入湖控制器负责数据入湖,入湖方式包括原始文件入湖和特征元数据入湖;原始文件入湖是指将非结构化数据直接从数据源存储到minio中,实现原始数据入湖;特征元数据入湖是指为非结构化数据创建元数据记录,元数据记录包括数据文件名称和指向minio中的非结构化数据的链接,根据元数据记录定义一个hudi表来存储元数据,通过查询hudi表即获取对应非结构化数据的存储位置信息。25、根据本发明优选的,采用apache hudi作为数据湖架构,底层存储中以分布式文件系统hdfs存储结构化数据和半结构化数据,以对象存储服务minio存储非结构化数据,采集到的元数据包括基础元数据和关系元数据,分别存储于关系型数据库mysql和图数据库neo4j;所述基础元数据包括数据的名称、大小、类型、修改时间和各种参数,所述关系元数据包括数据表的上游表、下游表信息和数据字段的上下游信息。26、根据本发明优选的,通过将元数据和hudi的管理机制相结合构建出数据资源目录, hudi的管理机制包括hudi的timeline、文件布局和索引机制;数据资源目录以下数据和信息:27、元数据:描述数据的基本特征;28、数据血缘:展示数据的来源和流动路径,包括数据是如何被创建、处理、转换和消费的;29、数据分类和标签:用于数据分类的标签和分组;30、数据字典:包括数据字段的数据格式、数据含义和详细描述;31、数据使用情况:数据被访问和使用的统计信息;32、数据版本信息:数据的历史版本,包括数据的更新记录和变更日志;33、数据存储位置:数据在数据湖中的物理存储位置;34、数据访问接口:提供访问数据的api和数据服务接口。35、一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现一种面向多源异构数据的hudi数据摄取方法的步骤。36、一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现一种面向多源异构数据的hudi数据摄取方法的步骤。37、一种面向多源异构数据的hudi数据摄取系统,包括:38、入湖任务发布模块,被配置为:上传入湖任务的相关信息,发布入湖任务,入湖任务的相关信息包括任务标题、数据连接配置和数据类型;39、网关模块,被配置为:由apache flink作为数据入湖处理引擎,由网关统一管理和分发数据入湖任务,根据数据类型进行适配的元数据采集,根据数据分类执行适配的数据入湖;40、数据入湖模块,被配置为:采用apache hudi作为数据湖架构,通过数据入湖处理引擎将原始数据从数据源传输到数据湖中;41、数据存储模块,被配置为:采用hudi作为数据湖管理框架,以分布式文件系统hdfs和对象存储服务minio作为底层存储,采集原始数据的元数据信息,并将原始数据的元数据信息持久化存储到元数据库中;42、数据管理构建模块,被配置为:根据采集的元数据以及元数据在数据湖中的相关信息构建数据湖的数据资源目录。43、本发明的有益效果为:44、本发明提供一种面向多源异构数据的hudi数据摄取方法及系统,通过网关架构对所有数据流进行集中管理,简化来自不同源的数据集成过程,降低系统的复杂性和总体拥有成本。第一,增强数据安全性,网关可以实施安全策略,如认证、授权、加密等,从而增强数据传输的安全性;第二,提高数据质量和一致性,网关可以在数据入湖之前进行数据清洗和标准化,确保数据的质量和一致性;第三,支持数据源的实时变更,网关可以实时处理数据源的变化,如数据库插入、更新、删除操作。第四,提供数据血缘和元数据管理,网关可以收集和维护数据的血缘信息,提供数据来源、流动和转换的详细记录。当前第1页12
本文地址:https://www.jishuxx.com/zhuanli/20240822/279356.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。