多模态融合的大脑视觉神经活动表征的对齐方法
- 国知局
- 2024-08-30 14:29:49
本发明属于生物医学工程、人工智能,尤其涉及一种多模态融合的大脑视觉神经活动表征的对齐方法。
背景技术:
1、大脑可以揭示有关人类认知、情绪、行为和知觉的各种信息。而视觉信息解码作为一种理解大脑执行视觉任务的方法。基于功能磁共振图像(fmri)的大脑视觉刺激表征对齐技术主要是为了在特征层进行表征增强,进而从大脑活动模态提取出更加有效的语义表征进行脑解码的相关任务与分析;最初人们大多是局限于单模态(大脑活动-视觉刺激图像)在特征空间对齐,如在2017年,horikawa等人提出了一种能够从fmri数据中预测视觉特征的回归方法,它使用了大脑活动与对应视觉图像对齐,这种方法不仅能识别被看到或想象中的物体类别,还揭示了人脑视觉与机器视觉之间的相似性及其在大脑信息检索中的应用潜力。随后在特征层对齐有了更多尝试,如引入刺激源的文本模态来引发模型学习到大脑里的文字语义信息,来增强对齐的深度。如在2023年,du等人提出的bravl,一种多模态自编码变分贝叶斯学习框架,通过mopoe(专家乘积混合)对齐三种模态(大脑活动-图像-文本),并通过在图像-文本对中训练svm分类器来利用fmri信号的输入,研究结果显示,使用视觉和文本特征组合的模型比单模态模型表现得更好,在结果上取得了一些改进。又比如liu等人在后来提出的brainclip同样使用了clip(contrastive language-image pre-training)模型来对齐多模态表征,使用这一对齐框架在后续的脑解码下游任务完成了一系列的提升;甚至包括后来的chen等人提出的mindvideo使用三元组来进行多模态对齐,在脑解码的视频解码任务中取得了非常不错的效果。
2、目前,现有的多模态大脑视觉刺激语义表征对齐的方法已经有不错的效果,但存在一个重要的问题,即视觉活动同时对齐图像和文本时产生的对齐模糊问题(参考图1),一种把视觉刺激下的大脑活动与目标多模态(图像模态、文本模态或者其他模态)的语义表征对齐时,由于目标模态在特征空间上分布的差异性导致的对齐不准确不充分的问题。。
技术实现思路
1、本发明针对现有技术不足,提出了一种将视觉刺激下的大脑活动与视觉刺激源的图像、文本的多模态的融合语义表征对齐,解决了多模态对齐时的对齐模糊问题,提升了语义信息的对齐效果。
2、本发明采用的技术方案为:
3、多模态融合的大脑视觉神经活动表征的对齐方法,该方法包括下列步骤;
4、步骤1,使用预训练好的clip文本编码器将视觉刺激的文本嵌入到clip语义特征空间,得到文本语义特征表征;使用预训练好的clip图像编码器将视觉刺激的图像嵌入到clip语义特征空间,得到图像语义特征表征;即基于clip文本编码器和clip图像编码器获取具有泛化性的视觉刺激的语义特征表征;其中,文本语义特征表征与图像语义特征表征的特征维度相同;
5、步骤2,使用视觉刺激语义融合模块对文本语义特征表征和图像语义特征表征进行特征空间的融合,以获取多模态融合语义信息表征;
6、步骤3,使用大脑语义信息编码器将指定的全脑的主要视觉区域的响应信号转换为隐特征空间向量表征,并加入来自被试信息的提示嵌入(prompt embedding)得到具有语义信息的视觉响应信号特征,即大脑语义信息表征;基于加入的提示嵌入来加强模型的被试通用性,目的是训练这个编码器来获取具有语义信息的大脑表征;
7、步骤4,使用对比学习将步骤2的多模态融合语义信息表征与步骤3的大脑语义信息表征进行特征空间的对齐;
8、基于设置的训练数据,迭代步骤1-4训练视觉语义融合模块与大脑语义信息编码器以得到用于大脑视觉神经活动表征对齐的视觉语义融合模块和大脑语义信息编码器。
9、进一步的,本发明还包括步骤5,使用训练好的视觉语义融合模块与大脑语义信息编码器,进行表征类别检索分类。
10、进一步的,在步骤1中,采用clip图像编码器的vit-l/14版本,并基于vit-l/14版本对应的clip文本编码器作为预训练好的clip文本编码器。
11、进一步的,在步骤2中,视觉刺激语义融合模块采用变分自编码(vae)融合文本语义特征表征和图像语义特征表征,得到一个同时包含图像和文本语义信息的图文特征z(即多模态融合语义信息表征),可以用公式表示为:
12、z=vae(i,t;wvae) (1)
13、其中,i和t分别表示图像语义特征和文本语义特征,wvae表示vae所有网络的权重,z表示多模态融合语义信息表征。
14、使用变分自编码(variational autoencoder,vae)在潜在空间(latent space)对得到的图像语义表征、文本语义表征进行特征融合,其中vae内部处理为,图像模态与文本模态会分别训练一个图像编码器与文本编码器,各编码器会生成对应的均值向量(meanvector)μ与方差对数向量∑(log-variance vector),并且使用moe(mixture of experts)模型的思想为每个图像-文本对设置一个通用的门控学习网络(gating network)来动态学习混合两个模态的权值,学习到的参数按权值来线性混合两个模态的均值向量μi与μt,以及方差对数向量∑i与∑t,生成混合的均值向量μfusion与方差对数向量∑fusion,通过vae的reparameterization重参数化来生成潜在空间语义表征zfusion,具体的从一个标准正态分布中采样一个随机噪声∈(即∈~n(0,1)),然后使用这个噪声来计算zfusion,具体的计算公式如下:
15、zfusion=μfusion+∑fusion⊙∈ (2)
16、最后,通过vae的图像解码器与文本解码器,将潜在空间语义表征zfusion解码为图像表征与文本表征进行重构,从而得到多模态融合语义信息表征z。
17、进一步的,在步骤3中,大脑语义信息编码器的编码过程具体为:
18、步骤3中,使用门控循环单元(gated recurrent unit,gru)来提取大脑视觉特征,具体公式如下:
19、b=gru(v1,v2,...,vt;wgru) (3)
20、其中,b表示视觉特征;gru表示门控循环单元;v1,v2,...,vt表示t个主要视觉区域的视觉活动的响应信号),wgru表示gru的参数集合;
21、步骤301,选取自然场景数据集中的主要视觉区域,例如将主要视觉区域设置为:“v1”,“mst”,“v6”,“v2”,“v3”,“v4”,“v8”,“v3a”,“v7”,“ips1”,“ffc”,“v3b”,“lo1”,“lo2”等21个视觉区域;
22、使用转换层(reshape)将不同视觉区域的视觉活动的响应信号(简称脑区信号)统一到指定维度num,得到每个主要视觉区域的响应信号特征表征,其中,num用于表征文本语义特征表征和/或图像语义特征表征的特征维度;
23、再拼接t个主要视觉区域响应信号特征表征得到t×num维的原始响应信号(即原始脑区信号);
24、步骤302,基于clip文本编码器将原始响应信号的来源被试信息编码为提示嵌入,再将该提示嵌入拼接到原始响应信号后,得到(t+1)×num维的视觉响应信号特征;以手动增强被试间的差异,使得模型学习到不同被试的差异;
25、步骤303:将(t+1)×num维的视觉响应信号特征送入gru神经网络中,以t+1作为gru神经网络的序列维度(从而学习到来自t个主要视觉区域包含的视觉刺激语义信息),并取最后一个1×num作为输出,得到一个1×num的全脑视觉区域的视觉刺激语义表征(大脑语义信息表征),以用于后续对齐。
26、进一步的,步骤4具体包括:
27、步骤401,仅对步骤3中的vae进行预训练,vae预训练时采用的损失函数lvae包括vae重构损失与kl(kullback-leibler divergence)散度损失,即两者的加权和,本发明中,可将其权重军设置为1,对应的表达式为:
28、
29、其中重构损失为:
30、
31、kl散度损失为:
32、
33、其中,表示数学期望;pθ(x|z)表示解码器的输出;p(z)表示潜在变量z的先验分布;qφ(z|x)表示由编码器网络参数化的后验分布;j表示潜在空间z的维度;σj、μj分别表示第j个潜在变量的标准差与均值。
34、采用损失函数lvae的目的是为了得到能提取稳定语义表征的变分自编码器;
35、步骤402,将步骤303得到的1×num的大脑语义信息表征使用clip式的对比学习方法与步骤2得到的多模态融合语义信息表征进行对比学习特征空间对齐,其采用的损失函数为对比损失函数lcon,其表达式为:
36、
37、其中,n表示样本总量;n表示上限索引;sim(·)表示余弦相似度;(ai,bi)表示第i个样本的多模态融合语义信息表征(即图文特征)和大脑语义信息表征(视觉特征)组成的正样本;(ai,bj)表示第i个样本的图文特征和第j个样本的视觉特征组成的负样本;τ表示温度系数。
38、步骤403,同时训练vae与gru,训练时采用的总损失设置为:
39、ltotal=lcon+lvae (8)
40、即总损失可以设置为lcon与lvae的加权和,优选的,权重系数可军设置为1。
41、同时训练vae与gru的目的是为了增强全脑视觉区域的视觉刺激语义表征的语义信息。
42、进一步的,在步骤5中,使用余弦相似度作为指标进行类别检索。
43、本发明提供的技术方案至少带来如下有益效果:
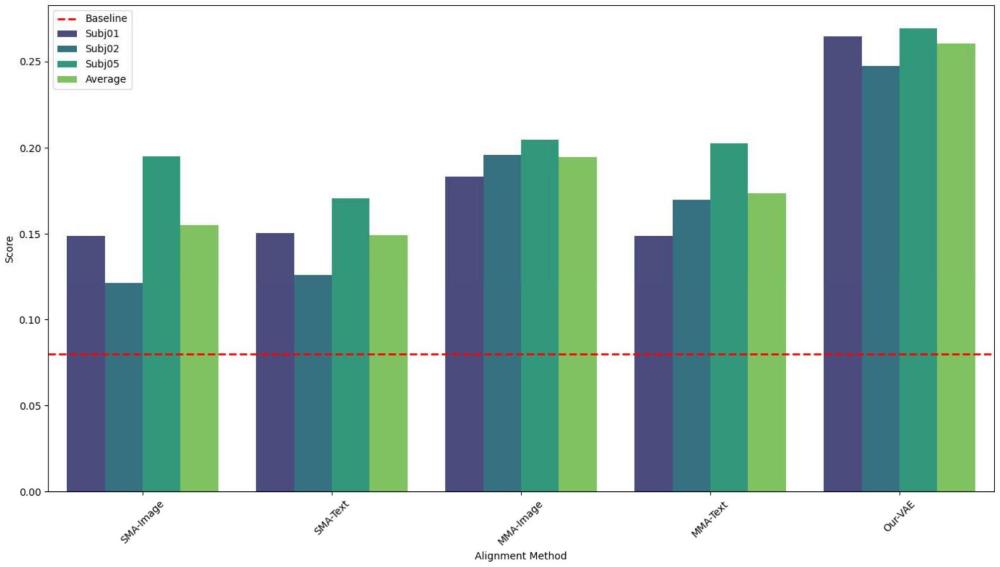
44、首先本发明使用预训练变分自编码器来融合来自不同模态的语义信息到统一空间,后续进行对比学习表征对齐时,对齐深度的类别检索性能上较先前的单模态对齐有显著提升,可提升80%,较常规的多模态对齐方法提升了50%,一定程度解决了多靶点模态对齐时的对齐模糊问题;其次使用prompt embedding将被试信息嵌入到输入,模型具备了识别不同被试信号的能力,为通用性解码提出新思路。
本文地址:https://www.jishuxx.com/zhuanli/20240830/282352.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表