基于全局和局部动作优化的长序列舞蹈生成方法
- 国知局
- 2024-08-30 14:32:33
本发明涉及人物舞蹈动作生成技术,特别是涉及一种基于全局和局部动作优化的长序列舞蹈生成方法。
背景技术:
1、现有的舞蹈生成方法主要有以下几种方案,包括运动图方法,基于序列模型的方法,基于生成对抗网络的方法,基于向量量化变分自编码器的方法和基于扩散的方法。传统的基于运动图的方法将这一任务作为基于相似性的检索问题来解决,这限制了生成的多样性和创造力。在基于序列的方法中,常用的是长短期记忆递归神经网络(lstm)和变换器(transformer)。这些网络通常将音乐和之前的舞蹈序列作为输入,以自回归的方式预测接下来的舞蹈,但自回归存在误差积累和运动冻结现象。生成对抗网络(gan)由一个生成器和一个鉴别器组成,进行对抗性训练以产生真实的数据,但是基于gan的方法存在模式崩溃和训练不稳定的问题。
2、近期的一些研究了转向向量量化变分自编码器(vq-vae)和扩散模型。vq-vae通过将连续嵌入离散到一组有限的代码中,有效地与自回归解码器集成以产生高质量的输出,在生成任务中表现出色,但码本的使用也对生成的舞蹈的多样性造成了一定的限制。扩散模型有效地处理复杂的数据分布,产生高质量的样本,并自然地集成噪声,增强了其在不同应用中的鲁棒性和通用性。然而,现有模型通常只注重细节的舞蹈片段,无法快速生成符合整体编排规律的长期舞蹈动作,并且没有关注对于舞蹈呈现较为重要的手指运动生成。
3、cn115578490a公开了一种基于标准化生成流的可控制舞蹈动作生成方法,包括:构建基于标准化生成流的舞蹈动作生成模型,使用开源音频-舞蹈数据集对该舞蹈动作生成模型进行训练;设定目标舞蹈动作序列的关键帧,以该关键帧和目标音频生成控制信号,由该舞蹈动作生成模型将原始舞蹈动作序列隐射为高斯空间的原始隐变量;由该舞蹈动作生成模型从该高斯空间采样得到的目标隐变量,通过该控制信号条件生成该目标舞蹈动作序列。
4、cn117316129a公开了一种全新的基于多模态特征融合的音乐生成舞蹈姿态的方法、设备及存储介质,属于音频驱动舞蹈姿态领域,所述的网络框架及方法包括两个主要阶段:1)训练阶段,将舞蹈分解为一系列基本的舞蹈单元,通过这些单元,模型学习如何移动。2)生成阶段,模型通过根据输入的音乐无缝地组织多个基本舞蹈动作来学习如何创作舞蹈。
5、现有技术存在以下不足:
6、(1)现有的技术方法在生成舞蹈时,由于其生成任务的处理方式或者使用的模型结构,往往会限制生成舞蹈的多样性和创新性。
7、(2)现有的方法可能会出现误差积累和运动冻结现象,这可能影响到生成舞蹈的连贯性和自然性。
8、(3)现有技术可能存在模式崩溃和训练不稳定的问题,这可能导致生成的舞蹈质量不稳定。
9、(4)现有的技术通常只注重细节的舞蹈片段,无法快速生成符合整体编排规律的长期舞蹈动作。
10、(5)现有的技术在生成舞蹈动作时,往往没有足够关注对舞蹈表现至关重要的手部动作生成。
11、在现有的舞蹈动作生成方法中,尤其是长序列舞蹈的生成,存在动作自然性、连贯性和音乐同步性的挑战。一方面生成的舞蹈无法建模全局编舞规律,另一方面生成的舞蹈在局部动作质量还存在脚滑,抖动等问题。如何有效地利用音乐和舞蹈流派信息,以生成高度自然和精确的舞蹈动作序列,同时确保动作在长时间跨度内的连贯性,多样性和整体舞蹈结构,并提高舞蹈生成的动作质量和真实感是本发明主要解决的问题。
12、需要说明的是,在上述背景技术部分公开的信息仅用于对本技术的背景的理解,因此可以包括不构成对本领域普通技术人员已知的现有技术的信息。
技术实现思路
1、本发明的主要目的在于克服上述背景技术的缺陷,提供一种基于全局和局部动作优化的长序列舞蹈生成方法。
2、为实现上述目的,本发明采用以下技术方案:
3、一种基于全局和局部动作优化的长序列舞蹈生成方法,包括如下步骤:
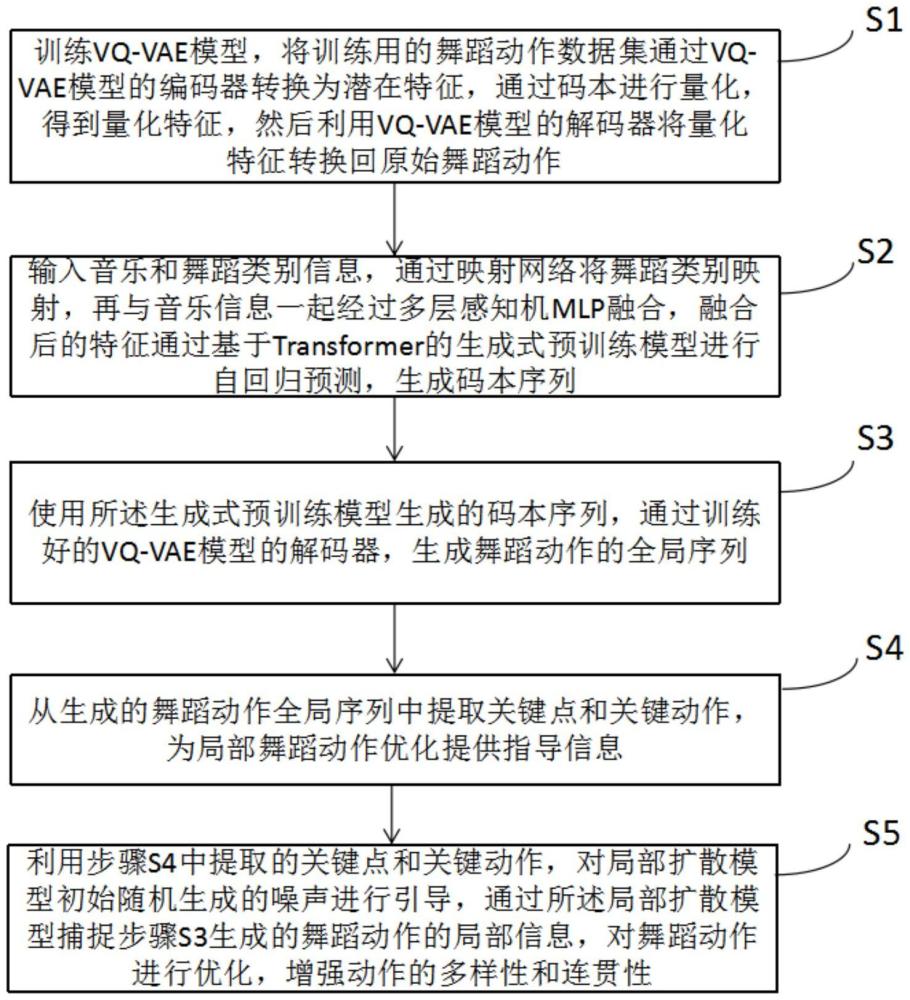
4、s1:训练vq-vae模型,将训练用的舞蹈动作数据集通过vq-vae模型的编码器转换为潜在特征,通过码本进行量化,得到量化特征,然后利用vq-vae模型的解码器将量化特征转换回原始舞蹈动作;
5、s2:输入音乐和舞蹈类别信息,通过映射网络将舞蹈类别映射,再与音乐信息一起经过多层感知机mlp融合,融合后的特征通过基于transformer的生成式预训练模型(或称生成式预训练变换器,简称gpt)进行自回归预测,生成码本序列;
6、s3:使用所述生成式预训练模型生成的码本序列,通过训练好的vq-vae模型的解码器,生成舞蹈动作的全局序列;
7、s4:从生成的舞蹈动作全局序列中提取关键点和关键动作,为局部舞蹈动作优化提供指导信息;
8、s5:利用步骤s4中提取的关键点和关键动作,对局部扩散模型初始随机生成的噪声进行引导,通过所述局部扩散模型捕捉步骤s3生成的舞蹈动作的局部信息,对舞蹈动作进行优化,增强动作的多样性和连贯性。
9、进一步地:
10、步骤s1包括:
11、s11:使用vq-vae模型的编码器将输入的舞蹈动作转换为潜在特征向量;
12、s12:通过码本量化过程,将潜在特征向量映射到最接近的码本元素;
13、s13:使用vq-vae模型的解码器将量化后的码本元素转换回舞蹈动作。
14、步骤s2包括:
15、s21:将音乐信号作为输入,通过映射网络将音乐特征映射到高维空间;
16、s22:将舞蹈类别信息通过映射网络映射到与音乐特征相匹配的高维空间;
17、s23:使用多层感知机mlp融合音乐特征和舞蹈类别特征;
18、s24:所述生成式预训练模型利用自回归机制,基于融合后的特征生成码本序列。
19、步骤s5中,所述局部扩散模型的transformer模块包括自注意力层,交叉注意力层,多层感知层和特征级线性调制film。
20、步骤s5中,使用关键点和关键动作对局部扩散模型初始随机生成的噪声进行引导时,使用gpt模型生成的数据覆盖掉部分关节和关键帧对应的位置,替换掉随机生成的部分,并将经过覆盖的更新数据输入所述局部扩散模型,最终生成舞蹈动作。
21、步骤s5中,还引入足部接触引导模块和碰撞引导模块,所述足部接触引导模块用于模拟足部与地面的接触,减少生成舞蹈中的足滑现象;所述碰撞引导模块用于减少生成舞蹈中的穿模现象,提高动作的真实性。
22、所述关键动作包括手部动作。
23、一种计算机可读存储介质,存储有计算机程序,所述计算机程序由处理器执行时实现所述的基于全局和局部动作优化的长序列舞蹈生成方法。
24、一种计算机程序产品,所述计算机程序产品由处理器运行时实现所述的基于全局和局部动作优化的长序列舞蹈生成方法。
25、与现有技术相比,本发明的有益效果有:
26、本发明提供一种基于全局和局部动作优化的长序列舞蹈生成方法,结合向量量化变分自编码器(vq-vae)、基于transformer的生成式预训练模型和扩散模型的协同作用,有效提高了长序列舞蹈生成的自然性和连贯性,解决了现有舞蹈生成技术在长时间跨度内的连贯性、多样性不足和舞蹈质量不稳定等问题,实现更加流畅和真实的舞蹈动作序列,增加了生成舞蹈的表现力和互动性。并且,本发明还解决现有舞蹈生成技术在长序列舞蹈生成中局部舞蹈动作如手部动作表现力不足的问题,通过精细化的手部动作等局部舞蹈动作学习,使生成的舞蹈动作不仅在视觉上更加吸引人,也更加符合人类舞蹈的自然动作规律。同时,本发明的长序列舞蹈生成方法通过算法整体设计优化,提高了训练和生成的效率,避免了大量计算资源的消耗,降低了成本。
27、本发明实施例的优点还包括:
28、(1)通过针对手部动作的生成进行优化,解决了现有技术中缺乏手指动作生成的问题。
29、(2)通过引入足部接触指导和碰撞指导,实现舞蹈动作位置信息的精确控制,同时也提高舞蹈动作的流畅性和自然度,对应用于虚拟现实、电影制作和舞蹈训练等有其重大意义。
30、(3)通过更精细的手部动作生成和更有效的位置引导机制,提供了一种新的解决方案,用于生成更为复杂和多样化的长序列舞蹈动作,满足对高质量舞蹈内容的需求。
31、本发明实施例中的其他有益效果将在下文中进一步述及。
本文地址:https://www.jishuxx.com/zhuanli/20240830/282592.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表