一种细粒度语义代码克隆检测方法
- 国知局
- 2024-08-30 14:34:51
本发明涉及计算机,尤其涉及一种细粒度语义代码克隆检测方法。
背景技术:
1、随着计算机和软件领域的不断进步和发展,软件代码的规模越来越大。因此,为了节省时间和精力,许多软件开发人员会选择克隆具有相似功能的代码来构建和维护软件代码。广泛的代码克隆在一定程度上给软件开发带来了便利,并产生积极的效益,但这也降低了软件的安全性,增加了维护成本。例如,如果复制的代码包含任何漏洞,则该漏洞将在整个软件系统中传播,尤其是在漏洞代码被多次复用后,漏洞的影响范围会呈指数级别扩大。因此,寻找一种能够从大量源代码中高效检测代码克隆的自动方法是必不可少的。
2、在代码克隆检测的研究领域中,研究工作主要围绕两大类方法展开,即关注效率提升的可扩展性克隆检测与针对深层语义理解的语义克隆检测。对于可扩展性克隆检测技术,主流方法包括基于文本和基于token两种方法,它们将源代码转换为文本或token序列,并通过一系列相似度计算算法来实现对克隆代码的快速分析。尽管此类方法在速度上表现优异,但由于其缺乏代码语义信息的考虑,故无法有效处理具有语义相似性的克隆。为此,研究者进一步提出了基于代码中间表示(如控制流图、程序依赖图等)的语义克隆检测方案,这些方法通过构建和分析蕴含了程序语义特征的图结构进行克隆检测。然而,由于创建和解析复杂的图结构耗时且计算成本较高,导致这类方法在处理大型数据集时难以保证良好的可扩展性能。而基于抽象语法树(ast)的克隆检测技术相比于基于图的方法更为轻量级,但因ast自身的复杂层次特性,在进行相似性比较时仍会导致较高的时间开销。
3、另外,当前的克隆检测工具无法准确识别克隆对之间的相似部分,特别是在处理语义代码克隆时。具体表现为,当面临包含大量代码行的克隆代码,而实际的安全问题所在仅仅集中于其中几行关键代码的情况下,现有的克隆检测技术往往难以有效定位这些隐藏的安全漏洞或缺陷,自然也就无法快速进行针对性的修复。而这些安全漏洞如果隐藏在语义克隆代码中,那么对其进行定位和修复将会更加困难重重。
技术实现思路
1、为了提高代码克隆检测的检测效率且准确识别克隆对之间的相似部分,本发明提供一种细粒度语义代码克隆检测方法。
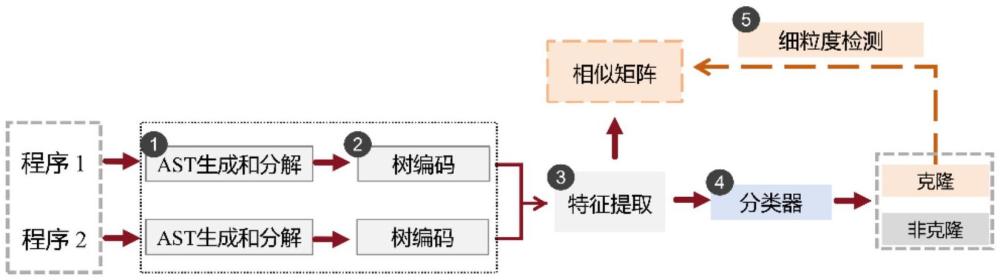
2、本发明提供的一种细粒度语义代码克隆检测方法,包括:
3、步骤1:分别生成两个目标代码的抽象语法树ast,并分别对两个目标代码的ast进行分解以各自得到多个子树;
4、步骤2:分别对两个目标代码的多个子树进行树编码,得到两个目标代码的自由度矩阵;
5、步骤3:根据两个目标代码的自由度矩阵计算两个目标代码的相似性矩阵,并利用所述相似性矩阵中的值来表征两个目标代码中对应代码块之间的相似度,值越小,两个代码块的相似度越大;
6、步骤4:将所述相似性矩阵转换为相似性向量,将所述相似性向量输入至代码克隆检测模型中,得到检测结果。
7、进一步地,步骤1中,分别对两个目标代码的ast进行分解以各自得到多个子树,具体包括:
8、步骤a1:根据目标代码的ast中的语句类型对所述ast进行分解,得到各个语句类型对应的第一子树以及结构子树;所述结构子树为ast中除各个语句类型对应的第一子树之外的剩余子树;
9、步骤a2:对各个语句类型对应的第一子树中节点量最多的树结构进行再次分解,得到各个语句类型对应的第二子树。
10、进一步地,步骤2具体包括:
11、步骤b1:根据节点功能将两个目标代码的ast中的所有节点均划分为m种类型,并计算目标代码的ast中每种类型节点的自由度;
12、步骤b2:针对每个目标代码,分别遍历其各个子树以得到各个子树对应的m维自由度向量,将由所有第一子树和结构子树对应的m维自由度向量组成所述目标代码的第一自由度矩阵,将由所有第二子树对应的m维自由度向量组成所述目标代码的第二自由度矩阵。
13、进一步地,所述语句类型包括if语句、for语句、while语句、try语句和switch语句中的一种或多种。
14、进一步地,根据节点包含的子节点的数量来计算节点的自由度。
15、进一步地,根据两个目标代码的自由度矩阵计算两个目标代码的相似性矩阵,具体包括:
16、根据两个目标代码的自由度矩阵按照下式计算两个目标代码的相似性矩阵;
17、
18、其中,a和b表示两个目标代码的自由度矩阵;aij表示a中第i行第j列的元素值,bij表示自由度矩阵b中第i行第j列的元素值,n表示自由度矩阵的总行数。
19、进一步地,所述代码克隆检测模型采用随机森林算法。
20、本发明的有益效果:
21、(1)将一个复杂的抽象语法树ast进行分解,得到多个简单的子树,通过对各个简单的子树进行树编码,最终将复杂树结构转换成简单向量表示,从而降低了计算复杂度,提升代码克隆检测效率。
22、(2)通过树编码方式将组成ast的所有子树分别编码为自由度矩阵,该自由度矩阵中的一个行向量表征了一个子树的特征,通过向量之间的相似性来表征目标代码间各子树的相似度,因此根据两个目标代码的相似性矩阵可以准确识别和定位具体的代码克隆部分,实现了细粒度的语义克隆检测。
技术特征:1.一种细粒度语义代码克隆检测方法,其特征在于,包括:
2.根据权利要求1所述的一种细粒度语义代码克隆检测方法,其特征在于,步骤1中,分别对两个目标代码的ast进行分解以各自得到多个子树,具体包括:
3.根据权利要求2所述的一种细粒度语义代码克隆检测方法,其特征在于,步骤2具体包括:
4.根据权利要求2所述的一种细粒度语义代码克隆检测方法,其特征在于,所述语句类型包括if语句、for语句、while语句、try语句和switch语句中的一种或多种。
5.根据权利要求3所述的一种细粒度语义代码克隆检测方法,其特征在于,根据节点包含的子节点的数量来计算节点的自由度。
6.根据权利要求3所述的一种细粒度语义代码克隆检测方法,其特征在于,根据两个目标代码的自由度矩阵计算两个目标代码的相似性矩阵,具体包括:
7.根据权利要求1所述的一种细粒度语义代码克隆检测方法,其特征在于,所述代码克隆检测模型采用随机森林算法。
技术总结本发明提供一种细粒度语义代码克隆检测方法。该方法包括:步骤1:分别生成两个目标代码的抽象语法树AST,并分别对两个目标代码的AST进行分解以各自得到多个子树;步骤2:分别对两个目标代码的多个子树进行树编码,得到两个目标代码的自由度矩阵;步骤3:根据两个目标代码的自由度矩阵计算两个目标代码的相似性矩阵,并利用所述相似性矩阵中的值来表征两个目标代码中对应代码块之间的相似度,值越小,两个代码块的相似度越大;步骤4:将所述相似性矩阵转换为相似性向量,将所述相似性向量输入至代码克隆检测模型中,得到检测结果。技术研发人员:张雨,娄睿,王焕伟,董卫宇,刘春玲受保护的技术使用者:中国人民解放军战略支援部队信息工程大学技术研发日:技术公布日:2024/8/27本文地址:https://www.jishuxx.com/zhuanli/20240830/282821.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。