基于模仿学习和强化学习的码率自适应选择方法
- 国知局
- 2024-09-05 14:22:03
本发明涉及视频传输领域,具体涉及一种基于模仿学习和强化学习的码率自适应选择方法。
背景技术:
1、随着超高清视频、虚拟现实和其他视频流应用的发展,视频流量正在飞速增长,人们对于下载视频的感知体验质量需求也日益上升。基于超文本传输协议的动态自适应流(dynamic adaptive streaming over http,简称dash)具有能够减小媒体内容存储空间和传输带宽的优势,逐渐成为一种有前途的视频传输技术。在dash中,源视频在服务器端被切分成时长相同的块,每个块被编码成不同码率级别,客户端播放器使用码率自适应(adaptive bitrate,简称abr)算法,根据估计的网络状况和缓冲区占用情况为每个视频块选择合适的比特率版本,目标是最大化用户体验质量(quality of experience,简称qoe)指标。
2、abr算法主要分为两类:启发式方法和基于学习的方法。启发式方法通常手动选择特征,使用人工设计的规则建立状态到决策的关系模型。文献1[j.jiang,v.sekar,andh.zhang,“improving fairness,efficiency,and stability in http-based adaptivevideo streaming with festive,”ieee/acm trans.networking,vol.22,no.1,pp.feb.2014,doi:10.1109/tnet.2013.2291681.]提出了一种基于预测带宽(rate-based)的abr算法,选择受预测带宽约束的最大比特率值作为码率决策值。文献2[spiteri k,urgaonkar r,sitaraman r k.bola:near-optimal bitrate adaptation for onlinevideos[j].ieee/acm transactions on networking,2020,28(4):1698-1711.]利用李亚普诺夫优化理论根据缓冲区占用率进行码率决策。文献3[x.yin,a.jindal,v.sekar,andb.sinopoli,“a control-theoretic approach for dynamic adaptive video streamingover http,”in proceedings of the 2015acm conference on special interest groupon data communication,2015,pp.325–338.]综合考虑预测带宽和缓冲区占用,使用mpc框架最大化qoe指标。然而这些启发式方法采用固定的参数或模型进行决策,使算法无法在所有考虑到的场景中顺利工作。于是,研究者们借助深度强化学习方法无需手工设计,建立输入特征到码率选择输出的非线性关系模型。文献4[mao h z,netravali r,alizadehm.neural adaptive video streaming with pensieve[c]//proceedings of acmspecial interest group on data communication.new york,usa:acm press,2017:197-210.]提出了一种pensieve算法,利用actor-critic算法根据环境信息为未来视频块选择比特率。
3、然而,现有的基于学习的abr算法普遍表现出训练时间长、收敛速度慢等问题。另外,第五代移动通信网络(5g)对自适应视频流提出了更多的挑战。由文献5[e.ramadan,a.narayanan,u.k.dayalan,r.a.k.fezeu,f.qian,and z.-l.zhang,“case for 5g-awarevideo streaming applications,”in proceedings of the 1st workshop on 5gmeasurements,modeling,and use cases,2021,p.27–34.]可知,5g尤其是毫米波5g可以提供超高带宽,但由于信号阻塞等环境因素通常会出现较大的网络波动。文献6[a.narayanan,x.zhang,r.zhu,a.hassan,s.jin,x.zhu,x.zhang,d.rybkin,z.yang,z.m.mao,f.qian,and z.-l.zhang,“a variegated look at 5g in the wild:performance,power,and qoe implications,”in proceedings of the 2021acm sigcommconference,2021,pp.610–625.]证明了现有的基于学习的abr算法在剧烈波动的网络场景下无法保持高性能。因此,迫切需要一种新的码率自适应选择方法去解决上述问题。
技术实现思路
1、为了克服现有技术的不足,本发明提出了一种基于模仿学习和强化学习的码率自适应选择方法,针对现有基于学习的abr算法存在训练时间长、收敛速度慢等问题,通过引入专家策略进行模仿学习来达到快速收敛的目的。针对毫米波5g产生剧烈网络波动,通过将近端策略优化(proximal policy optimization,简称ppo)算法引入到策略网络的训练过程中来限制新旧策略更新的幅度,从而获得稳定有效的码率选择策略。
2、为了达到上述发明目的,本发明采用以下技术方案:
3、一种基于模仿学习和强化学习的码率自适应选择方法,所述方法包括以下步骤:
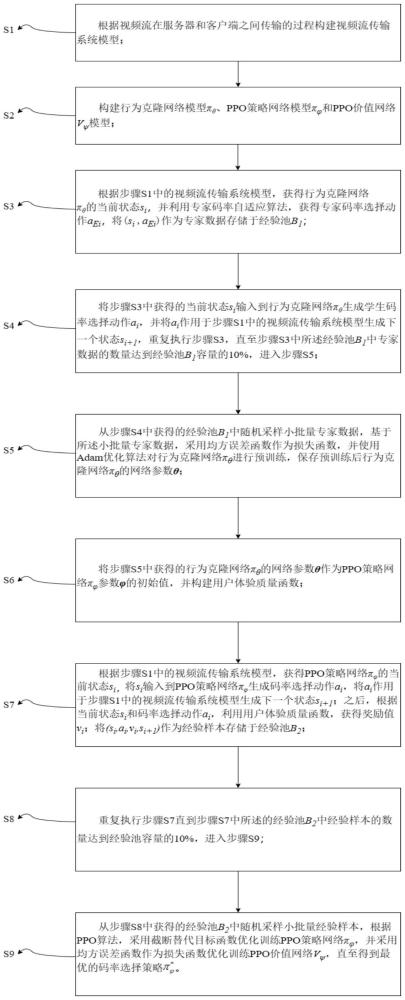
4、s1、根据视频流在服务器和客户端之间传输的过程构建视频流传输系统模型;
5、s2、构建行为克隆网络πθ模型、ppo策略网络模型和ppo价值网络vψ模型;
6、s3、根据步骤s1中的视频流传输系统模型,获得行为克隆网络πθ的当前状态si,并利用专家码率自适应算法,获得专家码率选择动作aei,将(si,aei)作为专家数据存储于经验池b1;
7、s4、将步骤s3中获得的当前状态si输入到行为克隆网络πθ生成学生码率选择动作ai,并将ai作用于步骤s1中的视频流传输系统模型生成下一个状态si+1,重复执行步骤s3,直至步骤s3中所述经验池b1中专家数据的数量达到经验池b1容量的10%,进入步骤s5;
8、s5、从步骤s4中获得的经验池b1中随机采样小批量专家数据,基于所述小批量专家数据,采用均方误差函数作为损失函数,并使用adam优化算法对行为克隆网络πθ进行预训练,保存预训练后行为克隆网络πθ的网络参数θ;
9、s6、将步骤s5中获得的行为克隆网络πθ的网络参数θ作为ppo策略网络参数的初始值,并构建用户体验质量函数;
10、s7、根据步骤s1中的视频流传输系统模型,获得ppo策略网络的当前状态si,将si输入到ppo策略网络生成码率选择动作ai,将ai作用于步骤s1中的视频流传输系统模型生成下一个状态si+1;之后,根据当前状态si和码率选择动作ai,利用用户体验质量函数,获得奖励值vi;将(si,ai,vi,si+1)作为经验样本存储于经验池b2;
11、s8、重复执行步骤s7直到步骤s7中所述的经验池b2中经验样本的数量达到经验池b2容量的10%,进入步骤s9;
12、s9、从步骤s8中获得的经验池b2中随机采样小批量经验样本,根据ppo算法,采用截断替代目标函数优化训练ppo策略网络并采用均方误差函数作为损失函数优化训练ppo价值网络vψ,直至得到最优的码率选择策略
13、进一步,所述步骤s1的过程如下:
14、假设服务器中的一个源视频被分为i块,每块的长度为l秒,每个块被编码为具有不同比特率的副本,将码率级别的有限集合表示为r={r1,r2,…,rn},ri表示第i个视频块的码率,ri∈r,i=1,...,i;第i个视频块的下载时间τi的计算公式如下:
15、
16、其中,si(r)表示码率为r的第i个视频块的大小,ti表示开始下载第i个视频块的时间,ct表示时刻t的下行带宽,δt表示往返rtt;
17、在客户端,缓冲区占用率bi描述了播放器开始下载第i个视频块时缓冲区的大小;当第i个视频块被下载后,缓冲区占用将增加l秒,而当视频块被播放时,缓冲区占用将会减少,缓冲区占用率动态表示为:
18、bi+1=[bi-τi]++l-δt (2)
19、其中,bi∈[0,bmax],bmax为缓冲区最大容量,如果bi+1<τi,则缓冲区在当前视频块下载期间会被耗尽,播放器将发生重新缓冲事件,直到新的视频块到达。
20、再进一步,在所述步骤s2中,所述行为克隆网络πθ模型包括一个输入层、一个隐藏层和一个输出层;在所述输入层,不同的输入类型使用不同的方法来提取底层特征,利用长短期记忆(long short term memory,简称lstm)网络去处理过去k个块的吞吐量预测值这个时间序列数据;对于过去k个块的下载时间和下一个块的大小这种连续尺度,利用一维卷积(1d-cnn)层提取有益信息;对于当前缓冲区大小、剩余块数量和下一个块的比特率这三种数据输入使用全连接网络来处理;将所述输入层的结果拼接后输入到所述隐藏层;所述输出层通过softmax函数生成一个概率分布,表示不同码率被选择的概率;所述ppo策略网络模型与行为克隆网络πθ模型结构相同;在所述ppo价值网络vψ模型中,输入层和隐藏层与行为克隆网络πθ模型的输入层和隐藏层相同,但是输出层是一个线性层,最终输出状态-动作对的价值。
21、更进一步,所述步骤s3中,所述当前状态si包括过去k个块的带宽预测值、过去k个块的下载时间、下一个块的大小、当前缓冲区大小、剩余块数量和下一个块的比特率;所述专家码率自适应算法使用robustmpc算法。
22、所述步骤s5中,所述小批量专家数据的批量大小为n,行为克隆网络πθ的损失函数构造如下:
23、
24、其中,ai为学生码率选择动作,aei为专家码率选择动作,αh(πθ(si))为熵正则项,α为熵正则项系数,h(πθ(·))表示策略πθ的熵;采用adam算法作为行为克隆网络πθ训练的优化算法,学习率设置为lr,当观察到损失不再下降时停止训练,确定epoch值,保存预训练后的行为克隆网络πθ的参数θ。
25、所述步骤s6中,所述用户体验质量(quality of experience,简称qoe)函数计算公式如下:
26、
27、其中,q(ri)表示给定码率的视频块的用户感知质量,[τi-bi]+表示重新缓冲时间,q(ri)-q(ri-1)表示视频质量的切换;μ和s分别是重缓冲和视频质量切换的惩罚权重;由于只有当分辨率从高质量显示降低到低质量显示时,才会出现负mos影响,因此,qoe不应该因为视频质量的提高而受到惩罚,所以将s定义为:
28、
29、所述步骤s9中,所述小批量经验样本的批量大小为n,所述截断替代目标函数计算公式如下:
30、
31、其中,表示新旧策略差异的比值,表示把的值限制在区间(1-ε,1+ε)内,ε为裁剪因子;为熵正则项,β为熵正则项系数;为优势函数,它使用广义优势估计法(generalized advantage estimator,gae)构造,计算公式如下:
32、
33、其中,γ为奖励折扣系数,v(·)表示状态估计值函数;
34、在优化训练的过程中动态地调整熵正则项系数β,关于β的损失函数构造为:
35、
36、其中,为策略的熵,h0表示目标熵;
37、所述均方误差损失函数的计算公式如下:
38、
39、其中,γ为奖励折扣系数,v(·)表示状态估计值函数;
40、采用adam算法作为模型训练的优化算法,ppo策略网络的学习率设置为lactor,ppo价值网络vψ的学习率设置为lcritic,β更新的学习率设置为lβ,当累计奖励值不再上升时停止训练,确定epoch值;经过优化训练,ppo策略网络提升为最优的码率选择策略
41、与现有技术相比,本发明的有益效果是:能够在5g网络中实现更高的用户体验质量,并且收敛速度快。
本文地址:https://www.jishuxx.com/zhuanli/20240905/286043.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表