一种基于深度学习算法的司机危险驾驶行为检测方法与流程
- 国知局
- 2024-09-05 14:43:57
本发明涉及人工智能,尤其是涉及一种基于深度学习算法的司机危险驾驶行为检测方法。
背景技术:
1、司机危险驾驶行为检测方法的主要任务是:检测司机是否存在危险驾驶行为,包括:离岗、疲劳驾驶和视线偏离;如果存在,则向监控系统输出报警信号。
2、目前针对司机疲劳驾驶这一种危险驾驶行为的检测方法有:基于传统图像处理的、基于对人眼识别的、基于单个关键点识别的,下面将从这几类方法中分析目前方法存在的问题。在基于传统图像处理的方法中,专利申请cn113255558a公开了一种基于单幅图像的司机疲劳驾驶低耗识别方法,该方法存在两个缺陷:1)使用静态的单幅图像无法判断司机的动态,司机眨眼会造成误报;2)该方法提取sift特征作为图像的表征结果,相比于深度学习算法提取的丰富的语义信息,sift特征较为单一,无法涵盖图像所有的信息。在基于对人眼识别的方法中,专利申请cn108805085a公开了一种基于人眼识别的智能睡眠检测方法,该方法直接将眼睛状态分为:闭眼和睁眼,并训练两种眼睛状态的神经网络模型,该方法的缺陷在于:当司机的眼睛较小,或者司机眯眼但未闭眼时,会影响模型的识别精度。在基于关键点识别的方法中,专利申请cn108363968a公开了一种基于关键点提取的司机疲劳驾驶监测,该方法通过计算嘴巴或者眼睛的高度差与整个脸部的高度的比值作为嘴巴或者眼睛的张开程度,从而判断司机是否打哈欠或者闭眼,该方法的缺陷在于:当司机的眼睛较小而脸部高度较大时,会导致眼睛的高度差与脸部高度的比值较小,当该比值小于预定的阈值时,会导致错误的判断。
3、综上所述,目前的司机危险驾驶行为检测方法存在以下问题:首先,基于传统的图像处理方法仅利用单幅图像进行判断,无法判断司机的动态,眨眼等动作会造成误报,且该方法提取的sift特征相比于深度学习算法提取的特征缺少更丰富的语义信息;其次,基于对人眼识别的方法会将小眼睛误识别成闭眼状态,影响识别精度;最后,在基于关键点的识别方法,通过眼睛的高度差与脸部的高度的比值表示眼睛的张开程度,但由于人脸的差异化会造成相对比值的波动范围较大,采用同一阈值进行判断会造成很大误差。
技术实现思路
1、本发明的目的就是为了提供一种提高检测准确率的基于深度学习算法的司机危险驾驶行为检测方法。
2、本发明的目的可以通过以下技术方案来实现:
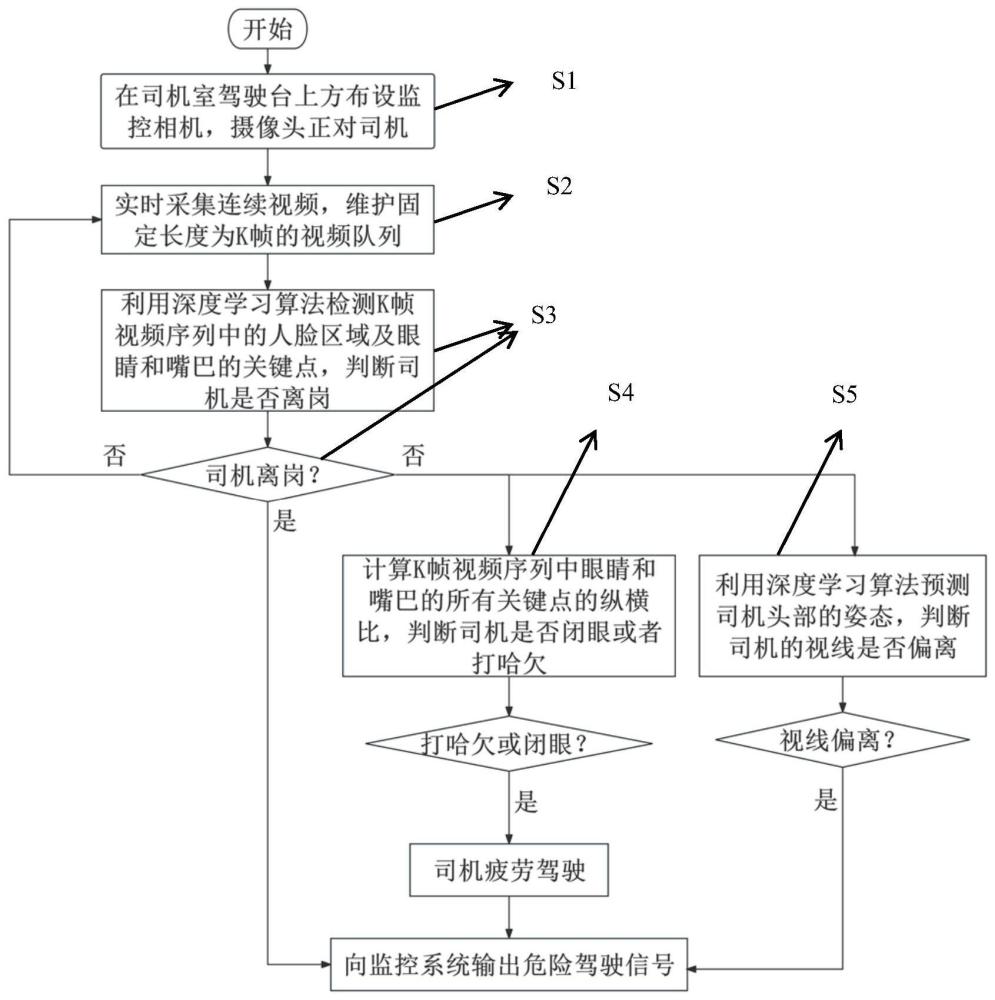
3、一种基于深度学习算法的司机危险驾驶行为检测方法,包括以下步骤:
4、实时采集司机脸部的连续视频帧,并维护固定长度的视频帧队列;
5、采用深度学习算法检测所述视频帧队列中每一帧图像中的人脸区域和关键点,所述关键点包括眼睛和嘴巴部位的关键点;
6、计算视频帧队列中没有检测到人脸区域的帧数,判断司机是否离岗,若是,则判定存在危险驾驶行为,若否,则执行下一步骤;
7、基于检测到人脸区域的视频帧,计算眼睛和嘴巴部位关键点的纵横比以及采用sixdrepnet模型估计司机头部姿态信息,判断司机是否存在闭眼行为或打哈欠行为或视线偏离行为,并进一步判断司机是否存在危险驾驶行为,完成检测过程。
8、进一步地,所述深度学习算法为mtcnn算法。
9、进一步地,所述判断司机是否离岗的步骤包括:
10、计算所述没有检测到人脸区域的帧数与视频帧队列中帧数的比值,记为c1;
11、设定离岗阈值τ,若c1大于等于τ,表示司机离岗,否则表示司机未离岗。
12、进一步地,所述眼睛部位的关键点包括左眼睛部位的关键点和右眼睛部位的关键点,所述左眼睛部位的关键点包括左眼的左眼角角点pl1(lex1,ley1)、左眼的右眼角角点pl2(lex2,ley2)、左眼上轮廓关键点pl3(lex3,ley3)和pl4(lex4,ley4)、左眼下轮廓关键点pl5(lex5,ley5)和pl6(lex6,ley6),所述右眼睛部位的关键点包括右眼的左眼角角点pr1(rex1,rey1)、右眼的右眼角角点pr2(rex2,rey2)、右眼上轮廓关键点pr3(rex3,rey3)和pr4(rex4,rey4)、右眼下轮廓关键点pr5(rex5,rey5)和pr6(rex6,rey6)。
13、进一步地,判断司机是否存在闭眼行为,并进一步判断司机是否存在危险驾驶行为的步骤包括:
14、计算左眼的左眼角角点pl1(lex1,ley1)和左眼的右眼角角点pl2(lex2,ley2)是欧式距离,记为:dhl;
15、计算右眼的左眼角角点pr1(rex1,rey1)和右眼的右眼角角点pr2(rex2,rey2)的欧氏距离,记为:dhr;
16、计算左眼二组轮廓关键点pl3(lex3,ley3)和pl5(lex5,ley5),pl4(lex4,ley4)和pl6(lex6,ley6)的欧式距离,分别记为dv1和dv2,并计算dv1和dv2的均值,记为
17、计算右眼二组轮廓关键点pr3(rex3,rey3)和pr5(rex5,rey5),pr4(rex4,rey4)和pr6(rex6,rey6)的欧式距离,分别记为dv1′和dv2′,并计算dv1′和dv2′的均值,记为
18、计算与dhl的比值,记为:rel;
19、计算与dhr的比值,记为:rer;
20、计算rel和rer的均值,记为:re;
21、设定阈值α,判断re是否小于等于α,若是,则表示当前视频帧图像中司机存在闭眼行为,若否,则表示当前视频帧图像中司机不存在闭眼行为;
22、计算所述频帧队列中司机存在闭眼行为的视频帧数,记为t,计算t与视频帧队列中帧数的比值,记为c2;
23、设定阈值τe,判断c2是否大于等于τe,若是,则表示司机存在危险驾驶行为,若否,则表示司机不存在危险驾驶行为。
24、进一步地,所述嘴巴部位的关键点包括嘴角左角点pm1(mlx,mly)、嘴角右角点pm2(mrx,mry)、上嘴唇关键点和下嘴唇关键点,所述上嘴唇关键点和下嘴唇关键点均为3个,用于上嘴唇和下嘴唇的位置,所述上嘴唇关键点为分别为pu1(mux1,muy1)、pu2(mux2,muy2)、pu3(mux3,muy3),所述下嘴唇关键点为分别为pd1(mdx1,mdy1)、pd2(mdx2,mdy2)、pd3(mdx3,mdy3)。
25、进一步地,判断司机是否存在打哈欠行为,并进一步判断司机是否存在危险驾驶行为的步骤包括:
26、计算嘴角左角点pm1(mlx,mly)和嘴角右角点pm2(mrx,mry)的欧氏距离,记为dmh;
27、分别计算三组嘴唇关键点pu1(mux1,muy1)和pd1(mdx1,mdy1),pu2(mux2,muy2)和pd2(mdx2,mdy2),pu3(mux3,muy3)和pd3(mdx3,mdy3)的欧式距离,并求三组欧式距离的均值,记为:dml;
28、计算dml和dmh的比值,记为:rm;
29、设定阈值β,判断rm是否大于等于β,若是,则表示当前视频帧图像中司机存在打哈欠行为,若否,则表示当前视频帧图像中司机不存在打哈欠行为;
30、计算所述视频帧队列中司机存在打哈欠行为的视频帧数,记为v,计算v与视频帧队列中帧数的比值,记为c3;
31、设定阈值τm,判断c3是否大于等于τm,若是,则表示司机存在危险驾驶行为,若否,则表示司机不存在危险驾驶行为。
32、进一步地,所述司机头部姿态信息包括俯仰角、偏航角和滚转角,分别对应司机抬头、摇头和转头的头部动作。
33、进一步地,所述判断司机是否存在视线偏离行为,并进一步判断司机是否存在危险驾驶行为的步骤包括:
34、分别设定所述俯仰角、偏航角和滚转角的阈值τp,τy和τr,判断俯仰角是否大于等于τp,或偏航角是否大于等于τy,或滚转角是否大于等于τr,若是,则表示当前视频帧图像中司机存在视线偏离行为,若否,则表示当前视频帧图像中司机不存在视线偏离行为;
35、计算所述视频帧队列中司机存在视线偏离行为的视频帧数,记为s,计算s与视频帧队列中帧数的比值,记为c4;
36、设定阈值τh,判断c4是否大于等于τh,若是,则表示司机存在危险驾驶行为,若否,则表示司机不存在危险驾驶行为。
37、进一步地,还包括:根据检测出的危险驾驶行为,输出危险驾驶信号。
38、与现有技术相比,本发明具有以下有益效果:
39、(1)本发明通过维护视频帧队列,把一段视频帧中的所有图像信息作为整体进行判断,充分考虑了危险驾驶行为的连续性和关联性,提高了检测的准确性。
40、(2)相比于传统图像处理方法中提取sift特征,本发明采用深度学习算法mtcnn提取的眼睛部分和嘴巴部分的关键点特征更具代表性。
41、(3)本发明通过计算眼睛和嘴巴关键点的纵横比,判断眼睛和嘴巴的闭合状态,不会因为人脸的差异化造成相对比值的波动范围较大,会减少误报。
42、(4)本发明通过检测司机疲劳驾驶,司机视线偏离以及司机离岗三个维度进行司机危险驾驶行为的判断,检测结果更具有说服力。
本文地址:https://www.jishuxx.com/zhuanli/20240905/287893.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表