基于特征值监测的水电机组模拟量缓变预测方法与流程
- 国知局
- 2024-09-05 14:51:47
本发明涉及水电机组监测,特别涉及基于特征值监测的水电机组模拟量缓变预测方法。
背景技术:
1、随着水电机组技术的不断发展和应用,对其运行稳定性和安全性的要求也日益提高。水电机组在运行过程中,其模拟量的缓变趋势往往能反映出机组运行状态的潜在问题。因此,准确预测和监测这些模拟量的缓变情况对于及时发现和解决问题、保证水电机组的安全稳定运行具有重要意义。
2、目前,针对水电机组模拟量的缓变预测,已有一些传统的预测方法,如基于统计学的预测模型、基于物理模型的预测方法等。然而,这些方法在实际应用中存在一些缺点。如:基于统计学的预测模型通常需要对大量的历史数据进行统计分析,且对数据的完整性和准确性要求较高,一旦数据出现缺失或异常,模型的预测性能将受到严重影响;基于物理模型的预测方法虽然能够较为准确地反映机组的物理过程,但模型的建立和维护较为复杂,且对于复杂多变的实际运行环境适应性较差。
3、另外,现有技术往往采用单一参数作为模拟量进行缓变预测,然而水电机组的运行状态是一个综合的体现,单一的参数(如温度或频率)虽然能够反映机组的某一方面状态,但可能无法全面揭示机组的整体运行情况。
技术实现思路
1、本发明的目的在于结合水轮机的核心部件温度和水轮机振动频率,基于随机森林模型和回归函数找到一种基于特征值监测的水电机组模拟量缓变预测方法。
2、为了实现本发明的上述目的,本发明采用以下技术方案:
3、基于特征值监测的水电机组模拟量缓变预测方法,该方法包括以下步骤:
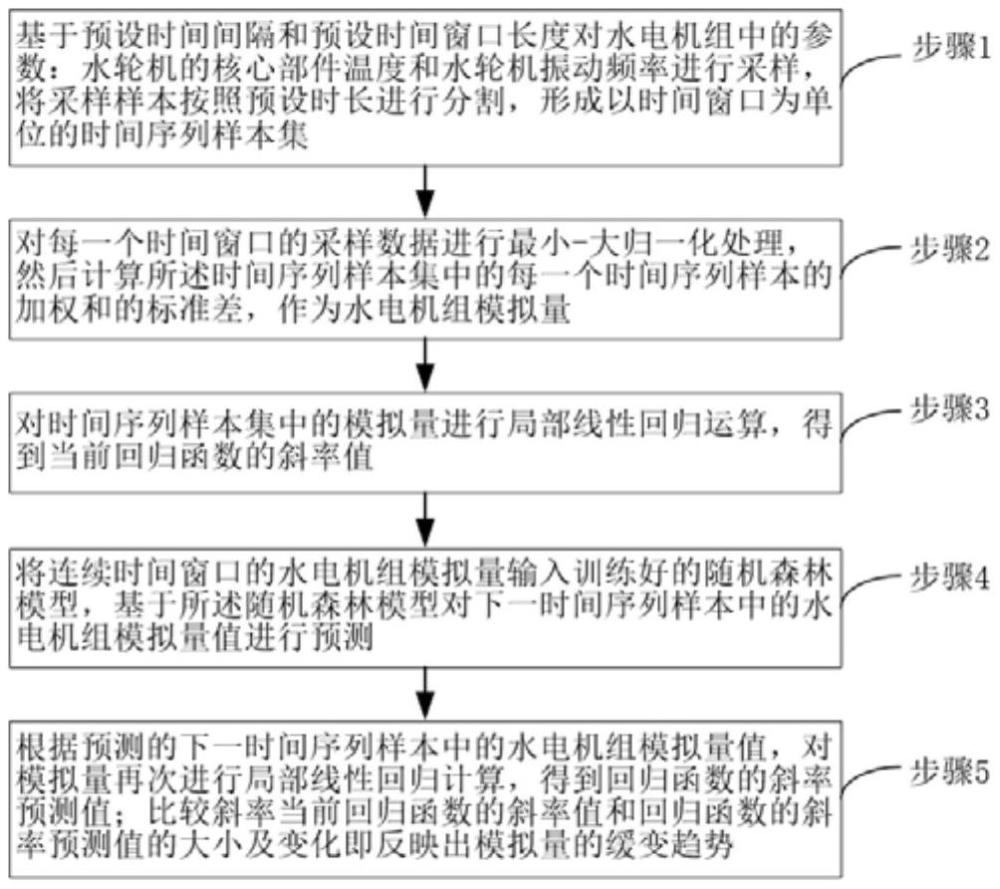
4、步骤1,基于预设时间间隔和预设时间窗口长度对水电机组中的参数:水轮机的核心部件温度和水轮机振动频率进行采样,将采样样本按照预设时长进行分割,形成以时间窗口为单位的时间序列样本集。
5、进一步的,所述预设时间间隔t为2~5s,一个时间窗口内连续采样q次,则预设时间窗口长度l=qt,其中,4≤q≤12;将采样样本按照预设时长进行分割是指,预设时长m=kl,其中k表示时间窗口的数量,15≤k≤20。
6、时间序列样本集表示为u={a1,a2,…,ai,…,an},其中,ai表示第i个时间序列样本,n表示时间序列样本的个数,每一个时间序列样本均由k个时间窗口的采样数据组成,第i个时间序列样本ai表示为ai={ai1,ai2,……,aik},aik表示第第i个时间序列样本中的k个时间窗口的采样数据。
7、步骤2,对每一个时间窗口的采样数据进行最小-最大归一化处理,然后计算所述时间序列样本集中的每一个时间序列样本的加权和的标准差,作为水电机组模拟量。
8、进一步的,加权和s的计算式:s=wt·t+wf·f,其中,t是归一化后单个时间窗口的温度值,f是归一化后单个时间窗口的振动频率值,wt和wf分别是温度值和振动频率值的权重,wt+wf=1。
9、则对于时间序列样本a中,有k个时间窗口的归一化数据,表示为:(t1,f1),(t2,f2),…,(tk,fk),时间窗口数据的加权和表示为:s1,s2,…,sk。
10、时间序列样本的加权和的标准差:其中,是加权和的平均值,si是时间序列样本中的i个时间窗口数据的加权和。
11、则对于时间序列样本a,其时间序列样本的加权和的标准差:
12、
13、其中,ti和fi分别表示的i个时间归一化后的温度值和振动频率值。
14、步骤3,对时间序列样本集中的模拟量进行局部线性回归运算,得到当前回归函数的斜率值。
15、步骤4,将连续时间窗口的水电机组模拟量输入训练好的随机森林模型,基于所述随机森林模型对下一时间序列样本中的水电机组模拟量值进行预测。
16、步骤5,根据预测的下一时间序列样本中的水电机组模拟量值,对模拟量再次进行局部线性回归计算,得到回归函数的斜率预测值;比较斜率当前回归函数的斜率值和回归函数的斜率预测值的大小及变化即反映出模拟量的缓变趋势。
17、进一步的,所述最小-最大归一化的计算式为:式中,t为归一化后单个时间窗口的温度值,为时间窗口的温度平均值,max(t)和min(t)分别为时间窗口温度数据的最大值和最小值;f是归一化后单个时间窗口的振动频率值,为时间窗口的振动频率平均值,max(f)和min(f)分别为时间窗口振动频率数据的最大值和最小值。
18、进一步的,步骤3中的局部线性回归运算采用加权最小二乘法,其公式为:β=(xtwx)-1xtwy,其中,β是回归系数向量,x是设计矩阵,w是对角权重矩阵,y是响应变量向量。
19、进一步的,步骤4中,随机森林模型在训练时,采用时间序列样本中的特征数据,所述特征数据包括温度值、振动频率值以及它们的加权和的标准差;
20、在预测时,随机森林模型根据输入的时间序列样本输出预测的模拟量值,其预测公式为:其中,是预测的模拟量值,m是随机森林中树的数量,hj(x)是第j棵树对输入x的预测结果。
21、进一步的,所述比较斜率当前回归函数的斜率值和回归函数的斜率预测值的大小及变化即反映出模拟量的缓变趋势,具体方法是:
22、设置斜率阈值g,所述斜率阈值g=0.08,当所述当前回归函数的斜率值的绝对值或回归函数的斜率预测值的绝对值大于所述斜率阈值g时,触发预警机制,表明水电机组模拟量处于显著缓变状态。
23、设置斜率缓变阈值d,所述缓变阈值d=0.03,将步骤5中得到的回归函数的斜率预测值的绝对值与回归函数的斜率预测值的绝对值的差值,再取绝对值后得到的差值的绝对值与缓变阈值d进行比较,若所述差值的绝对值大于缓变阈值d,触发预警机制,表明水电机组模拟量预计将发生显著缓变。
24、进一步的,根据步骤5中得到的回归函数的斜率预测值,计算斜率预测值的变化率来量化模拟量的缓变速度,所述变化率为相邻时间序列样本中斜率预测值的差分与时间间隔的比值。
25、斜率预测值变化率的计算公式为:其中,r是斜率预测值的变化率,σt+1和σt分别是相邻两个时间序列样本的斜率预测值,δt是两个时间序列样本之间的时间间隔,δt=m=kl。
26、进一步的,步骤4中,随机森林模型的训练过程采用交叉验证的方式进行模型优化;
27、交叉验证的公式表示为:其中,cv是交叉验证的误差,k是交叉验证的折数,msep是第p折验证的均方误差。
28、通过最小化交叉验证的误差值,选择出最优的随机森林模型参数。
29、进一步的,对水电机组中的参数进行采样时,机组有功功率、机组转速和油冷却器水流量应满足以下约束条件:
30、
31、只有当上述约束条件完全满足时,才对所述水电机组中的参数进行采样。
32、进一步的,所述时间序列样本集中的时间序列样本的个数n满足5≤n≤15。
33、本发明与现有技术相比,其有益效果是:
34、本发明通过对水电机组中的关键参数进行实时采样和监测,将多个参数加权形成模拟量,能够基于模拟量的缓变趋势预测机组的稳定性,提前发现故障并采取相应的措施进行处理;本发明采用局部线性回归运算对时间序列样本进行加权和的标准差计算,能够准确反映模拟量的动态变化情况,同时,利用随机森林模型对下一时间序列样本中的模拟量进行预测,提高了预测的准确性;该方法对数据的完整性和准确性要求相对较低,且能够根据不同机组的实际情况进行自适应调整,具有较强的适应性和可推广性。
本文地址:https://www.jishuxx.com/zhuanli/20240905/288545.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表