基于人工智能的建筑能耗预测方法
- 国知局
- 2024-09-05 15:03:02
本发明涉及建筑能耗数据处理,具体是指基于人工智能的建筑能耗预测方法。
背景技术:
1、当前社会随着经济发展和城镇化推进,人们生活水平日益提高,对于城市公共建筑的使用率上升,能耗规模扩大,建筑能源消耗趋势受到了越来越多的关注。对于城市管理者需要知道未来一段时间的建筑能耗数据,以便采取相应措施提高建筑能源效率,实现节能减排的目的。但是一般建筑能耗预测方法存在数据处理和分析的准确性差、效率低下和主观性强的问题;一般建筑能耗预测方法存在内置参数设置不当的问题。
技术实现思路
1、针对上述情况,为克服现有技术的缺陷,本发明提供了基于人工智能的建筑能耗预测方法,针对一般信息整理方法存在数据处理和分析的准确性差、效率低下和主观性强的问题,本方案通过构建特征距离公式带来更加精准的数据度量和分析结果,提高数据处理的效率和准确性,有助于实现更好的数据挖掘、分类、聚类和识别应用,提高聚类质量;针对聚类方法中存在内置参数设置不当,导致聚类结果的不稳定,从而影响聚类结果的质量的问题,本方案采用多项式曲线和数学期望法获取参数,找到稳定的簇变化范围,实现聚类过程自动化。
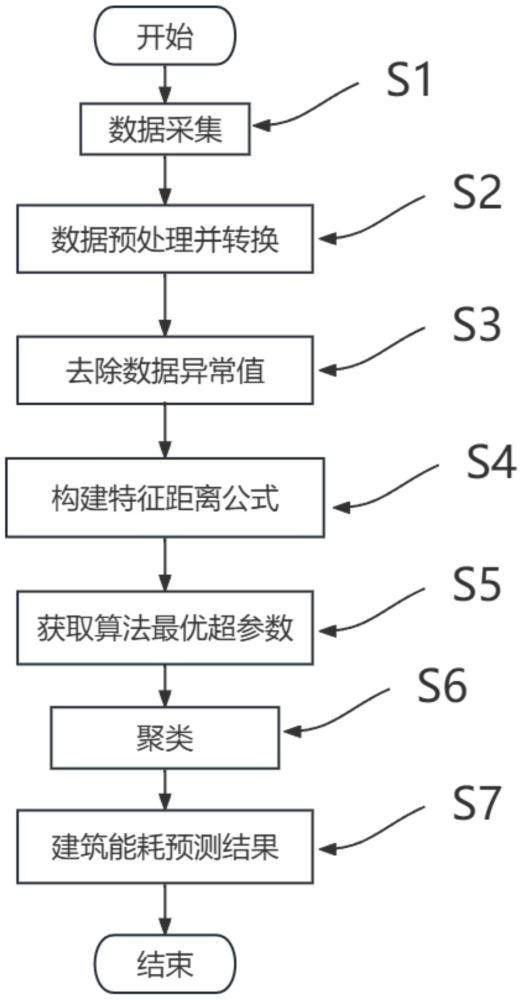
2、本发明采取的技术方案如下:本发明提供的基于人工智能的建筑能耗预测方法,该方法包括以下步骤:
3、步骤s1:数据采集;
4、步骤s2:数据预处理并转换;
5、步骤s3:去除数据异常值;
6、步骤s4:构建特征距离公式;
7、步骤s5:获取算法最优超参数;
8、步骤s6:聚类;
9、步骤s7:建筑能耗预测结果。
10、进一步地,在步骤s1中,所述数据采集是采集历史建筑能耗数据和实时建筑能耗数据;所述历史建筑能耗数据和实时建筑能耗数据都包括建筑物信息数据、建筑设备数据和天气数据;所述建筑物信息数据包括建筑物的地理位置、建筑面积、建筑用途、建筑结构和建筑年代;所述建筑设备数据包括设备类型、设备数量和设备运行时间;所述历史建筑能耗数据还包括建筑能耗等级;将建筑能耗等级作为数据标签。
11、进一步地,在步骤s2中,所述数据预处理并转换,用于对采集到历史建筑能耗数据和实时建筑能耗数据文档进行数据预处理并转换,具体包括以下步骤:
12、步骤s21:对采集的数据进行数据清洗、数据去重和数据统一;
13、步骤s22:将每条数据作为单独文档,每个特征维度作为特征词,将建筑用途作为类别;
14、步骤s23:进行特征选择方法,公式表示如下:
15、;
16、式中,w(·)表示特征词权重结果;ti表示第i个特征词;cj表示第j个类别;tf表示特征词出现在文档中频率;df表示包含特征词的文档频率;n表示文本数据集中文档的总数量;a表示包含特征词ti且所属类别为cj的文档数量;b表示包含特征词且所属类别不为的文档数量;c表示不包含特征词ti且所属类别为cj的文档数量;d表示不包含特征词ti且所属类别不为cj的文档数量;
17、步骤s24:预先设有特征权重阈值,选择特征权重高于特征权重阈值的特征作为最终特征选择结果,并将数据集转换为向量形式。
18、进一步地,在步骤s3中,所述去除异常值具体包括以下步骤:
19、步骤s31:计算四分位数范围,公式表示如下:
20、;
21、式中,iqr表示四分位距,q3表示第三四分位数,q1表示第一四分位数;
22、步骤s32:表确定异常值的阈值,公式表示如下:
23、;
24、;
25、式中,lu表示数据上限阈值,ll表示数据下限阈值;
26、步骤s33:识别并去除异常值,遍历数据集,识别所有小于下限或大于上限阈值的数据点,并将其视为异常值;选择将异常值排除在聚类算法之外。
27、进一步地,在步骤s4中,所述构建特征距离公式,包括以下步骤:
28、步骤s41:计算特征值,公式表示如下:
29、;
30、式中,表示复频率特征值;fi表示特征频率;表示阻尼比;i表示第i个模态点;
31、步骤s42:获取mac值,公式表示如下:
32、;
33、式中,表示向量的共轭转置;mac值表示用于比较模态向量之间的相似性,表示第i个模态点的振动模式形状,表示第j个模态点的振动模式形状;
34、步骤s43获取特征值之间的距离,公式表示如下:
35、;
36、式中,表示两个特征向量之间的距离;表示对应的特征向量;
37、步骤s44:得出特征距离公式,公式表示如下:
38、;
39、式中,distance(·)是计算数据样本点的距离,xi和xj表示数据集中两个不同的样本点。
40、进一步地,在步骤s5中,所述获取算法最优超参数,包括以下步骤:
41、步骤s51:基于特征距离公式得到距离矩阵;其中,m是矩阵行列数;
42、步骤s52:计算k值,包括以下步骤:
43、步骤s521:对矩阵中的每一行元素按照升序排列;排序后,矩阵的第一列元素为零,表示每个对象到自身的距离为零;
44、步骤s522:将排序矩阵的第k个列中的元素按升序排序,作为k-dist曲线上每个点的纵坐标;数据x用作k-dist曲线上每个点的横坐标;k-dist曲线上每个点的含义是横坐标是数据集中点的编号,纵坐标是该点与最近的第k个点之间的距离;据此,生成k-dist曲线;当参数k取不同的值时,生成不同的k-dist曲线,所有k-dist曲线形成k-dist图;
45、步骤s523:使用最小二乘多项式曲线拟合,公式表示如下:
46、;
47、式中,是描述给定数据集的拟合函数,a0、a1、a2和a15表示多项式的系数,x表示函数中的自变量;
48、步骤s524:计算拟合的k-dist平滑曲线稳定上升后突发变化区曲率最大的点,即平滑曲线急剧上升的拐点;公式表示如下:
49、;
50、式中,k是拟合曲线的曲率,是拟合曲线的二阶导数,是拟合曲线的一阶导数;
51、步骤s53:计算deps的值,公式表示如下:
52、;
53、式中,deps表示eps列表所有的数据值,表示与拐点对应的距离值;
54、步骤s54:计算minpts列表,给定的eps值,将deps依次计算相应邻域中的点数;公式表示如下:
55、;
56、式中,minpts表示邻域中至少包含的点个数阈值,eps表示邻域中半径参数值,n代表数据集中总的样本点数目,表示第i个样本点的局部密度估计值。
57、进一步地,在步骤s6中,所述聚类,用于对不包括能耗等级的历史建筑能耗数据和实时建筑能耗数据进行聚类,能耗等级作为数据标签不参与聚类仅用于簇标签选取,具体包括以下步骤:
58、步骤s61:基于eps和minpts列表中的值按照顺序操作dbscan算法;
59、步骤s62:将聚类结果进入收敛阶段对应的eps和minpts值作为最佳值;基于最佳值对历史建筑能耗数据和实时建筑能耗数据进行dbscan聚类操作。
60、进一步地,在步骤s7中,所述建筑能耗预测结果具体内容为聚类后,簇中含有数量最多的历史建筑能耗数据标签作为簇标签,将实时建筑能耗数据所属簇标签作为实时建筑能耗数据的能耗预测结果。
61、采用上述方案本发明取得的有益效果如下:
62、(1)一般信息整理方法存在数据处理和分析的准确性差、效率低下和主观性强的问题,本方案通过构建特征距离公式带来更加精准的数据度量和分析结果,提高数据处理的效率和准确性,有助于实现更好的数据挖掘、分类、聚类和识别应用,提高聚类质量。
63、(2)针对聚类方法中存在内置参数设置不当,导致聚类结果的不稳定,从而影响聚类结果的质量的问题,本方案采用多项式曲线和数学期望法获取参数,找到稳定的簇变化范围,实现聚类过程自动化。
本文地址:https://www.jishuxx.com/zhuanli/20240905/289238.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。