一种面向多平台的定向数据采集方法及系统
- 国知局
- 2024-09-11 14:15:02
本发明涉及舆情数据采集,特别涉及一种面向多平台的定向数据采集方法及系统。
背景技术:
1、舆情数据采集是指通过各种渠道收集、整理和分析社会公众舆论信息,从而获取某个话题、事件或人物在社会上的影响力、关注度和评价等数据。随着社交媒体的兴起,舆情数据采集已经成为了一种重要的社会调研方法,被广泛应用于政府、企业、媒体等领域。
2、社会公众对信息的获取需求不断增加。随着互联网的发展和普及,社会公众获取信息的方式发生了巨大变化,传统的媒体已经不能满足公众对信息获取的需求,而网络媒体平台成为了公众获取信息的主要渠道。通过对舆情数据采集和分析,可以更好地了解社会公众对某个话题或事件的看法和态度。在过去,舆情数据采集主要是依靠人工收集和分析,这种方法费时费力且容易出现主观偏差,而随着计算机技术和人工智能技术的不断发展,自动化的舆情数据采集方法逐渐被开发和应用,大大提高了数据的采集效率和准确度。同时,舆情数据采集也面临着一系列的挑战和问题。例如,网页平台的数据权限和使用规则不断变化,导致数据的可用性和可信度难以保证。另外,如何从大量的数据中提取有价值的信息,如何准确地判断社会公众的情绪和态度,也是当前舆情数据采集研究的重要问题。因此,对于舆情数据采集的研究具有重要意义,通过对舆情数据采集方法、技术和工具的研究,可以不断提高数据采集的效率和准确度,更好地服务于社会调研和舆情分析。同时,对于舆情数据采集的难点和问题进行研究,可以为解决实际问题提供理论和技术支持。
3、通过对舆情数据采集与分析的深入研究,有望为舆情管理、政策制定、社会研究等领域提供更加科学、全面的信息支持。因此,本研究旨在利用先进的爬虫技术,从国内主流新闻网站和社交媒体平台中采集时政热点等舆情数据,以更全面、深入地分析社会动态,为政府决策、舆情管理提供更准确的参考依据,揭示信息网络中的潜在规律,为我们更好地理解社会舆情、应对社会变化提供有力支持。
4、当前数据采集一般是通过编写网络爬虫的方式进行,它通常包含如下几个步骤:确定目标网站、抽取页面url、处理并解析页面、抽取html文档文本、数据处理、数据存储等几个步骤,并且在进行网页数据采集时,需要确保遵循相关法律和网站的使用条款,尊重网站的隐私政策,并确保数据采集不会对网站造成网络攻击。此外,为了保证舆情数据的全面性和多样性,往往需要从多个网页平台采集数据,然而,目前的舆情数据采集存在下面几个亟待解决的问题:
5、首先,在url抽取方面,传统的做法是根据目标网站的不同,通过人工注释的方式对url标签所在的模块打上记号,这种方式耗时长且需要花费大量人力;在爬取多个平台的过程中,传统做法需要针对每个页面都单独编写一套爬虫程序,耗时耗力,且难以处理动态页面;另外,传统的单爬虫采集在面对网页多、数据量大时,采集时间非常慢,且难以协调多个网站之间的采集过程。
技术实现思路
1、本发明的目的是提供一种面向多平台的定向数据采集方法及系统,代替人工注释的方式定位并抽取url,并适用于多个平台,降低编写爬虫的成本,通过自动化爬取解决动态页面和深度爬取存在的问题,在同时爬取多个平台数据时提高效率。
2、为实现上述目的,本发明提供了如下方案:
3、一种面向多平台的定向数据采集方法,包括:
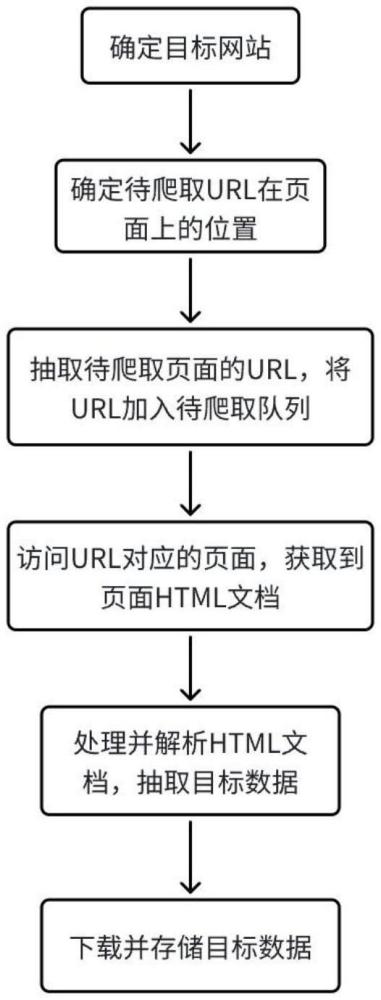
4、确定目标网站;
5、确定所述目标网站中待爬取url在页面上的位置;
6、抽取待爬取页面的url,并将抽取到的url加入待爬取队列;
7、访问url所对应的页面,并获取页面的html文档;
8、对所述html文档进行处理和解析,得到目标数据。
9、可选的,所述面向多平台的定向数据采集方法还包括:
10、对所述目标数据进行预处理。
11、可选的,确定所述目标网站中待爬取url在页面上的位置具体包括以下步骤:
12、获取页面中所有的<a>标签;所述<a>标签表示点击可跳转的标签;
13、对所述<a>标签进行预处理;
14、计算预处理后的所有<a>标签之间,两两的属性相似度;
15、计算所有<a>标签之间,两两的文本特征相似度;
16、基于所述属性相似度和文本特征相似度计算<a>标签两两之间的相似度;
17、基于所述<a>标签两两之间的相似度确定相似度矩阵;
18、对所述标签相似度矩阵进行聚类,得到若干个<a>标签的集合,记为cluster;
19、从所述若干个<a>标签的集合中获取目标标签所在的cluster;
20、基于目标标签所在的cluster抽取url。
21、可选的,计算预处理后的所有<a>标签之间,两两的属性相似度具体采用以下公式:
22、
23、其中,x,y分别代表两个标签的n维相似度向量,||x||,||y||分别表示表示x,y的l2范数,xi表示向量x第i个维度上的值,yi表示向量y第i个维度上的值。
24、计算所有<a>标签之间,两两的文本特征相似度具体采用以下公式:
25、
26、其中,x表示,y表示,len(xtext)表示,len(ytext)表示,dep(xtext)表示,dep(ytext)表示。
27、可选的,基于所述属性相似度和文本特征相似度计算<a>标签两两之间的相似度具体采用以下公式:
28、similarity(x,y)=α×similaritytfidf(x,y)+β×similaritytext(x,y)
29、其中,similarity(x,y)表示标签x,y的标签总体相似度,similaritytfidf(x,y)表示标签x,y的标签属性相似度,similaritytext(x,y)表示标签x,y的文本特征相似度,α表示similaritytfidf(x,y)的权重系数,取0.4,β表示similaritytext(x,y)的权重系数,取0.6。
30、可选的,抽取待爬取页面的url,并将抽取到的url加入待爬取队列具体包括以下步骤:
31、webdriver:载入配置模板,开启chrome webkit内核,启动webdriver引擎,并设置网页的初始url、允许爬取的域名allow_domain、拒绝爬取的域名deny_domain;所述配置模板包括:模板配置模块、采集规则模块、异常处理模块、错误警告模块、url抽取模块、翻页规则模块、详情信息抽取模块以及反爬模块;
32、加载模板规则:载入已经配置好的模板,所述配置好的模板包括除反爬模块外的所有模块;
33、爬取目标网站:启动爬虫,按照所述加载模板规则开始爬取,抽取目标网站上的详情页url,加入url队列;
34、详情页数据抽取:按调度规则从url队列取出url,访问其对应的详情页,抽取详情页数据并保存;
35、翻页:当前页爬取完成,如果还有下一页则按翻页规则模块继续爬取下一页,否则关闭爬虫。
36、结束:爬虫执行停止,日志打印停止,webdriver关闭。
37、可选的,在步骤“webdriver”和步骤“添加伪装信息”之间还包括:
38、添加伪装信息:载入反爬模块。
39、可选的,所述访问url所对应的页面,并获取页面的html文档具体包括以下步骤:
40、配置master节点和slave节点:每个网页分配一个master节点,根据网页预估设置slave节点;
41、redis初始化:根据配置好的master节点,为每个网页分配一个redis消息队列用于存储该网页抽取到的url,保证该master节点对应的所有slave节点共享该url队列;
42、数据爬取:包括webdriver初始化、载入配置模板、url抽取、详情页数据抽取;
43、结束:爬取完成后,保存本次redis日志,清空本次缓存,关闭master节点和slave节点。
44、可选的,对所述html文档进行处理和解析,得到目标数据具体包括以下步骤:
45、html文档解析:获取下载器所返回的response对象,所述response对象包括当前页面的html文件和响应状态码;
46、判断响应码是否为200,如果不是200则代表爬取失败,转入异常处理模块;如果为200则代表爬取成功,从response对象中取出html字符串,基于beautifulsoup解析得到解析后的数据;
47、dom树构建:经过beautifulsoup解析后得到html字符串,去除其中的回车符、换行符、制表符、特殊表情以及特殊字符,通过htmlresponse解析并生成dom树,并根据页面结构采取元素定位方法,配合start_with()、contain()response对象所带的方法,定位到待抽取字段所在的位置;所述元素定位方法包括:id选择器、class选择器以及tag选择器;
48、数据抽取:根据所述待抽取字段所在的位置,基于string()、extract_first()方法,抽取该字段对应的数据;
49、存储和下载:将抽取到的字段存储在items对象中,并交给管道,由管道触发管道方法存储和下载数据。
50、基于本发明中的上述方法,本发明另外提供一种面向多平台的定向数据采集系统,包括:
51、目标网站确定模块,用于确定目标网站;
52、待爬取url在页面上的位置确定模块,用于确定所述目标网站中待爬取url在页面上的位置;
53、待爬取页面的url抽取模块,用于抽取待爬取页面的url,并将抽取到的url加入待爬取队列;
54、页面的html文档获取模块,用于访问url所对应的页面,并获取页面的html文档;
55、处理与解析模块,用于对所述html文档进行处理和解析,得到目标数据。
56、根据本发明提供的具体实施例,本发明公开了以下技术效果:
57、本发明提出了一种基于标签属性和文本特征的url抽取算法,能够代替人工注释的方式定位并抽取url,并适用于多个平台;在爬取多个平台的过程中,本发明提出了基于配置模板的自动化爬取策略,抽离出多个平台url抽取的公共逻辑并封装为模块,极大降低了编写爬虫的成本,并通过自动化爬取解决动态页面和深度爬取存在的问题;在采集效率层面,本发明重写scrapy爬虫框架的核心模块,并加入了分布式调度策略和节点中间件构建了分布式爬取框架,在同时爬取多个平台数据时效率显著提高。
本文地址:https://www.jishuxx.com/zhuanli/20240911/289792.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表