一种多用户干扰躲避方法及装置
- 国知局
- 2024-09-11 14:15:51
本发明涉及强化学习,尤其涉及一种多用户干扰躲避方法及装置。
背景技术:
1、无线通信的开放和共享在给通信用户带来易于访问和接入等便利的同时,也使通信网络暴露于无线环境中且相比于有线网络更易受到干扰攻击。干扰攻击作为无线通信安全的重要威胁,主要通过辐射电磁信号影响和破坏用户的信号接收过程,使通信性能严重下降。尤其在融入人工智能和通信对抗技术后,智能干扰设备具备感知、学习和决策能力,给无线通信抗干扰技术的发展带来了前所未有的挑战。因此,为了保证无线通信的安全性、可靠性和稳定性,需要对复杂电磁环境条件下的智能干扰躲避技术展开研究。
2、干扰躲避主要是通过将待传信号变换到与干扰信号不同维度的信号空间来躲避干扰,包括跳频扩频、跳时扩频、直接序列扩频等。目前常用的多用户干扰躲避技术为强化学习和博弈论。
3、博弈论通常被用来分析多个相互影响的个体间的行为决策及均衡问题。早期,零和博弈和非零和博弈被用来建模用户和干扰之间的对抗关系,双方各自以最大化自身效用为目标,找到均衡解下的对抗策略。进一步,考虑通信方和干扰方之间的分层行为特性,stackelberg博弈被大量工作用来建模两者之间的主从关系,在stackelberg博弈框架下,利用凸优化、强化学习等方法,在干扰环境下优化功率或信道策略,最大化通信方传输效用。虽然博弈论能够从理论层面较好地刻画通信对抗双方的对抗决策关系,并指导设计相关均衡策略的求解算法,但往往假设用户和干扰都知道对方的决策效用模型,过于依赖先验信息或严苛的前提假设,在实际应用中仍然具有很大的局限性
4、于是,随着机器学习技术在无线通信领域的广泛应用,以深度强化学习为代表的方法被广泛应用于干扰躲避领域。在梳状、扫频、规律性阻塞、组合等常规干扰模式下,采用深度强化学习方法学习干扰变化规律,从而优化通信方的频率、功率和波束等策略,达到抗干扰的效果。进一步考虑多用户下的干扰躲避技术,通常使用多智能体强化学习的方法来决策多个用户的干扰躲避方法,其缺陷在于不同智能体之间为弱关联甚至无关联关系,在简单干扰下表现尚可,但难以应对更为复杂的干扰,缺乏适应性和鲁棒性。
5、上述两种现有的多用户干扰躲避技术存在以下不足:
6、(1)基于博弈论的多用户干扰躲避技术过于依赖先验知识,在缺乏关于干扰方先验信息的条件下,难以准确地识别出干扰模式。
7、(2)基于多智能体强化学习的多用户干扰躲避技术在简单环境中表现尚可,但实际应用中,干扰方也是相当智能的,该方法很难保证快速设计出高效的针对性对抗策略,并随着干扰对手的变化进行快速适配与自主优化调整。
技术实现思路
1、本发明所要解决的技术问题在于,提供一种多用户干扰躲避方法及装置,区别于传统强化使用网络输出的最大值作为训练的目标,本发明学习的目标为前几个最大值,以此作为基础实现了多用户的干扰躲避。用以解决现有多用户干扰躲避方法难以适应复杂干扰环境的缺陷。本发明将敌方干扰智能化,仿真了更为复杂规律的扫频干扰,使得本发明更具实际应用价值。
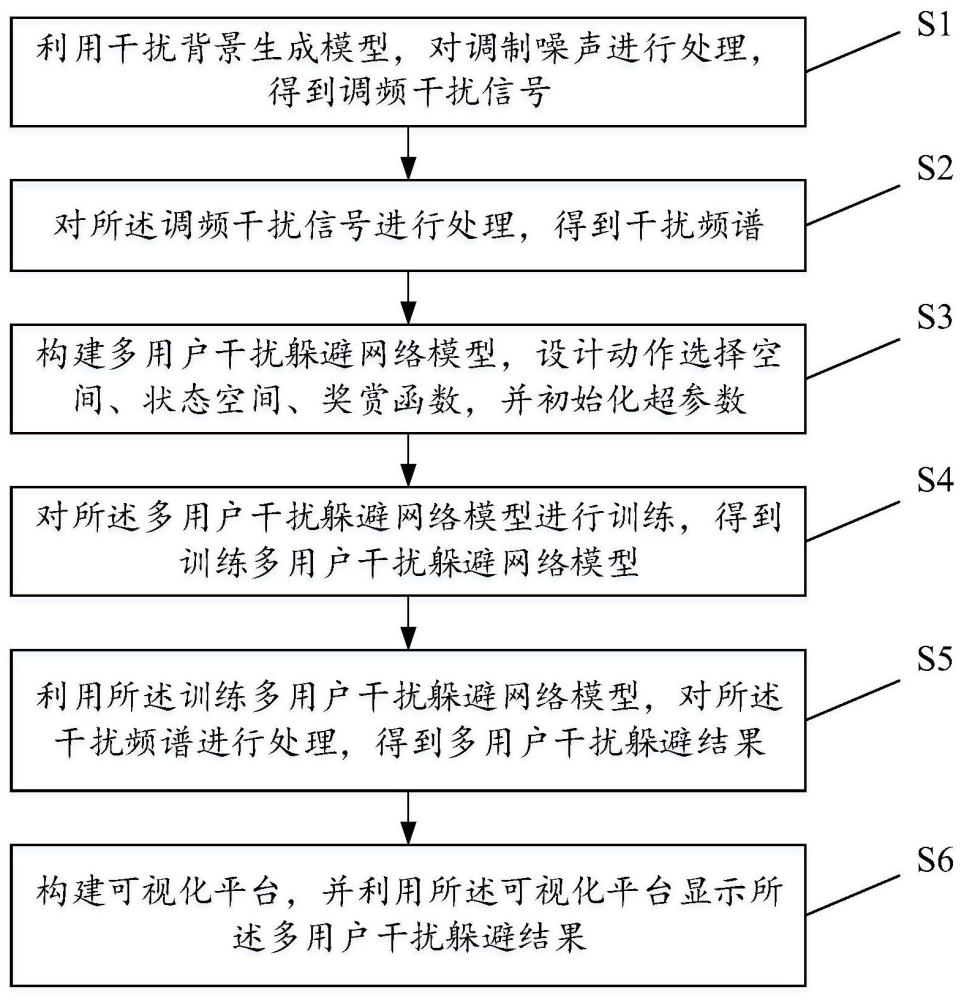
2、为了解决上述技术问题,本发明实施例第一方面公开了一种多用户干扰躲避方法,所述方法包括:
3、s1,利用干扰背景生成模型,对调制噪声进行处理,得到调频干扰信号;
4、s2,对所述调频干扰信号进行处理,得到干扰频谱;
5、s3,构建多用户干扰躲避网络模型,设计动作选择空间、状态空间、奖赏函数,并初始化超参数;
6、s4,对所述多用户干扰躲避网络模型进行训练,得到优化多用户干扰躲避网络模型;
7、s5,利用所述优化多用户干扰躲避网络模型,对所述干扰频谱进行处理,得到多用户干扰躲避结果;
8、s6,构建可视化平台,并利用所述可视化平台显示所述多用户干扰躲避结果。
9、作为一种可选的实施方式,本发明实施例第一方面中,所述干扰背景生成模型为:
10、
11、其中,j(t)为调频干扰信号,ωj为中心角频率,u(t)为调制噪声,其为零均值的广义平稳随机过程,符合正态分布,为初始角,是[0,2π]上的均匀分布且独立的随机变量,uj调频干扰信号幅度,kfm为调频斜率,t和t′为时间变量。
12、作为一种可选的实施方式,本发明实施例第一方面中,所述对所述调频干扰信号进行处理,得到干扰频谱,包括:
13、s21,构建第一扫频干扰信息和第二扫频干扰信息;
14、所述第一扫频干扰信息用转移矩阵表示为[0.4,0.3,0.3],其中矩阵的第一列为向上转移的概率,第二列为不变的概率,第三列为向下转移的概率;
15、所述第二扫频干扰信息用转移矩阵表示为:
16、
17、其中转移矩阵的第一列为向上转移的概率,第二列为不变的概率,第三列为向下转移的概率;
18、s22,对所述第一扫频干扰信息、所述第二扫频干扰信息和所述调频干扰信号进行处理,得到干扰频谱。
19、作为一种可选的实施方式,本发明实施例第一方面中,所述多用户干扰躲避网络模型包括输入层,第一处理层、第二处理层、第三处理层、第四处理层、第五处理层和输出层;
20、所述输入层的输入维度为1×15×10;
21、所述输入层的输出为第一处理层的输入,所述第一处理层的输出维度为32×8×5;
22、所述第一处理层的输出为第二处理层的输入,所述第二处理层的输出维度为64×5×3;
23、所述第二处理层的输出为第三处理层的输入,所述第三处理层的输出维度为64×4×3;
24、所述第三处理层的输出为第四处理层的输入,所述第四处理层的输出维度为1×448;
25、所述第四处理层的输出为第五处理层的输入,所述第五处理层的输出维度为1×512;
26、所述第五处理层的输出为输出层的输入,所述输出层的输出维度为1×10。
27、作为一种可选的实施方式,本发明实施例第一方面中,所述设计动作选择空间、状态空间、奖赏函数,包括:
28、s31,设计动作选择空间,得到动作空间矩阵;
29、s32,设计状态空间,得到状态空间时频图;
30、s33,设计奖赏函数,得到奖赏函数矩阵;
31、所述奖赏函数矩阵为:
32、
33、其中r1(s)为奖赏函数值。
34、作为一种可选的实施方式,本发明实施例第一方面中,所述对所述多用户干扰躲避网络模型进行训练,得到优化多用户干扰躲避网络模型,包括:
35、s41,随机初始干扰位置,得到当前干扰状态频谱;
36、s42,利用多用户干扰躲避网络模型,对所述当前干扰状态频谱进行处理,得到行为矩阵;
37、s43,步进到下一个频谱分配时间段并获得下一个干扰状态频谱,执行所述行为矩阵,得到奖赏值;
38、s44,所述当前干扰状态频谱、行为矩阵、下一个干扰状态频谱和奖赏值构成转变过程;
39、s45,将所述转变过程存入重播缓冲区;
40、s46,从所述重播缓冲区中取出批量大小的转变过程;
41、s47,利用所述批量大小的转变过程,对所述多用户干扰躲避网络模型进行训练,得到优化多用户干扰躲避网络模型。
42、作为一种可选的实施方式,本发明实施例第一方面中,所述利用所述批量大小的转变过程,对所述多用户干扰躲避网络模型进行训练,得到优化多用户干扰躲避网络模型,包括:
43、s471,对所述批量大小的转变过程进行处理,得到近似目标值;
44、所述近似目标值为:
45、
46、其中,yt为t时刻近似目标值,rt为t时刻奖赏值,γ为折扣因子,max_n为算子,max_n的含义为寻找出最大的n个值,n为用户数量,为基于t+1时刻的行为矩阵at+1寻找出最大的n个值,st+1为t+1时刻的干扰状态频谱,q(st+1,at+1;θ-)为价值函数,θ-为t+1时刻多用户干扰躲避网络模型参数;
47、s472,将最大的n个近似目标值的和作为所述多用户干扰躲避网络模型的目标值;
48、s473,构建所述多用户干扰躲避网络模型的预测值;
49、所述预测值bt为:
50、
51、其中,为基于t时刻的行为矩阵at寻找出最大的n个值,q(st,at;θ)为价值函数,st为t时刻的干扰状态频谱,at+1为t时刻的行为矩阵,θ为t时刻多用户干扰躲避网络模型参数;
52、s474,利用损失函数执行梯度下降,对所述目标值和预测值进行处理,得到训练多用户干扰躲避网络模型。
53、本发明实施例第二方面公开了一种多用户干扰躲避装置,所述装置包括:
54、信号生成模块,用于利用干扰背景生成模型,对调制噪声进行处理,得到调频干扰信号;
55、干扰频谱生成模块,用于对所述调频干扰信号进行处理,得到干扰频谱;
56、网络模型构建模块,用于构建多用户干扰躲避网络模型,设计动作选择空间、状态空间、奖赏函数,并初始化超参数;
57、训练模块,用于对所述多用户干扰躲避网络模型进行训练,得到训练多用户干扰躲避网络模型;
58、干扰躲避模块,用于利用所述训练多用户干扰躲避网络模型,对所述干扰频谱进行处理,得到多用户干扰躲避结果;
59、可视化模块,用于构建可视化平台,并利用所述可视化平台显示所述多用户干扰躲避结果。
60、作为一种可选的实施方式,本发明实施例第二方面中,所述干扰背景生成模型为:
61、
62、其中,j(t)为调频干扰信号,ωj为中心角频率,u(t)为调制噪声,其为零均值的广义平稳随机过程,符合正态分布,为初始角,是[0,2π]上的均匀分布且独立的随机变量,uj调频干扰信号幅度,kfm为调频斜率,t和t′为时间变量。
63、作为一种可选的实施方式,本发明实施例第二方面中,所述对所述调频干扰信号进行处理,得到干扰频谱,包括:
64、s21,构建第一扫频干扰信息和第二扫频干扰信息;
65、所述第一扫频干扰信息用转移矩阵表示为[0.4,0.3,0.3],其中矩阵的第一列为向上转移的概率,第二列为不变的概率,第三列为向下转移的概率;
66、所述第二扫频干扰信息用转移矩阵表示为:
67、
68、其中转移矩阵的第一列为向上转移的概率,第二列为不变的概率,第三列为向下转移的概率;
69、s22,对所述第一扫频干扰信息、所述第二扫频干扰信息和所述调频干扰信号进行处理,得到干扰频谱。
70、作为一种可选的实施方式,本发明实施例第二方面中,所述多用户干扰躲避网络模型包括输入层,第一处理层、第二处理层、第三处理层、第四处理层、第五处理层和输出层;
71、所述输入层的输入维度为1×15×10;
72、所述输入层的输出为第一处理层的输入,所述第一处理层的输出维度为32×8×5;
73、所述第一处理层的输出为第二处理层的输入,所述第二处理层的输出维度为64×5×3;
74、所述第二处理层的输出为第三处理层的输入,所述第三处理层的输出维度为64×4×3;
75、所述第三处理层的输出为第四处理层的输入,所述第四处理层的输出维度为1×448;
76、所述第四处理层的输出为第五处理层的输入,所述第五处理层的输出维度为1×512;
77、所述第五处理层的输出为输出层的输入,所述输出层的输出维度为1×10。
78、作为一种可选的实施方式,本发明实施例第二方面中,所述设计动作选择空间、状态空间、奖赏函数,包括:
79、s31,设计动作选择空间,得到动作空间矩阵;
80、s32,设计状态空间,得到状态空间时频图;
81、s33,设计奖赏函数,得到奖赏函数矩阵;
82、所述奖赏函数矩阵为:
83、
84、其中r1(s)为奖赏函数值。
85、作为一种可选的实施方式,本发明实施例第二方面中,所述对所述多用户干扰躲避网络模型进行训练,得到优化多用户干扰躲避网络模型,包括:
86、s41,随机初始干扰位置,得到当前干扰状态频谱;
87、s42,利用多用户干扰躲避网络模型,对所述当前干扰状态频谱进行处理,得到行为矩阵;
88、s43,步进到下一个频谱分配时间段并获得下一个干扰状态频谱,执行所述行为矩阵,得到奖赏值;
89、s44,所述当前干扰状态频谱、行为矩阵、下一个干扰状态频谱和奖赏值构成转变过程;
90、s45,将所述转变过程存入重播缓冲区;
91、s46,从所述重播缓冲区中取出批量大小的转变过程;
92、s47,利用所述批量大小的转变过程,对所述多用户干扰躲避网络模型进行训练,得到优化多用户干扰躲避网络模型。
93、作为一种可选的实施方式,本发明实施例第二方面中,所述利用所述批量大小的转变过程,对所述多用户干扰躲避网络模型进行训练,得到优化多用户干扰躲避网络模型,包括:
94、s471,对所述批量大小的转变过程进行处理,得到近似目标值;
95、所述近似目标值为:
96、
97、其中,yt为t时刻近似目标值,rt为t时刻奖赏值,γ为折扣因子,max_n为算子,max_n的含义为寻找出最大的n个值,n为用户数量,为基于t+1时刻的行为矩阵at+1寻找出最大的n个值,st+1为t+1时刻的干扰状态频谱,q(st+1,at+1;θ-)为价值函数,θ-为t+1时刻多用户干扰躲避网络模型参数;
98、s472,将最大的n个近似目标值的和作为所述多用户干扰躲避网络模型的目标值;
99、s473,构建所述多用户干扰躲避网络模型的预测值;
100、所述预测值bt为:
101、
102、其中,为基于t时刻的行为矩阵at寻找出最大的n个值,q(st,at;θ)为价值函数,st为t时刻的干扰状态频谱,at+1为t时刻的行为矩阵,θ为t时刻多用户干扰躲避网络模型参数;
103、s474,利用损失函数执行梯度下降,对所述目标值和预测值进行处理,得到训练多用户干扰躲避网络模型。
104、本发明实施例第三方面公开了另一种多用户干扰躲避装置,所述装置包括:
105、存储有可执行程序代码的存储器;
106、与所述存储器耦合的处理器;
107、所述处理器调用所述存储器中存储的所述可执行程序代码,执行如本发明实施例第一方面所述的多用户干扰躲避方法。
108、本发明实施例第四方面公开了一种计算机可存储介质,所述计算机可存储介质存储有计算机指令,所述计算机指令被调用时,用于执行如本发明实施例第一方面所述的多用户干扰躲避方法。
109、与现有技术相比,本发明实施例具有以下有益效果:
110、(1)目前的多用户干扰躲避方法所针对的单频、多频或扫频干扰都较为简单。其中,单频和多频干扰中的干扰频带固定,扫频干扰也是简单的线性扫频干扰,在这些干扰下所得出干扰躲避效果不具有代表性和实际应用价值。在真实的干扰环境中,干扰方也是智能的,其干扰规律也更为复杂和多变,而本发明所仿真的扫频干扰没有明显规律,以一个或多个转移概率矩阵作为扫频规律,这种规律更为复杂,更能表现目前复杂的干扰环境。
111、(2)针对目前的多用户干扰躲避领域,本发明提出了一种分布预测强化学习方法,并将其应用于多用户干扰躲避领域,这种方法相比于基于多智能体强化学习的多用户干扰躲避方法消耗更少的计算资源,能有效的提升多用户干扰躲避的及时性,同时在复杂干扰环境中,具有更低的频谱冲突率。
本文地址:https://www.jishuxx.com/zhuanli/20240911/289876.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表