基于最大熵强化学习算法的模型训练方法及规划制导方法
- 国知局
- 2024-09-11 14:33:26
本发明涉及计算机,尤其涉及一种基于最大熵强化学习算法的模型训练方法及规划制导方法。
背景技术:
1、末制导算法主要用于拦截体对目标体进行拦截过程的末端,由规划制导方法给出作用在拦截体上的控制量以控制拦截体位置与目标体的位置不断逼近,由此实现对目标体的拦截。赋予拦截体对目标体以期望的角度进行攻击的能力能够增加拦截目标体的成功率。在理想环境下采用深度学习训练出的制导律应用于实际拦截体对目标体进行拦截过程的情况下,拦截体对目标体基本无法实施有效拦截。
技术实现思路
1、本发明旨在至少解决相关技术中存在的技术问题之一。为此,本发明提供一种基于最大熵强化学习算法的模型训练方法及规划制导方法。
2、训练方法,其特征在于,包括:
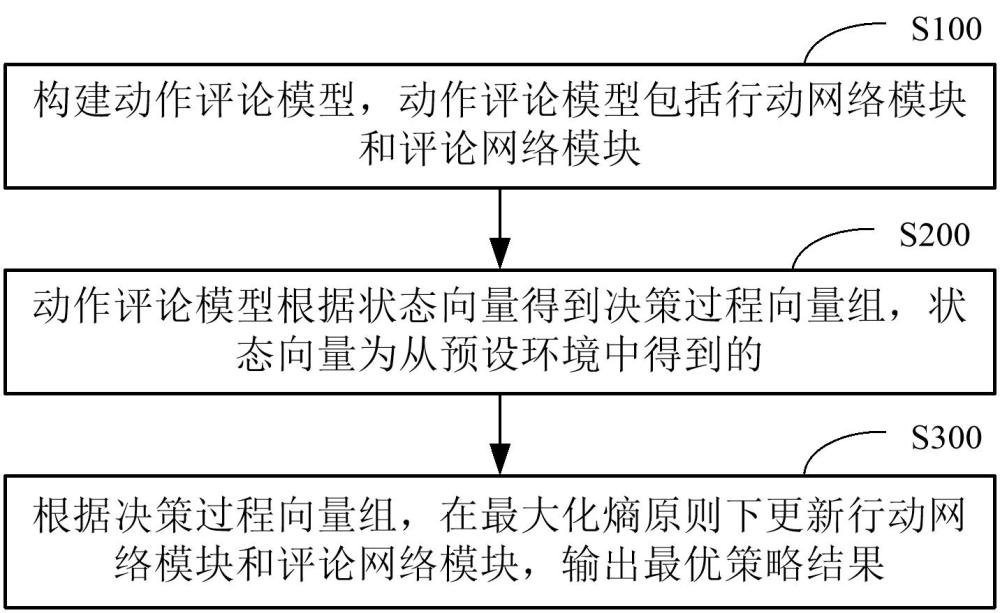
3、s100:构建动作评论模型,上述动作评论模型包括行动网络模块和评论网络模块;
4、s200:上述动作评论模型根据状态向量得到决策过程向量组,上述状态向量为从预设环境中得到的;
5、s300:根据上述决策过程向量组,在最大化熵原则下更新上述行动网络模块和上述评论网络模块,输出最优策略结果。
6、根据本发明的实施例,上述构建动作评论模型包括:
7、构建上述行动网络模块,上述行动网络模块包括行动子网络和行动配置存储子网络,上述行动配置存储子网络用于存储上述行动子网络的参数;
8、构建上述评论网络模块,上述评论网络模块包括第一评论子网络、第二评论子网络和评论配置存储子网络,上述评论配置存储子网络用于存储上述第一评论子网络和上述第二评论子网络的参数。
9、根据本发明的实施例,上述动作评论模型根据状态向量得到决策过程向量组包括:
10、从上述预设环境获得上述状态向量;
11、上述行动子网络根据上述状态向量得到动作向量;
12、上述行动子网络根据上述状态向量和上述动作向量得到奖励向量;
13、根据上述状态向量、上述动作向量和上述奖励向量,得到上述决策过程向量组。
14、根据本发明的实施例,上述根据上述决策过程向量组,在最大化熵原则下更新上述行动网络模块和上述评论网络模块,输出最优策略结果包括:
15、根据上述决策过程向量组更新熵温度系数;
16、根据上述熵温度系数更新上述行动网络模块和上述评论网络模块,输出上述最优策略结果。
17、根据本发明的实施例,上述根据上述决策过程向量组更新熵温度系数包括:
18、上述行动网络模块根据上述决策过程向量组,得到策略迭代过程中的次优策略,其中,i=0,1,2,…,i为策略迭代过程中的迭代次数;
19、上述评论网络模块根据上述次优策略,更新上述熵温度系数。
20、根据本发明的实施例,上述行动网络模块根据上述决策过程向量组,得到策略迭代过程中的次优策略包括:
21、
22、其中,次优策略表示在状态下的求解一个策略动作分布与分布的最小,为auto-sac算法训练智能体过程中每一个仿真步长中由训练环境中获得的状态量,为每一个仿真步长中智能体基于当前的状态动作网络进行决策输出的动作,为kl散度,即分布与的相似度最高,为在最大化熵原则下的状态动作价值函数,为熵温度系数,为在当前状态下所使用的策略。
23、根据本发明的实施例,上述评论网络模块根据上述次优策略,更新上述熵温度系数还包括:
24、更新熵温度系数的损失函数包括:
25、
26、其中,通过随机梯度下降法在所述训练过程中更新熵温度系数,为目标熵,代表在当前状态下通过策略选择动作的概率,表示当前状态下的策略。
27、根据本发明的实施例,上述根据上述熵温度系数更新上述行动网络模块和上述评论网络模块,输出上述最优策略结果包括:
28、计算上述对次优策略进行策略评估并更新上述评论网络模块参数,至上述次优策略收敛到综合累计奖励与最大熵原则的最优策略,其中,最优策略为基于更新后的上述评论网络模块更新的熵温度系数得到的;
29、其中,综合累计奖励包括时间奖励、距离奖励和视线角奖励。
30、根据本发明的另一个方面,提供了一种根据上述的基于最大熵强化学习算法的模型的规划制导方法,包括:
31、s400:获取拦截体初始状态向量和目标体初始状态向量;
32、s500:上述基于最大熵强化学习算法的模型根据上述拦截体初始状态向量和上述目标体初始状态向量,输出最优策略结果。
33、根据本发明的另一个方面,提供了一种规划制导装置,包括:
34、获取模块,用于获取拦截体初始状态向量和目标体初始状态向量;以及
35、输出模块,通过基于最大熵强化学习算法的模型根据上述拦截体初始状态向量和上述目标体初始状态向量,输出最优策略结果。
36、本发明实施例中的上述一个或多个技术方案,至少具有如下技术效果之一:
37、基于最大熵深度强化学习算法提出了一种基于最大熵强化学习算法的模型训练方法。通过对状态向量的获取,可以使构成动作评论模型的深度学习网络更快专注寻找与状态相关的空间信息,进一步的在最大化熵原则下,避免对整体空间进行计算,大大减少了学习的复杂性,加快输出最优策略结果。
38、本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
技术特征:1.一种基于最大熵强化学习算法的模型训练方法,其特征在于,包括:
2.根据权利要求1所述的一种基于最大熵强化学习算法的模型训练方法,其特征在于,所述构建动作评论模型包括:
3.根据权利要求2所述的一种基于最大熵强化学习算法的模型训练方法,其特征在于,所述动作评论模型根据状态向量得到决策过程向量组包括:
4.根据权利要求2所述的一种基于最大熵强化学习算法的模型训练方法,其特征在于,所述根据所述决策过程向量组,在最大化熵原则下更新所述行动网络模块和所述评论网络模块,输出最优策略结果包括:
5.根据权利要求4所述的一种基于最大熵强化学习算法的模型训练方法,其特征在于,所述根据所述决策过程向量组更新熵温度系数包括:
6.根据权利要求5所述的一种基于最大熵强化学习算法的模型训练方法,其特征在于,所述行动网络模块根据所述决策过程向量组,得到策略迭代过程中的次优策略包括:
7.根据权利要求6所述的一种基于最大熵强化学习算法的模型训练方法,其特征在于,所述评论网络模块根据所述次优策略,更新所述熵温度系数还包括:
8.根据权利要求6所述的一种基于最大熵强化学习算法的模型训练方法,其特征在于,所述根据所述熵温度系数更新所述行动网络模块和所述评论网络模块,输出所述最优策略结果包括:
9.一种应用权利要求1~8中任一项所述的基于最大熵强化学习算法的模型的规划制导方法,其特征在于,包括:
技术总结本发明提供一种基于最大熵强化学习算法的模型训练方法及规划制导方法,包括:构建动作评论模型,动作评论模型包括行动网络模块和评论网络模块;动作评论模型根据状态向量得到决策过程向量组,状态向量为从预设环境中得到的;根据决策过程向量组,在最大化熵原则下更新行动网络模块和所述评论网络模块,输出最优策略结果。本发明在最大化熵原则下,避免对整体空间进行计算,大大减少了学习的复杂性。技术研发人员:张晓宇,王晨飞,刘烨坤,董飞受保护的技术使用者:南开大学技术研发日:技术公布日:2024/9/9本文地址:https://www.jishuxx.com/zhuanli/20240911/291387.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。