一种基于二次模糊学习机的标记噪声识别方法及系统
- 国知局
- 2024-09-11 14:53:09
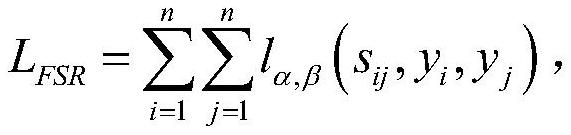
本发明涉及机器学习标记噪声识别,尤其涉及一种基于二次模糊学习机的标记噪声识别方法。
背景技术:
1、监督学习通过从大量的训练样本中学习来构建预测模型,其中每个训练样本都有一个标记标明其真实的输出,然而此类算法的效果严重依赖于训练样本的标记质量,在实际问题中获取具有高质量标记的训练样本通常费时费力。为节省人力物力,网络爬虫、众包方法等替代方法被用于采集训练数据。不幸的是,这些替代方法获取的数据往往存在一定比例的错误标注,即标记噪声,由此带来了很多潜在的问题。
2、分类作为机器学习中最重要的问题之一,也会受到标记噪声的影响。标记噪声给分类任务带来了巨大的挑战,因为传统的分类模型容易受到这些错误标记的干扰导致性能下降。因此识别和处理标记噪声对于构建高效、准确的机器学习模型至关重要。
3、目前为止已有大量识别标记噪声的方法被提出,基于集成学习思想的识别方法是通过多个基分类器的预测结果组合后的正确程度来识别噪声,比如多数投票过滤器(majority vote filter,mvf)、动态集成过滤器和高一致性随机森林过滤器(randomforest,rf),这类方法虽然比单一基过滤器具有很好的精度,但计算成本通常很大。基于近邻模型识别方法通常是借助k近邻(k-nearest neighbor,knn)模型实现,如全近邻过滤器、互近邻(mutual nearest neighbor,mnn)过滤器,这些过滤器都对近邻参数k的选取过于敏感,且这类方法都基于原始特征计算距离度量,无法应对大规模数据集。有人提出了基于相对密度(relative density-based,rd)过滤方法,rd利用样本的相对密度来衡量样本的噪声强度,还提出了基于完全随机森林(complete random forest,crf)的过滤方法,crf通过构建完全随机树来衡量样本被一类样本包围的水平,进而确定样本的噪声强度。为了解决其中的硬阈值问题,通过将随机划分测试集的分类精度作为自适应指标,相继提出了基于自适应投票策略的相对密度过滤器vrd和自适应完全随机森林过滤器adap_mcrf,但这两种方法在噪声比例较高时过滤效果会明显下降且时间复杂度较高。现有噪声过滤方法时间复杂度较高且难以处理当前数据量急剧增长、数据类型复杂的大规模数据集;大多基于原始特征识别标记噪声的方法难以自适应地学习对任务有用的特征,这使其无法有效识别标记噪声,而深度神经网络虽然具有较强的特征提取能力,但由于模型的表达能力较强使其可以拟合任意比例的标记噪声。
技术实现思路
1、为解决现有技术的不足,本发明提出一种基于二次模糊学习机的标记噪声识别方法。通过特征提取网络捕获样本的潜在表示,通过模糊二元关系模块迭代训练模型迭代优化网络参数,利用阈值选择策略区分高置信度样本和低置信度样本,利用高置信度样本继续再次迭代训练模型,利用样例集来预测样本标记,最终来实现噪声样本的识别。
2、本发明的目的是通过下述技术方案实现的:
3、一种基于二次模糊学习机的标记噪声识别方法,包含如下步骤:
4、s1:输入模块,给定带噪声数据集
5、s2:首次学习模块,构建模糊学习机,在训练过程中通过最小化模糊允许损失lfsr迭代更新模型参数,捕捉所有样本的潜在表示h(x);
6、s3:模糊二元关系模块,使用余弦相似度作为模糊二元关系网络的基本骨架,基于获取到的样本特征h(x)进行相似度计算,计算余弦相似度得到样本之间的模糊关系矩阵s;
7、s4:样例集选择模块,对于类别c,将标记为c的所有样本原始特征x输入模糊二元关系模块,得到样本之间的模糊关系矩阵s,按列求和,对所有样本的模糊隶属度进行排序,将top-k得分最高的样本作为该类别样例集ec,由此循环得到所有类别的样例集;
8、s5:标记干净度计算模块,利用样例集e计算样本模糊相似矩阵s,根据样本的类别标记生成独热编码矩阵one-hot-mat及类别对角矩阵d,通过将模糊相似矩阵、独热编码矩阵及类别对角矩阵进行矩阵乘法,并进行归一化处理,即可得到样本对每个类别的隶属度矩阵sam_class_score,从而计算每个样本的标记干净度pclean;
9、s6:二次学习模块,基于所有样本标记干净度pclean,根据设定阈值r划分子集,将标记干净度大于阈值的样本归类为高置信度样本,将低于阈值的样本归类为低置信度样本,选取高置信度样本继续训练模糊学习机,更新模型参数;
10、s7:噪声识别模块,基于二次学习后的模糊学习机得到更新的样例集e',利用e'计算样本对每个类别的隶属度矩阵sam_class_score,隶属度最高的类别索引即为样本预测标记,对比样本原类别标记,两者不一致即认为标记噪声样本。
11、进一步,步骤s1包括:给定标记数据集其中xi表示样本原始表示,yi表示样本xi的真实标记。
12、进一步,步骤s2包括:首次学习模块,基于特征提取模块和模糊二元关系模块构建模糊学习机,在训练过程中通过最小化模糊允许损失lfsr迭代更新模型参数,捕捉所有样本的潜在表示h(x)。对于样本特征xi,通过特征提取模块获取到的特征为h(xi)。
13、利用模糊关系矩阵s构造模糊允许损失lfsr,训练过程中的模糊允许损失为:
14、
15、其中α、β为两个超参数,α∈[0,0.5),β∈(0.5,1],β-a用于控制概念的模糊度。
16、对于一个样本对(xi,yi),(xj,yj),样本对之间的模糊允许损失lα,β(sij,yi,yj)
17、计算公式为
18、
19、随之构建随机梯度下降优化器,以此形成循环进行训练,更新模型参数。
20、进一步,步骤s3包括:模糊二元关系模块,使用余弦相似度作为模糊二元关系网络的基本骨架,基于获取到的样本特征h(x)进行相似度计算,计算余弦相似度得到样本之间的模糊关系矩阵。对于样本xi的特征h(xi)和样本xj的特征h(xj)进行余弦相似度计算,余弦相似度计算公式为:
21、
22、定义一个模糊关系矩阵s∈[0,1]n×n,其中sij为样本xi与xj之间的相似度,其对应计算公式为:
23、
24、进一步,步骤s4包括:样例集选择模块,对于类别c,将标记为c的所有样本原始特征x输入模糊二元关系模块,得到样本之间的模糊关系矩阵s,对模糊关系矩阵s进行按列求和,即可得到样本对于类别的隶属度s_c,对其进行从大到小排序,得到top-k的样本即为类别c的样例集ec,由此循环,得到所有类别的样例集。
25、进一步,步骤s5包括:标记干净度计算模块,利用样例集e计算样本模糊相似矩阵s,利用样本类别标记生成独热编码矩阵one-hot-mat,其中每一行标记为1的位置对应于样本标记,其余位置均为0,再生成一个类别对角矩阵d,对角线上的元素均为每个类别样例集的数目的倒数即将所得三个矩阵相乘并归一化处理得到矩阵sam_class_score,即样本对每个类别的隶属度得分,
26、sam_class_score=s*one-hot-mat*d。
27、利用sam_class_score计算每个样本的标记干净度pclean,对于样本(xi,yi)的标记干净度pclean为
28、
29、进一步,步骤s6包括:二次学习模块,基于所有样本标记干净度pclean,根据设定阈值r划分子集,将标记干净度大于阈值的样本归类为高置信度样本,将低于阈值的样本归类为低置信度样本,选取高置信度样本继续训练模糊学习机,更新模型参数。
30、进一步,步骤s7包括:噪声识别模块,利用更新后的样例集e'计算样本对每个类别的隶属度矩阵sam_class_score,隶属度最高的类别索引即为样本预测标记,对比样本原类别标记,两者不一致即认为标记噪声样本。
31、对于样本(xi,yi),其真实标记为yi,其预测标记为
32、
33、若认为样本(xi,yi)为干净样本;若认为样本(xi,yi)为噪声样本。
34、一种基于二次模糊学习机的标记噪声识别系统,包括以下模块:
35、输入模块:输入有标记带噪声数据集;
36、首次学习模块:构建模糊学习机,在训练过程中通过最小化模糊允许损失迭代更新模型参数,捕捉所有样本的潜在表示;
37、模糊二元关系模块:使用余弦相似度作为模糊二元关系网络的基本骨架,基于获取到的样本特征进行相似度计算,计算余弦相似度得到样本之间的模糊关系矩阵;
38、样例集选择模块:对于每一个类别,将类别的所有样本原始特征输入到特征提取模块和模糊二元关系模块,以此得到样本之间的模糊关系矩阵,按列求和,对所有样本的隶属度进行排序,将top-k得分最高的样本作为该类别样例集,由此循环得到所有类别的样例集;
39、标记干净度计算模块:利用样例集计算样本模糊相似矩阵,根据样本的类别标记生成独热编码矩阵及类别对角矩阵,三者进行矩阵乘法,并进行归一化处理,即可得到样本对每个类别的隶属度矩阵,计算每个样本的标记干净度;
40、二次学习模块:基于所有样本标记干净度,根据设定阈值划分子集,将标记干净度大于阈值的样本归类为高置信度样本,将低于阈值的样本归类为低置信度样本,选取高置信度样本继续训练模糊学习机,更新模型参数;
41、噪声识别模块:利用更新后的样例集预测样本所属标记,对比样本原类别标记,两者不一致即认为标记噪声样本。
42、综上所述,发明具有以下有益效果:
43、本发明利用深度神经网络提取对标记噪声识别有用的特征;利用模糊允许损失降低深度神经网络拟合标记噪声的风险;利用二次学习机制完成对标记噪声的初筛和识别,能够有效地提升标记噪声识别性能。
本文地址:https://www.jishuxx.com/zhuanli/20240911/292455.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。