基于知识蒸馏的小样本开集识别方法
- 国知局
- 2024-09-11 14:55:22
本发明实施例涉及机器学习监督学习领域,具体涉及基于知识蒸馏的小样本开集识别方法。
背景技术:
1、小样本学习(few-shot learning,fsl)旨在模拟人类智能从有限样本中学习并推广到新环境的能力,在过去几十年中取得了显著的进展。元学习可以说是fsl中最受欢迎的技术,其核心思想是通过使用基类数据模拟小样本学习情境,从基类数据中抽样多个元任务以训练元分类器。
2、尽管取得了鼓舞人心的进展,现有的fsl方法由于遵循封闭集假设,即训练和测试样本来自相同的特征和标签空间,因此不适用于开集情境。为应对这一挑战,小样本开集识别(few-shot open-set recognition,fsor)被提出,并在近年来受到越来越多的关注。
3、目前,许多fsor方法被提出,这些方法主要是将fsl的元学习机制应用于开集情境,其中每个元任务不仅从基类中抽取一些已知类作为已知类,还从剩余基类中抽取等量的类作为伪未知类。虽然这些方法取得了令人满意的结果,但本研究指出了它们的两个潜在弱点:
4、首先是类标识重叠问题。随机抽取的同一批类别在一个元任务中作为已知类被推开,可能在另一个元任务中被当作伪未知类被拉拢,这不可避免地导致不同元任务之间的冲突,最终扰乱元分类器的学习。
5、其次是伪未知类利用效率低下问题。每个元任务目前只抽取有限的基类类别作为伪未知类,而不是利用所有可用的基类,从而导致元分类器获得的可用监督信息不足,最终削弱其性能。
6、实际上,这些问题的根本原因在于,当将fsl的元学习机制扩展到开集情境时,这些方法的元分类器未能获得对所有可用基类的全局或完整视角。然而,有效利用所有可用基类并非易事。例如,试图通过在水平方向上抽取更多伪未知类来缓解第二个问题,可能会导致已知类和伪未知类之间的类不平衡,从而损害模型的性能。以huang等人提出的att-g方法为例,随着抽取的伪未知类数量增加,类不平衡问题变得越来越严重,特别是在auroc指标上,性能显著下降。
7、有鉴于此,特提出本发明。
技术实现思路
1、发明目的:鉴于上述问题,本发明的目的是针对现有技术不足之出提出改进。为了突破元分类器这种有限视角的局限性,就像人类“登高才能望远”一样,它需要借助具有更宽视角的强大分类器,即在不违反现有fsor假设的情况下“登高望远”。这促使我们开发了一种垂直增强机制(vertical enhancement mechanism,vem),允许具有更宽视角的高水平分类器直接指导元分类器,同时保持原始的元训练机制,使元分类器能够间接看到更多的伪未知类而不必担心类不平衡,同时缓解类标识重叠问题。该机制的关键在于利用知识蒸馏从更高的角度垂直增强元分类器,分别从类间关系和伪未知类知识的方面进行具体实施。具体而言,我们将每个元任务与一个强大的教师分类器关联,该教师分类器通过使用从所有可用基类中抽取的足够的已知类和伪未知类样本进行训练。然后,这些教师分类器利用知识蒸馏分别从类间关系和伪未知类知识的角度垂直增强元分类器。基于这种增强机制,元分类器可以看到更多的伪未知类,同时保持稳定的类间关系。此方法起名为vem(vertical enhancement mechanism)。
2、技术方案:为了实现上述目的,提供了以下技术方案:
3、vem方法,至少包括:
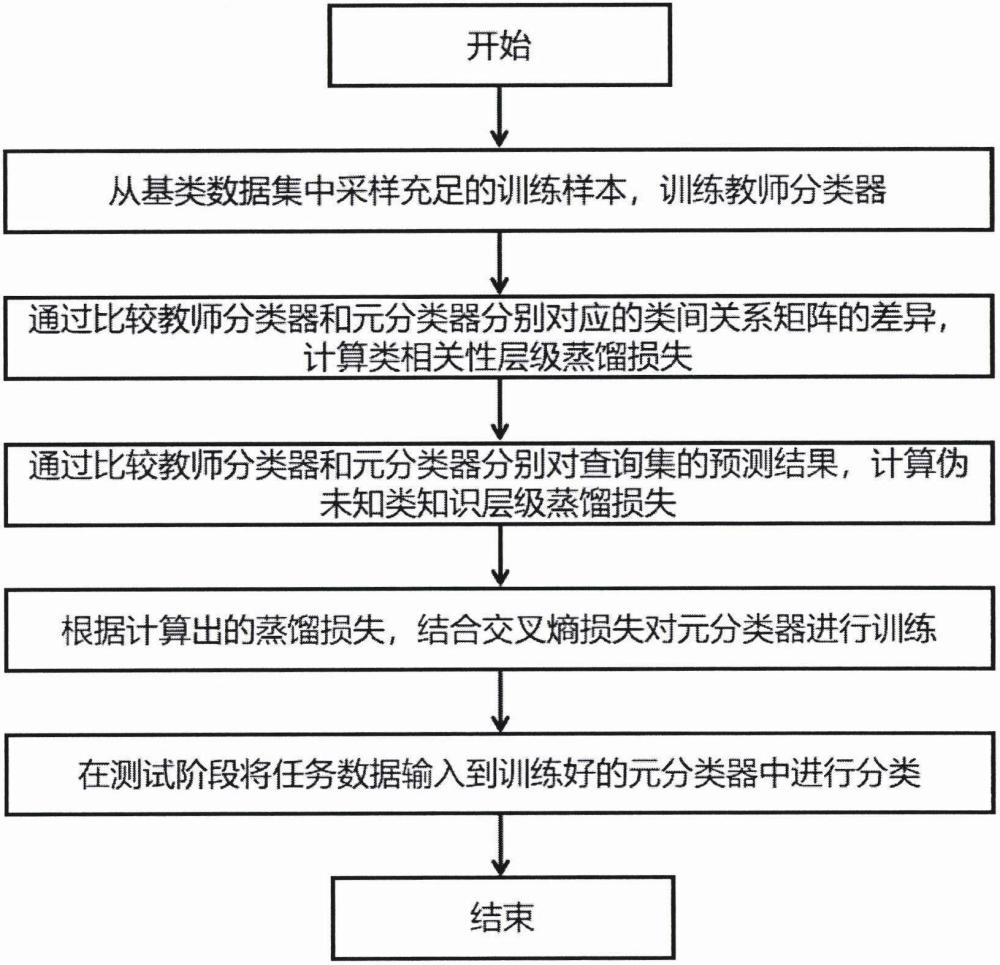
4、步骤s1:在每个元训练任务中,从基类数据集采样充足的训练样本,训练教师分类器;
5、步骤s2:通过比较教师分类器和元分类器分别对应的类间关系矩阵的差异,计算类相关性层级蒸馏损失;
6、步骤s3:通过比较教师分类器和元分类器分别对查询集的预测结果,计算伪未知类知识层级蒸馏损失;
7、步骤s4:根据计算出的蒸馏损失,结合交叉熵损失对元分类器进行训练;
8、步骤s5:在测试阶段将任务数据输入到训练好的元分类器中进行分类。
9、有益效果:与现有技术相比,本发明技术方案至少具有以下有益效果:
10、1)首次发现和分析了现有小样本开集识别方法的两个潜在弱点,为后续该问题的建模提供了新的见解;
11、2)提出了一种简单有效且与现有方法正交的垂直增强机制,使元分类器能够在不受类别不平衡的影响情况下学习到更多的类别信息,同时缓解类别标识重叠的问题;
12、3)在大量基准数据集上的实验证明了vem的有效性,尤其能够显著提升模型的开集识别性能auroc。
技术特征:1.基于知识蒸馏的小样本开集识别方法,其特征在于,所述方法至少包括:
2.根据权利要求1所述的基于知识蒸馏的小样本开集识别方法,其特征在于,步骤s1所述的元训练任务为从基类数据中随机采样的n-way k-shot分类任务,可以形式化为h={ds,dq}。表示支撑集,其中n表示总类别数,k表示每个类的训练样本(支撑样本)数。表示查询集,其中m表示查询集样本总数量。查询集dq中不光包含已知类查询集也包括未知类查询集其中q和u分别表示每个类别查询样本数量和未知类类别总数,且有对应当前元训练任务,训练n个教师分类器。教师分类器tj对应的训练样本集合可以形式化为其中m和l分别表示每个已知类别和每个未知类别采样的训练样本数。教师分类器相比元分类器能够见到额外类别的伪未知类样本,且不同的教师分类器所见到的额外的伪未知类类别不同,即
3.根据权利要求1所述的基于知识蒸馏的小样本开集识别方法,其特征在于,步骤2所述的通过比较教师分类器和元分类器分别对应的类间关系矩阵计算类相关性层级蒸馏损失,具体包括:
4.根据权利要求1所述的基于知识蒸馏的小样本开集识别方法,其特征在于,步骤s3所述的通过比较教师分类器和元分类器分别对查询集的预测结果计算伪未知类知识层级蒸馏损失,具体包括:
5.根据权利要求1所述的基于知识蒸馏的小样本开集识别方法,其特征在于,步骤s4所述的训练元分类器,具体包括:
6.根据权利要求1所述的基于知识蒸馏的小样本开集识别方法,其特征在于,步骤s5所述的测试阶段中,将测试任务的支撑集输入元分类器的特征提取网络获得分类原型,将查询集输入元分类器的特征提取网络获得特征嵌入,通过比较分类原型与查询样本特征嵌入间的余弦相似度进行分类。
技术总结本发明针对现有小样本开集识别方法存在的类标识重叠和伪未知类利用效率低下问题,提出一种基于知识蒸馏的小样本开集识别方法。该方法包括以下步骤:首先,在每个元训练任务中,从基类数据集中采样充足的训练样本,训练教师分类器;其次,通过比较教师分类器和元分类器分别对应的类间关系矩阵的差异,计算类相关性层级蒸馏损失;然后,通过比较教师分类器和元分类器分别对查询集的预测结果,计算伪未知类知识层级蒸馏损失;随后,根据计算出的蒸馏损失,结合交叉熵损失对元分类器进行训练;最后,在测试阶段将任务数据输入到训练好的元分类器中进行分类。技术研发人员:丁相舒,耿传兴受保护的技术使用者:南京航空航天大学技术研发日:技术公布日:2024/9/9本文地址:https://www.jishuxx.com/zhuanli/20240911/292580.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。