一种模型计算分析可视化自动布局方法及系统与流程
- 国知局
- 2024-09-11 15:08:28
本发明涉及图形可视化,具体为一种模型计算分析可视化自动布局方法及系统。
背景技术:
1、随着大数据技术和计算能力的迅速发展,数据可视化已经成为数据分析和挖掘过程中不可或缺的一环。通过将数据以图形化的方式呈现,数据可视化不仅提高了数据分析的效率,还增强了数据理解的直观性和便捷性。在数据可视化的领域中,自动布局技术尤为重要。自动布局技术旨在根据数据的结构和关系自动生成最优的图形布局,以便于用户更直观、更高效地理解和分析数据。这一技术被广泛应用于网络图、流程图、层次图等多种图形结构的生成和优化。然而,随着数据规模和复杂度的增加,传统的自动布局技术在处理海量和复杂数据时面临诸多挑战。
2、目前,自动布局技术的发展主要集中在几种经典的布局算法上,如树型布局、层次布局、网格布局等。这些算法各具优势,广泛应用于不同类型的数据可视化场景。例如,树型布局适用于具有层次结构的数据展示,环形布局常用于循环或周期性结构的数据展示,力导向布局则广泛用于社交网络分析和生物网络分析。然而,现有的自动布局技术在面对动态数据、实时数据更新以及多种数据源的集成时,往往表现出一定的局限性。具体而言,现有技术在以下几个方面存在不足:首先,数据加载和预处理阶段缺乏灵活性和智能化,难以高效地处理多种数据源并进行实时更新。其次,重复数据节点和冗余边的识别与处理机制不够完善,容易导致图形布局的冗杂和信息冗余。此外,现有的布局算法在处理复杂网络结构时,往往无法保证布局的最优化和美观性,导致用户在数据理解和分析时受到影响。
技术实现思路
1、鉴于上述存在的问题,提出了本发明。
2、因此,本发明解决的技术问题是:如何在面对多源数据和动态数据更新的情况下,提供智能的自动布局方法,确保数据可视化过程中展示的高效性和美观性。
3、为解决上述技术问题,本发明提供如下技术方案:一种模型计算分析可视化自动布局方法,其包括如下步骤,
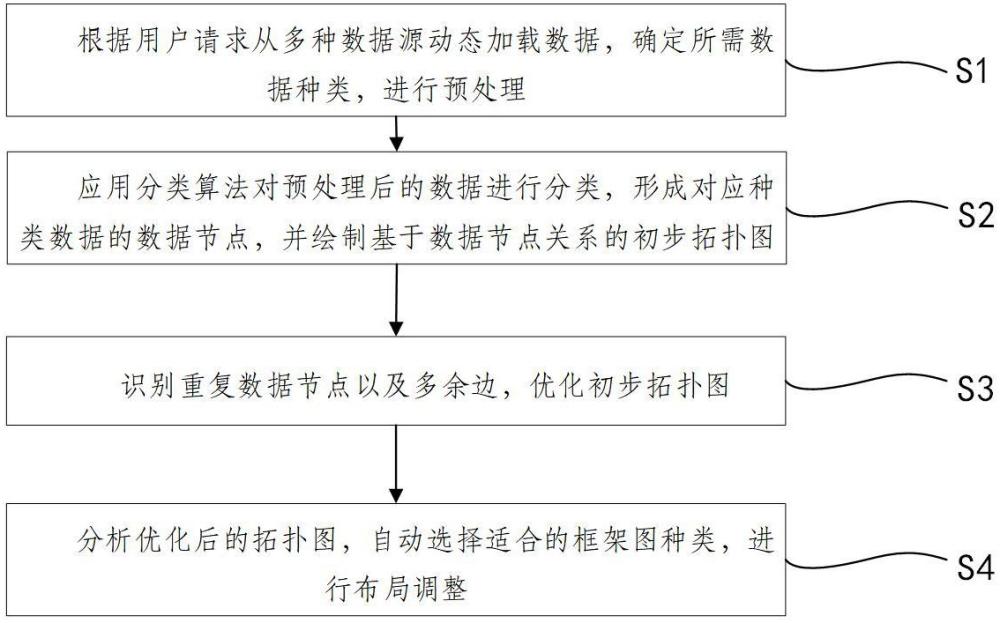
4、根据用户请求从多种数据源动态加载数据,确定所需数据种类,进行预处理;
5、应用分类算法对预处理后的数据进行分类,形成对应种类数据的数据节点,并绘制基于数据节点关系的初步拓扑图;
6、识别重复数据节点以及多余边,优化初步拓扑图;
7、分析优化后的拓扑图,自动选择适合的框架图种类,进行布局调整;
8、所述动态加载数据是根据用户的具体请求,通过自然语言处理技术解析用户请求,确定数据的大类种类、格式以及数据来源的优先级,在数据加载阶段,利用智能选择算法根据数据源的实时响应以及数据质量评估,动态选择合适的数据源进行数据抓取,数据经过网络传输后进入预处理,去除重复以及无关数据,修正数据输入的错误,格式化所有数据,并进行数据验证以确保数据的完整性和逻辑一致性;
9、所述智能选择算法是基于每个数据源提供的性能指标进行实时评估,通过预设的标准,计算每个数据源的综合评分,根据得到的评分,动态决定数据抓取任务分配给评分最高的数据源。
10、作为本发明所述的一种模型计算分析可视化自动布局方法的一种优选方案,其中:所述对预处理后的数据进行分类是从预处理后的数据中提取关键特征,根据特征将数据分为多个具体需求种类,每个具体需求种类代表一个研究方向,将每个具体需求种类的数据创建对应的数据节点,并为每个数据节点分配唯一标识符并记录其种类属性,根据数据节点间预定义的关系规则,使用图形算法自动绘制初步的拓扑图;
11、拓扑图的表达式为:
12、,
13、其中,为数据集,包括所有经预处理和分类后的数据点,为边集,根据特定的关系规则建立;
14、若每一对数据节点 ,根据预定义的规则存在关系,则在 和 之间添加一条边 ;
15、边集的表达式为:
16、。
17、作为本发明所述的一种模型计算分析可视化自动布局方法的一种优选方案,其中:所述识别重复数据节点以及多余边包括识别和处理重复数据节点;
18、通过数据节点属性识别潜在的重复数据节点,综合评估每个重复数据节点的连接边数量和在图中的角色,根据介数中心性、度中心性以及特征向量中心性判断当前重复数据节点是否进行保留,对于需要合并的数据节点,选择代表数据节点,更新相关边,并删除冗余数据节点,对于需要保留的数据节点,保持连接关系和独特属性;
19、所述介数中心性、度中心性以及特征向量中心性,表达式为:
20、,
21、,
22、,
23、其中,为数据节点的介数中心性, 是数据节点 和 之间所有最短路径的数量, 是通过数据节点 的最短路径的数量,为数据节点的度中心性, 是数据节点 的度,连接到 的边数,为数据节点的特征向量中心性,为特征值常数,为数据节点的邻居数据节点集合,表示数据节点和之间是否有边,为邻居数据节点的特征向量中心性;
24、使用介数中心性、度中心性和特征向量中心性评估数据节点的重要性,设定第一综合阈值,若介数中心性、度中心性和特征向量中心性中任一指标大于第一综合阈值,则判断当前数据节点在途中具有关键作用,保留当前重复数据节点,反之删除当前重复数据节点。
25、作为本发明所述的一种模型计算分析可视化自动布局方法的一种优选方案,其中:所述识别重复数据节点以及多余边还包括识别多余边;
26、使用 dijkstra 算法计算所有数据节点对之间的最短路径,识别关键路径,若某条路径中所有边的出现频率均大于设定的第二综合阈值,则判断该路径为关键路径,对于关键路径上的边,保留当前边;对于非关键路径上的边,进一步判断是否为多余边,
27、通过计算冗余度,若某边的冗余度高于设定的第一冗余阈值,则删除该多余边,表达式为:
28、,
29、其中, 为边 的冗余度, 为所有路径的集合, 为指示函数,若边 在路径 中出现,则 ,否则, ;
30、通过删除重复数据节点以及重复边,输出优化后的拓扑图。
31、作为本发明所述的一种模型计算分析可视化自动布局方法的一种优选方案,其中:所述分析优化后的拓扑图,自动选择适合的框架图种类是根据数据节点属性和关系动态计算图中的数据节点位置和边;
32、所述框架图种类包括树形布局、层次布局、网格布局;
33、若初步拓扑图是无闭环连通图,没有孤立的子图或独立的数据节点,n个数据节点对应n−1条边,针对任意两个数据节点之间仅有一条连接边,初步拓扑图的高中心度数据节点比例小于第一高中心度阈值且初步拓扑图的聚类系数小于第一聚类阈值,则分类为树型布局;
34、所述高中心度数据节点比例小于第一高中心度阈值包括计算每个数据节点的度、初步拓扑图的平均度、平均度的标准差,表达式为:
35、,
36、,
37、,
38、其中,为数据节点的度,为初步拓扑图的平均度,为平均度的标准差;
39、统计度初步拓扑图中高于的数据节点数量,表达式为:
40、,
41、,
42、其中,为指数函数,当条件成立时,值为1,否则为0,为高中心度数据节点比例;
43、当小于第一高中心度阈值,则进一步判断初步拓扑图的聚类系数是否小于第一聚类阈值,表达式为:
44、,
45、,
46、其中,为数据节点的聚类系数,为数据节点的邻居数据节点之间实际存在的边数,是数据节点的邻居数据节点数,为初步拓扑图的平均聚类系数;
47、若初步拓扑图是无向无闭环图或有向无闭环图,根数据节点的入度为0,任意两个数据节点之间仅有从上层数据节点指向下层数据节点的边,各层次上的数据节点数均匀分布,各层次数据节点数的方差小于第一方差阈值且没有逆向边和跨层边,则分类为层次布局;
48、所述入度为0是进入当前数据节点的边的数量为0;
49、所述层次是确定初步拓扑图中所有入度为0的根数据节点或源数据节点集合,使用广度优先搜索计算每个数据节点的层次,其中层次是从根数据节点到数据节点的最短路径长度;
50、所述各层次数据节点数的方差小于第一方差阈值,表达式为:
51、,
52、,
53、其中,为各层次数据节点数的方差,为每个层次上的数据节点数, 为最大层次数, 为平均每层的数据节点数;
54、若初步拓扑图中的任意一个数据节点的连接边不大于4且无孤立数据节点,则判定为网格布局;
55、所述第一综合阈值、第二综合阈值、第一冗余阈值、第一高中心度阈值、第一聚类阈值、第一方差阈值是根据用户请求的历史记录进行设定。
56、作为本发明所述的一种模型计算分析可视化自动布局方法的一种优选方案,其中:所述进行布局调整是根据分类结束后的框架图进行防止数据节点重叠、边的优化以及数据节点对齐的调整;
57、所述防止数据节点重叠是检测数据节点位置,计算每对相邻数据节点的距离,若距离小于预设的最小距离,则施加斥力使数据节点分开调整位置,重复检测和调整直到所有数据节点之间的距离都大于或等于最小距离;
58、所述边的优化是使用边交叉检测算法,找出交叉的边,并调整数据节点位置或重新规划边的路径,减少边的交叉点;
59、所述数据节点对齐是确定对齐规则,根据对齐规则计算每个数据节点的目标位置,调整数据节点位置与目标位置对齐;
60、将布局调整后的结果输出并渲染到用户界面上,使用canvas 技术进行渲染,完成可视化自动布局。
61、本发明的另外一个目的是提供一种模型计算分析可视化自动布局系统,其能通过智能选择算法动态加载数据、综合使用介数中心性、度中心性和特征向量中心性识别和处理重复数据节点、计算冗余度优化边的连接以及根据不同数据结构选择最优布局,从而解决现有自动布局技术在灵活性、信息冗余和布局美观性方面的问题。
62、为解决上述技术问题,本发明提供如下技术方案:一种模型计算分析可视化自动布局系统,包括:包括数据加载模块、数据预处理模块、优化模块、布局分类模块以及可视化渲染模块;
63、所述数据加载模块是根据用户请求从多种数据源动态加载数据,解析用户请求,确定数据种类、格式以及数据来源的优先级,基于每个数据源提供的性能指标进行实时评估,动态选择合适的数据源进行数据抓取;
64、所述数据预处理模块是对加载的数据进行去重、修正、格式化和验证,从预处理后的数据中提取关键特征,根据特征将数据分为多个种类,创建对应的数据节点,根据数据节点间预定义的关系规则使用图形算法自动绘制初步的拓扑图;
65、所述优化模块是通过数据节点属性识别潜在的重复数据节点,综合评估每个重复数据节点的连接边数量,使用介数中心性、度中心性和特征向量中心性判断当前重复数据节点是否进行保留,通过计算冗余度,识别并删除多余边,通过重新布置数据节点位置或重新连接边来减少或消除交叉边;
66、所述布局分类模块是分析优化后的拓扑图,自动选择适合的框架图种类,根据数据节点属性和关系动态计算图中的数据节点位置和边,按照分类规则进行布局调整;
67、所述可视化渲染模块是检测数据节点位置,计算每对相邻数据节点的距离,若距离小于预设的最小距离,则施加斥力使数据节点分开调整位置,使用边交叉检测算法,找出交叉的边,并调整数据节点位置或重新规划边的路径,减少边的交叉点,确定对齐规则,根据对齐规则计算每个数据节点的目标位置,调整数据节点位置与目标位置对齐,将最终布局结果输出并渲染到用户界面上,使用canvas技术进行渲染,完成可视化自动布局。
68、一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现如上所述一种模型计算分析可视化自动布局方法的步骤。
69、一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如上所述一种模型计算分析可视化自动布局方法的步骤。
70、本发明的有益效果:本发明通过智能选择算法动态加载数据,确保数据源的高效选择和实时更新,解决了现有技术中数据加载和预处理阶段灵活性和智能化不足的问题。综合使用介数中心性、度中心性和特征向量中心性对重复数据节点进行识别和处理,有效减少了图形布局的冗杂性,避免了信息冗余。通过计算冗余度优化边的连接,大大提高了图形布局的简洁性和美观性,确保了图形的清晰和易读性。提出的布局分类和优化方法能够根据不同数据结构选择最优的布局算法,保证了图形布局的高效性和直观性。通过防止数据节点重叠、优化交叉边和数据节点对齐等步骤,进一步优化了图形布局的展示效果,使得最终的可视化结果更加整洁和规范。本发明不仅解决了现有自动布局技术在灵活性、信息冗余和布局美观性方面的不足,还为用户提供了一个高效、智能的自动布局方法,显著提升了大数据分析和展示的效率和用户体验。
本文地址:https://www.jishuxx.com/zhuanli/20240911/293351.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表