基于深度强化学习的个性化学习推荐系统及方法与流程
- 国知局
- 2024-09-14 14:30:34
本发明涉及学习个性化推荐系统领域,更具体地说,涉及基于深度强化学习的个性化学习推荐系统及方法。
背景技术:
1、随着在线教育的蓬勃发展,个性化学习推荐已成为智能教育领域的研究热点。个性化学习推荐旨在根据学生的兴趣、知识水平、学习风格等因素,从海量的学习资源中筛选出最适合的学习内容,以提高学习效率和满意度。然而,现有的个性化学习推荐技术仍存在诸多不足,难以满足实际应用的需求。
2、当前,个性化学习推荐主要采用协同过滤、基于内容、知识图谱等方法。协同过滤通过挖掘用户或物品之间的相似性,给用户推荐喜好相似用户历史上感兴趣的物品。但该方法易受数据稀疏和冷启动问题的影响,且忽略了学习资源的内容特征。基于内容的推荐根据学习资源的内容属性计算其与用户兴趣的匹配度,但过度依赖专家标注,泛化能力不足。知识图谱引入领域知识对学习资源进行语义化表示,但很少考虑用户的认知状态,推荐的针对性欠佳。
3、上述方法普遍存在三个问题:一是用户兴趣建模不充分,难以刻画用户兴趣的动态演化;二是推荐生成的粗粒度,缺乏对用户认知水平的精准把握;三是离线训练为主,无法快速响应在线数据的变化。此外,大多数推荐系统采用流水线式的松耦合架构,各组件之间缺乏有效的信息交互和协同优化。
4、具体而言,现有的一些融合多视图表示学习的用户兴趣建模算法,如conet,虽然在一定程度上缓解了数据稀疏问题,但其中使用的协同过滤思想仍是将不同视图的用户行为简单拼接,没有考虑不同行为模态之间的潜在联系,语义融合的程度有限。而半监督学习虽可通过标签传播扩大已标注样本的作用,但对于新类别的学习资源和新行为的用户,标签传播的效果往往不尽如人意。
5、目前主流的top-n推荐算法,如bpr(bayesian personalized ranking),往往只能给出物品的排序,却无法估计具体的匹配度得分,缺乏可解释性。而fm(factorizationmachine)通过特征组合,虽可学习到一定程度的交叉特征,但是级数有限,特征表达的丰富程度不足。近年来兴起的深度学习推荐算法,如ncf(neural collaborative filtering),pnn(product-based neural network)等,利用深度神经网络自动提取高阶交互特征,提升了模型的非线性表达能力,取得了不错的效果,但仍是监督学习范式,缺乏对推荐的长期效果优化。
6、个性化学习推荐是一个强交互场景,用户与推荐系统之间持续互动。但现有的推荐系统大多是静态的,主要通过离线阶段一次性生成推荐列表,无法动态调整推荐策略。一些在线学习的尝试,如在线梯度下降,虽可利用流数据实现模型的增量更新,但未考虑用户交互行为对环境的影响,不够智能。多臂赌博机(multi-armed bandit)算法虽然引入了探索-利用机制平衡新旧物品的推荐,但未深入考虑复杂的用户状态表示,且无法对推荐过程进行长期规划。
7、综上,个性化学习推荐亟需一套创新的理论和方法,深度挖掘多源异构数据,精准建模用户兴趣和认知状态,并能够持续学习进化,主动适应环境变化,以期最大限度地挖掘海量学习资源的价值,提升学生的学习体验。本发明正是在此背景下提出,以期突破现有技术的瓶颈,开创个性化学习推荐的新局面。
技术实现思路
1、本发明的目标就是针对上述技术问题,提出基于深度强化学习的个性化学习推荐系统及方法,通过融合优化校验矩阵、对比学习、双重dqn等创新技术,构建了一个全面、精准、灵活的个性化学习推荐系统。该系统能够深入挖掘用户多维度的学习兴趣和认知状态,结合知识图谱对学习资源进行语义化组织,通过层次化表示学习和双重价值估计,动态生成与用户实时需求高度匹配的推荐内容。同时,系统采用增量更新策略,通过参数局部调整和样本重传,实现了知识的快速吸收和冷启动问题的缓解;反馈数据不仅用于改进后续的推荐决策,还为新用户和新物品的冷启动问题提供了有效的支持。
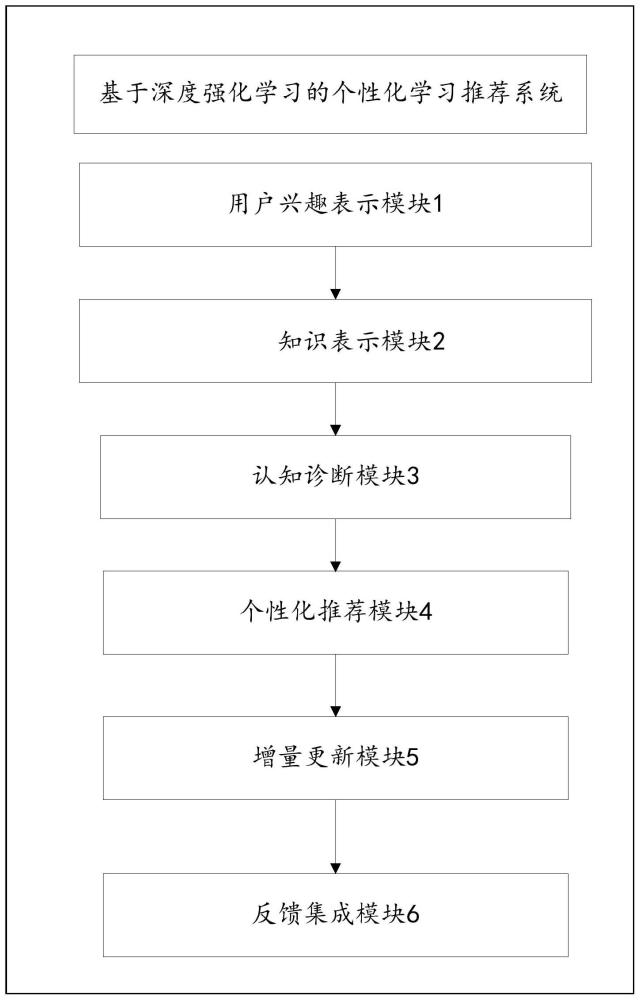
2、本发明提供基于深度强化学习的个性化学习推荐系统,包括:用户兴趣表示模块、知识表示模块、认知诊断模块、个性化推荐模块、增量更新模块和反馈集成模块;
3、所述用户兴趣表示模块,用于采用优化校验矩阵算法从用户的显式反馈和隐式行为中提取多维度兴趣特征,融合生用户兴趣表示向量;
4、所述知识表示模块,用于利用知识图谱对学习资源进行语义化、结构化表示,构建包含概念、属性、关系的多粒度知识网络,形成反映资源内在联系的知识嵌入向量;
5、所述认知诊断模块,用于通过自适应测评收集学生答题数据,使用能力图模型精准推断学生对知识点的掌握状态,输出动态更新的知识掌握向量;
6、所述个性化推荐模块,用于将所述兴趣表示向量、所述知识嵌入向量和所述知识掌握向量多源异构信息输入端到端的深度强化学习网络,通过融合对比学习的奖赏函数、层次化的环境状态表示和双重dqn价值估计,生成兼顾实时匹配度和长期收益的个性化学习资源推荐列表;
7、所述增量更新模块,用于当新用户或新学习资源出现时,从相似用户中迁移模型参数,并利用新数据微调模型,通过参数局部调整和loss重传加速增量学习过程;
8、所述反馈集成模块,用于收集用户对推荐内容的显式反馈、隐式反馈和外部反馈,统计分析综合满意度,并将反馈特征应用于优化后续推荐策略。
9、具体地,所述优化校验矩阵算法包括以下步骤:
10、步骤1.构建初始校验矩阵m,矩阵元素mij表示第i个显式特征与第j个隐式特征的相关性,初始值设为0;
11、步骤2.对于每个用户u,提取其显式特征向量eu和隐式特征向量iu;
12、步骤3.计算显式特征向量eu与隐式特征向量iu的外积ru,其中
13、步骤4.累加所有用户的外积矩阵,得到全局校验矩阵g,其中g=∑ru;
14、步骤5.对全局校验矩阵g进行奇异值分解,g=uσvt,其中u和v为正交矩阵,σ为对角矩阵;
15、步骤6.根据奇异值σi的大小,选择前k个最大奇异值对应的左右奇异向量ui和vi,构建秩为k的优化校验矩阵m*,其中
16、步骤7.利用优化校验矩阵m*对原始的显式特征eu和隐式特征iu进行变换,得到用户u的最终兴趣表示向量pu,其中pu=m*·[eu;u],[eu;u]表示eu和iu的列向量拼接。
17、具体地,所述对比学习的奖赏函数的定义为:
18、
19、其中,rt为t时刻的奖赏值,ct为t时刻推荐的内容,pt为用户兴趣表示向量,ni为负样本池中的第i个样本,sim(·,·)为余弦相似度函数。
20、具体地,所述层次化的环境状态表示定义为:st=concat(eu,ec,ef,ek)
21、其中,eu、ec、ef和ek分别表示通过嵌入函数embed(·)和注意力聚合函数attention(·)生成的用户嵌入向量、内容嵌入向量、反馈信息嵌入向量和知识嵌入向量,concat(.)为向量拼接操作。
22、具体地,所述双重dqn包括:
23、主q网络,用于估计状态-动作对的长期累积奖赏,其损失函数为lq=e[(rt+γ·maxaq(st+1,a)-q(st,at))2];
24、辅助q′网络,用于估计状态-动作对的即时奖赏,其损失函数为l′q=e[(rt-q′(st,at))2];
25、最终损失为l=lq+λ·l′q,其中λ为平衡因子。
26、具体地,所述参数局部调整和loss重传包括:
27、步骤1.当新用户unew到来时,初始化其兴趣表示向量和知识掌握向量
28、步骤2.从历史用户中选取与unew最相似的k个用户,作为支撑用户集su;
29、步骤3.对于每个支撑用户ui∈su,提取其对应的模型参数θi;
30、步骤4.计算unew与每个支撑用户ui的相似度权重wi,
31、步骤5.根据相似度权重,对支撑用户的模型参数进行加权平均,得到unew的初始参数θnew,即θnew=∑wi·θi;
32、步骤6.利用少量新用户交互数据,对θnew进行微调,损失函数为
33、步骤7.在微调过程中,通过loss重传机制,选择性地对相关历史样本的loss进行重新计算和反向传播。
34、具体地,所述反馈集成模块包括:
35、显式反馈收集单元,用于收集用户对推荐内容的点赞、评论、评分主动反馈行为;
36、隐式反馈收集单元,用于收集用户对推荐内容的浏览时间、完成度、点击率被动反馈行为;
37、外部反馈收集单元,用于收集用户的主动搜索、提问外部反馈行为;
38、反馈分析单元,用于统计分析用户反馈,计算综合满意度得分,形成反馈特征;
39、策略改进单元,用于将反馈特征应用于改进后续推荐策略和知识表示。
40、具体地,所述知识表示模块包括:
41、知识图谱构建单元,用于利用自然语言处理技术从学习资源中提取关键概念实体、属性和关系,构建学科领域本体和知识图谱;
42、知识嵌入表示学习单元,用于学习知识图谱中实体和关系的低维稠密向量表示,形成知识嵌入向量。
43、具体地,所述认知诊断模块包括:
44、自适应测评单元,用于从题库中选取题目,对学生进行测试,收集作答结果数据;
45、能力图模型构建单元,用于基于认知诊断理论构建学生能力图模型,包括知识点层、认知层和观测层;
46、知识掌握推断单元,用于根据作答结果和能力图模型,采用贝叶斯知识追踪算法,推断学生对各知识点的掌握情况,形成知识掌握向量。
47、基于深度强化学习的个性化学习推荐方法,包括以下步骤:
48、步骤1.用户兴趣表示构建:利用优化校验矩阵从多个维度提取用户兴趣特征,得到用户兴趣表示向量;
49、步骤2.知识表示构建:对学习资源进行语义化和结构化表示,构建多粒度、多层次的知识图谱和知识嵌入;
50、步骤3.认知诊断评估:通过自适应测评收集学生作答数据,采用能力图模型推断学生知识掌握状态;
51、步骤4.个性化推荐生成:将用户兴趣、知识状态、历史反馈多源信息输入深度强化学习模型,通过对比学习的奖赏函数、层次化的状态表示和双重dqn结构,生成个性化学习资源推荐列表;
52、步骤5.增量更新:当新用户或新学习资源出现时,从相似用户中迁移模型参数,并利用新数据微调模型,通过参数局部调整和loss重传加速增量学习过程;
53、步骤6:反馈集成改进:持续收集用户对推荐内容的显式反馈、隐式反馈和外部反馈,统计分析综合满意度,并将反馈特征应用于优化后续推荐策略。
54、本发明具有如下有益效果:
55、1.本发明通过优化校验矩阵技术,将用户的显式反馈和隐式行为无缝地融合到统一的兴趣表示框架中,克服了数据稀疏和噪声问题,使兴趣表示更加准确和鲁棒。同时,本发明还创新性地引入知识图谱对学习资源进行语义化组织和表示增强,使兴趣表示和知识表示达到了深度融合。二者在表示空间中的高度一致性,使后续的个性化匹配更加精准,远超传统的离散特征匹配方式。
56、2.本发明引入认知诊断机制,通过自适应测评和能力图模型,精准推断学生对不同知识点的掌握程度,使推荐系统能够站在学生的角度,满足学生的近区发展需求。个性化推荐模块与认知诊断模块实现了协同增效:一方面,个性化推荐以诊断结果为重要的情景输入,另一方面,诊断过程本身也在学生使用推荐内容的过程中持续进行。二者的良性互动使学习推荐更具适应性和有效性。
57、3.本发明将个性化推荐问题巧妙地建模为多智能体强化学习问题。每个用户对应一个独立的智能体,通过与学习环境的持续交互优化自己的推荐策略。多个智能体之间通过知识共享机制进行经验交流,加速策略学习的收敛。与传统的单智能体推荐相比,本发明充分利用了群体智慧,使推荐策略更加全局最优。此外,本发明还首次将对比学习思想引入强化学习中,设计了全新的奖赏函数,通过构建困难负样本加强了模型的判别能力,大大提升了样本效率。层次化的状态设计和双重dqn的价值估计也是亮点,使推荐在满足用户实时兴趣的同时兼顾长远收益。
58、4.推荐系统必须快速响应用户实时产生的新数据,工业界大多采用定期重训并全量更新的策略,代价高昂且时效性差。本发明创新地提出增量更新模块,利用参数局部调整和loss重传机制,使模型能够低成本、低延迟地持续学习进化,真正做到了随时刷新。同时,反馈集成模块会即时收集用户对新推荐内容的多种显式和隐式反馈,一方面用于评估模型的增量更新效果,另一方面又作为新的训练数据反哺增量学习,形成了反馈-更新-反馈的闭环。二者完美配合,使模型的表现能始终与用户的意图和偏好实现实时同步。
59、5.个性化、实时性、扩展性、稳定性等多个目标在推荐系统中往往难以兼得,存在此消彼长的矛盾。传统的推荐系统多采用流水线式的设计,不同模块之间割裂严重,只能分别针对各目标进行局部优化,难以权衡。本发明则采用了高度整合的系统架构,多个模块之间实现了端到端的紧密协作和数据流转。若干创新的机器学习技术被灵活地编织在系统的各个部分,发挥各自所长。例如,优化校验矩阵兼顾了表示的稀疏性和准确性,认知诊断实现了性能和延迟的平衡,强化学习则在线上探索与利用之间找到了平衡。各项技术相互补位,系统整体实现了多目标的联合优化,达到了和谐的统一。
60、总之,本发明巧妙地将多个机器学习的前沿技术与推荐系统的业务特点相结合,在方法层面和系统层面都进行了创新性的设计,多项关键技术相互呼应,整体架构与算法实现相得益彰,最终收获了卓越的技术效果,大幅提升了个性化学习推荐的效果和效率。
本文地址:https://www.jishuxx.com/zhuanli/20240914/294457.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。