一种基于全局感知特征融合与样本关系学习的视频描述方法
- 国知局
- 2024-09-14 14:35:42
本发明属于视频描述领域,具体涉及一种基于全局感知特征融合与样本关系学习的视频描述方法。
背景技术:
1、随着互联网的高速发展,短视频已经成为信息传播的重要媒介之一,越来越多的人开始通过短视频来获取信息,但是由于视频资源的日益增多,人工审核视频内容又过于耗费人力物力,所以需要一种新的方式来帮助人们高效的审核视频内容。
2、视频描述方法通过深度学习相关技术,对给定的视频片段进行多维度特征提取,并根据提取的特征生成对应的自然语言描述,视频描述具有大量的实际应用,它可以帮助用户高效检索视频并审核其视频内容,具有巨大的发展前景。
3、现有的视频描述方法大都是基于深度学习领域的编码器-解码器模型,在编码阶段设计精巧的结构来实现对不同模态的特征进行融合,在解码阶段大都采用的软注意力机制生成描述语句,但是他们的方法大都仅考虑利用上一时刻的状态来预测计算当前时刻的权重,忽略了先前所有时刻的权重分配情况对当前时刻的影响,这会让模型积累权重分配的误差,可能会过分关注冗余帧,最终导致模型融合视频特征的效果不佳。
技术实现思路
1、针对上述问题,本发明提出一种能够感知全局权重分配情况,并利用上一时刻的状态来分配当前时刻的权重的方法,缓解模型积累的权重分配误差;并且,由于数据短缺、数据分布不平衡问题会导致模型拟合出现全局性偏差,为了鼓励模型学习样本之间的关系,利用样本间关系学习模块来鼓励模型学习样本之间的关系。
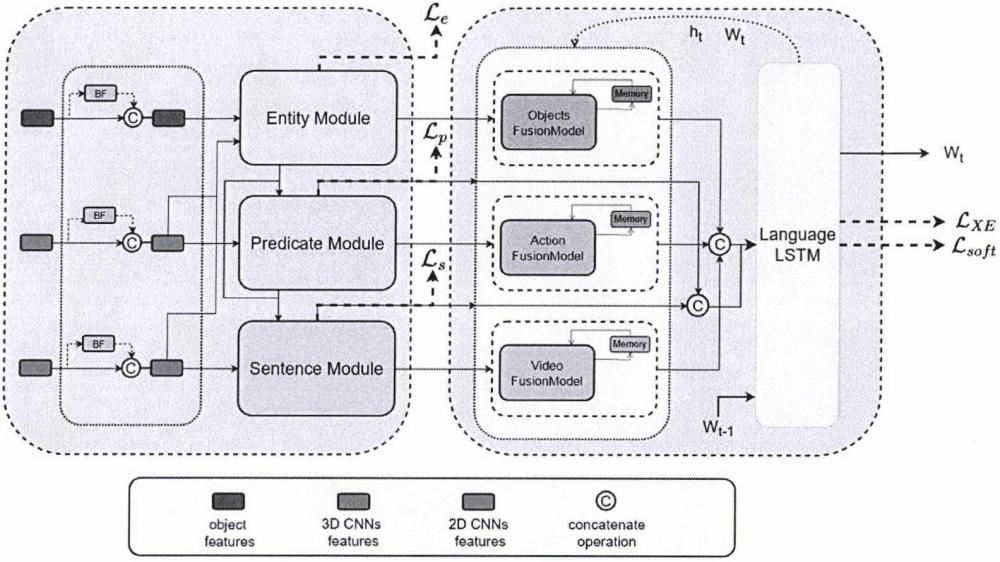
2、本发明基于深度学习领域常用的编码器-解码器结构模型实现。在模型开始训练之前,先将视频特征通过inception-resnet-v2模型提取视频静态特征,使用c3d模型提取视频动态特征,使用faster-rcnn模型提取视频对象特征,并且根据外观和边界框之间的关系对对象区域进行聚类,以获得最终的视频对象集合特征,并将这些多维度特征作为训练样本送入模型中以获得相对应的自然语言描述。
3、编码器使用实体模块,谓词模块,句子模块来对特征进行编码处理。首先,实体模块在给定的对象集合中,查询k个最主要的对象;谓词模块通过结合实体模块查询的k个主要对象的特征以及视频动态特征,来获取视频中的动作特征;句子模块将先前生成的主要对象特征、动作特征和静态特征结合,来生成视频的全局特征。在特征编码之前,利用样本间关系学习模块学习样本特征之间的关系,样本间关系学习模块由transformer模块组成,为了解决在训练过程和测试过程的不一致性,该模块采用双流结构,该结构在训练阶段创建一个视频特征拷贝并使用样本间关系学习模块进行训练,学习样本之间的关系,并将输出的特征与原特征拼接送入后续的编码模块,在测试阶段为了避免引入额外的推理负载,将样本间关系学习模块删除。
4、解码器由全局感知特征融合控制模块以及文本生成模块组成,其中全局感知特征融合控制模块用于根据先前隐藏状态和先前权重分配来控制当前特征融合,文本生成模块将先前隐藏状态以及经过处理的特征连接并通过lstm来逐步生成单词。由于字幕语料库的长尾词分布问题可能会导致数据不平衡的训练问题。为了缓解该问题,利用外部语言模型elm缓解长尾词分布问题。
技术特征:1.一种基于全局感知特征融合与样本关系学习的视频描述方法,其特征在于,所述方法包括以下步骤:
2.根据权利要求1所述的基于全局感知特征融合与样本关系学习的视频描述方法,其特征在于,所述的步骤1中利用inception-resnet-v2模型提取静态特征,利用c3d模型提取动态特征,利用faster-rcnn模型提取对象特征,特征大小均为2048。
3.根据权利要求1所述的基于全局感知特征融合与样本关系学习的视频描述方法,其特征在于,所述的步骤2中,利用sbert模型提取的语义标签大小为762。
4.根据权利要求1所述的基于全局感知特征融合与样本关系学习的视频描述方法,其特征在于,所述的步骤3中,创建一个视频特征拷贝并使用样本间关系学习模块进行训练,学习样本之间的关系,并将关系特征和视频特征拼接,公式如下:
5.根据权利要求1所述的基于全局感知特征融合与样本关系学习的视频描述方法,其特征在于,所述的步骤4中,编码器包括实体模块,谓词模块,句子模块,其中,实体模块在给定的对象集合中,查询k个最主要的对象;谓词模块通过结合实体模块查询的k个主要对象的特征以及视频动态特征,来获取视频中的动作特征;句子模块将先前生成的主要对象特征、动作特征和静态特征结合,来生成视频的全局特征;对象语义特征、动作语义特征,全局特征由全连接层组成的语言头将对象特征、动作特征,全局特征投影到语义空间来获得。
6.根据权利要求1所述的基于全局感知特征融合与样本关系学习的视频描述方法,其特征在于,所述的步骤6中,全局感知特征融合控制模块根据先前隐藏状态和先前权重分配来控制当前特征融合。
7.根据权利要求1所述的基于全局感知特征融合与样本关系学习的视频描述方法,其特征在于,所述的步骤7中,将先前隐藏状态以及经过处理的特征连接并通过lstm来逐步生成单词。
技术总结本发明提供一种基于全局感知特征融合与样本关系学习的视频描述方法,属于视频描述领域。所述视频描述方法包括利用Inception‑ResNet‑V2模型提取视频静态特征;利用C3D模型提取视频动态特征;利用Faster‑RCNN模型提取视频对象特征;利用SBERT模型提取中视频对应字幕的语义标签;使用提出的样本关系学习模块学习样本之间的关系特征,利用全局感知特征融合模块控制特征融合权重,缓解累积的权重分配偏差问题,提高生成字幕的确性。技术研发人员:毛龙,刘斌受保护的技术使用者:南京工业大学技术研发日:技术公布日:2024/9/12本文地址:https://www.jishuxx.com/zhuanli/20240914/294952.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。