用于认证对象的方法与流程
- 国知局
- 2024-10-09 16:13:40
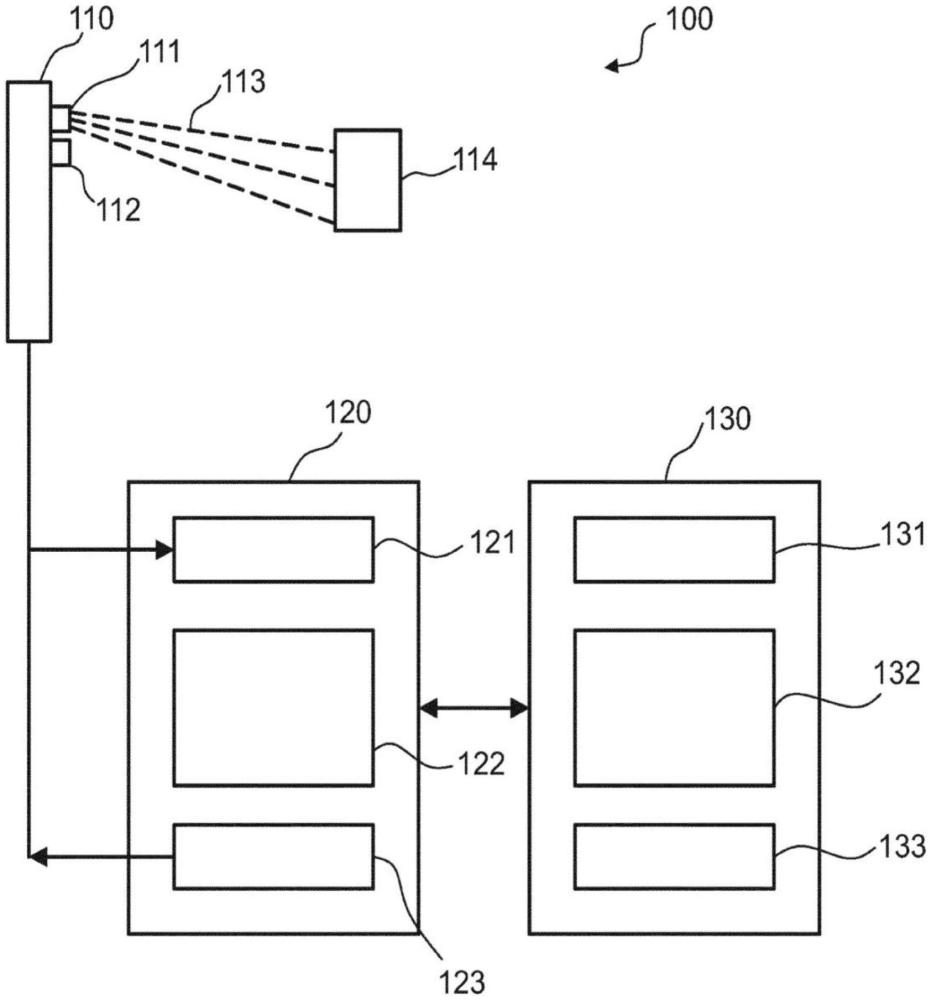
本发明涉及一种用于认证对象的方法、设备以及计算机可读数据介质。进一步,本发明涉及一种训练方法、训练设备以及训练计算机可读数据介质,用于训练适合于认证对象的基于机器学习的识别模型,使得识别模型可由用于认证对象的方法、设备以及计算机可读数据介质利用。进一步,本发明涉及通过用于认证对象的方法获得的对象的认证用于访问控制的用途。
背景技术:
1、通常,已知神经网络可以被训练以检测图像是否包含期望的对象(例如,真实面部或欺骗性面具),特别是用于解锁过程中的识别目的。然而,已经证明,为了训练这种神经网络,需要大量的图像,并且经常仍然获得较差的识别可靠性。此外,在这种方法中用于训练神经网络的输入图像数量巨大,很容易导致神经网络的过拟合,从而进一步降低准确度。
2、因此,如果能够用较少的训练数据来训练神经网络,从而避免过拟合,同时提高神经网络用于认证对象的识别准确度,这将是有利的。
技术实现思路
1、本发明的目的是提供一种用于准确地认证对象的方法、设备以及计算机可读数据介质,其允许利用较少的训练数据来对用于认证对象的基于机器学习的识别模型进行训练。此外,本发明的进一步目的是提供一种训练方法、训练设备以及计算机可读数据介质,其允许提供识别模型,该识别模型可在用于通过利用较少的训练数据和较少的计算资源来训练识别模型以认证对象的方法、设备以及计算机可读数据介质中使用。
2、在本发明的第一方面,呈现了一种用于认证对象的计算机实施的方法,其中,该方法包括:i)接收图案图像,该图案图像示出了用包括一个或多个图案特征的光图案照射时的对象,ii)基于指示该对象在该图案图像中的位置和范围的信息,从该图案图像中选择位于该对象上的图案特征,iii)通过基于这些所选图案特征裁剪该图案图像来生成若干个裁剪后的图案图像,其中,裁剪后的图案图像具有预定大小并且包含这些所选图案特征之一的至少一部分,iv)通过将这些裁剪后的图案图像提供给基于机器学习的识别模型来认证该对象,该识别模型已经被训练为使得其可以基于这些裁剪后的图案图像作为输入来认证对象,以及v)输出该对象的认证。
3、由于通过裁剪图案图像生成若干个裁剪后的图案图像,使得具有预定大小的每个裁剪后的图案图像包含一个所选图案特征的至少一部分,该所选图案特征被选择使得其位于对象上,并且由于裁剪后的图案图像被用作基于机器学习的识别模型的输入,因此并非完整的图案图像、特别是还包括潜在的大量背景被用于认证。特别地,裁剪后的图案图像已经集中在要认证的对象上,而不包括大量的背景。因此,可以避免识别模型的训练过程中训练识别模型以区分对象与可能非常多变的背景所必需的部分,从而减少必需的训练数据。此外,将该图案图像裁剪成更小的部分,即,将要认证的对象划分成若干个图像,每个图像仅示出该对象的一部分,其进一步的优点在于,在训练基于机器学习的识别模型期间,可以避免认证主要基于对象的完全不同区域中的特征的相关性。在该上下文中,已经发现,对该图案图像进行裁剪迫使识别模型只基于对象上彼此靠近的特征(即,可以在对象的同一区域中找到的特征)的相关性来进行认证,从而提高认证的准确度。此外,已经发现,图案图像的裁剪允许利用具有较少参数(例如,在神经网络的情况下具有较少神经元)的机器学习模型。其优点在于,可以降低机器学习模型过拟合的危险,从而提高机器学习模型输出的可靠性。因此,该方法允许利用机器学习识别模型提高对象认证的准确度和可靠性,该机器学习识别模型的训练成本可能较低、特别是训练数据较少。
4、该方法是指计算机实施的方法,因此可以由通用或专用计算装置执行,该计算装置适于例如通过执行相应的计算机程序来执行该方法。此外,该方法还可以由多于一台计算装置来执行,例如,通过计算机网络或任何其他类型的分布式计算,其中,在这种情况下该方法的步骤可以由一个或多个计算单元来执行。
5、该方法允许认证对象。认证对象特别是指识别特定对象,以确定该特定对象是否可以访问预定资源。通常,识别对象是指确定对象的身份。身份可以是指一般身份,例如,指示对象属于预定对象类的一部分的类身份,或者是指确定对象是否是指预定的唯一对象的特定身份。确定对象的一般身份的实例是指例如确定图像上的对象是否是人类(即,属于人类),或是否是椅子(即,属于椅子类)。特定识别的实例可以是指识别预定的个体(例如,智能手机的所有者)、识别特定个体的椅子(例如,属于特定所有者的特定椅子)等。优选地,该方法适于认证人类,以允许对访问受限的锁定资源进行访问。在优选的实施例中,利用人类的认证来允许或拒绝对计算装置(如智能手机、膝上型计算机、平板计算机等)或由计算装置提供的资源(如预定程序、数字支付选项等)的访问。
6、在第一步骤中,接收示出对象的图案图像。例如,当用光图案对对象进行照射时,可以从拍摄图像的相机单元接收图案图像。然而,图案图像也可以从已经存储图案图像的存储单元接收。此外,图案图像还可以由用户输入接收,例如,当用户指示应将存储在存储装置上的多个图像中的哪一个用作图案图像时。该图案图像是指用包括一个或多个图案特征的光图案照射对象时已经拍摄的图像。例如,拍摄图案图像可以由用户通过向相应的装置提供相应的输入来初始化,其中,在这种情况下,光图案生成单元可以适于生成光图案,并且相机适于在用光图案照射对象时拍摄图案图像。然而,生成光图案和拍摄图像也可以基于一个或多个预定事件自动进行,或者可以是连续进行,例如,用于产品质量控制。
7、通常,对象上的光图案可以由任何类型的光图案生成单元生成。优选地,该光图案是通过利用激光、特别是红外激光生成的。利用红外光的优点在于,当照射用户面部时,这种光对人类用户的刺激较小。特别地,优选的是,利用一个或多个垂直腔面发射激光器(vcsel)来生成包括多个激光光斑的光图案。然而,也可以利用其他光源来生成光图案,例如,也可以利用一种或多种颜色的led光源。优选地,照射对象的光图案是指包括规则布置的图案特征的规则光图案。然而,在其他实施例中,光图案也可以是指不规则图案或者甚至任意图案。通常,光图案的图案特征是指光图案中可以与其他图案特征区分开来(例如,由于图案特征之间未照明距离或者由于不同图案特征中光的不同布置)的部分。优选地,图案特征是指以预定图案布置的一个或多个光斑,其中,光图案优选地是重复预定图案。特别地,优选的是,光图案是指点云,其中,点是指光斑,其中,图案特征在这种情况下可以是指一个光斑。在这种情况下,光图案可以是指例如基本相似且包括圆形形状的光斑的六边形或三斜晶格。利用光斑的六边形或三斜图案的优点在于,光斑的布置为光斑提供了不同的距离关系,这防止了在训练基于机器学习的识别模型期间被过于规则的图案误导的危险。然而,图案特征也可以是指多于一个光斑,例如,是指包括六个光斑的一个六边形,其中,在这种情况下,例如,特征图案(即,六边形)可以重复以形成规则的光图案。
8、然后该方法进一步包括基于指示该对象在该图案图像中的位置和范围的信息,从该图案图像中选择位于该对象上的图案特征。可以以多种方式接收指示对象在图案图像中的位置和范围的信息。例如,图案图像可以被呈现给用户,并且用户可以可选地基于对象的可见光图像来指示对象在图案图像中的位置和范围。此外,来自图案图像的信息、特别是来自图案图像中的图案特征的信息本身可以用于确定对象的位置和范围。例如,在优选的实施例中,图案特征的选择可以包括首先从图案图像中得出指示对象的位置和范围的信息。在该实施例中,可以利用用于从图案图像中得出信息的已知方法。在优选的实施例中,用于确定从相机反射的图案特征的距离的已知方法可以用于接收关于对象的范围和位置的信息。例如,彼此之间在预定距离范围内的图案特征可以被视为属于同一对象,因此可以被选择。此外,例如,通过比较彼此相邻的图案特征的距离,可以确定对象的轮廓。如果相邻图案特征的距离高于预定阈值,则可以确定轮廓。此外,在附加或可替代实施例中,指示对象在图案图像中的位置和范围的信息也可以通过根据每个图案特征的反射特性得出材料来从图案图像中得出。在这种情况下,也可以利用用于从反射光的特性得出材料特性的已知方法,并且可以确定选择指示与对象相关联的材料的图案特征作为位于对象上的图案特征。例如,指示它们由人体皮肤反射的图案特征在这种情况下可以被确定为属于人的面部,因此可以被选择为位于对象上。
9、在进一步附加或可替代实施例中,优选的是,进一步接收泛光图像,并且这些图案特征的选择是根据基于该泛光图像确定指示该对象的位置和范围的该对象的轮廓、并且通过选择位于该轮廓内的这些图案特征来选择位于该对象上的这些图案特征来进行的,其中,该泛光图像示出了用泛光照射时的对象。在该实施例中,除了泛光图像之外,还可以利用示出被自然光或室内人造光照射的对象的自然光图像。可以根据用于可见光图像的任何已知特征提取方法来执行基于泛光图像指示对象位置和范围的对象轮廓的确定。特别地,该图像可以被呈现给用户,并且用户可以指示泛光图像中对象的轮廓。然而,也可以利用更复杂的自动算法,如机器学习算法或简单特征检测算法。通常,对于利用多于一个图像的所有实施例,例如,利用多于一个图案图像以例如用于特征图案的距离确定或利用泛光图像以用于轮廓检测,优选的是,相应图像是在同一时间拍摄的或者至少在拍摄图案图像的时间前后的预定时间范围内拍摄的,而且是由同一相机或与拍摄图案图像的相机相距预定距离的相机拍摄的。这允许直接从一个图像中(例如,泛光图像中)的特征位置得出该特征在图案图像中的位置。然而,也可以对相应的图像进行预处理。这可以包括确定图像中对象的位置和范围,以及对相应的对象进行居中、缩放、大小归一化和旋转,使得为所有图像提供归一化取向,这允许在一个图像中得出特征的位置并且将该得出的位置传送到另一个图像。例如,在泛光图像中,特征检测算法可以检测对象并且使该对象置于图像中心,并且将该图像缩放到归一化比例。在该图案图像中,这些特征图案的距离测量还可以用于确定对象的轮廓,并且还可以对该图案图像进行预处理,使得该对象居中并缩放到归一化比例。即使在原始图像中,例如,由于相机前用户的微小移动,位置发生了轻微偏移,也可以利用这两个图像将位置从一个图像传送到另一个图像。通常,为了使该方法准确地发挥作用,只需近似地确定对象的位置和范围,即无需准确地确定轮廓。因此,也可以利用只近似对象的位置和范围的方法,或者可以利用如上所述的准确度较低的方法,例如,利用计算资源较少的方法。
10、然后从图案图像中选择位于对象上的图案特征,例如,通过确定图案特征的位置是否位于对象的轮廓内。在此上下文中,选择图案特征还可以包括确定图案图像中每个图案特征的位置。例如,可以利用相应的特征检测算法。由于图案特征具有预定形状,并且是进一步与图像中未被图案特征照射的其他部分清楚地区分开来,因此这种特征识别方法可以基于简单的规则。例如,可以确定图案图像的像素包括超过预定阈值的光强度是图案特征的一部分。此外,还可以根据图案特征的几何形式来考虑相邻像素的光强度,以确定图案特征的位置。此外,还可以利用2d形状识别算法来识别图案特征的预定2d形状。然而,也可以利用更复杂的特征提取方法,或者用户可以通过相应的输入来执行位置确定。然后可以通过将图案特征的位置与对象的指示位置和范围进行比较并选择位于对象边界内的图案特征来选择对象上的图案特征。
11、然而,在一些实施例中,也可以省略确定图案特征的位置。例如,如果例如通过确定特征图案相对于彼此的距离来针对图案图像本身得出关于对象的范围和位置的信息,则选择也可以直接基于距离确定。特别地,在该实例中,彼此相邻并且彼此在预定距离范围内的图案特征可以被直接选择为对象上的图案特征。因此,在这种情况下,不必确定图案特征的位置。
12、在进一步的步骤中,基于所选图案特征,通过裁剪图案图像来生成若干个裁剪后的图案图像。通常,图像的裁剪是指移除裁剪后的图案图像之外的图案图像的所有区域。优选地,若干个裁剪后的图案图像是指至少两个裁剪后的图案图像、更优选地是指多于两个裁剪后的图案图像。对图案图像执行裁剪以生成若干个裁剪后的图案图像,使得裁剪后的图案图像(例如,每个裁剪后的图案图像)包括预定大小并且包含所选图案特征之一的至少一部分、优选地所选图案特征之一。例如,所选图案特征的一部分可以是指所选图案特征的一半或四分之一。特别地,完整的所选图案特征不必是裁剪后的图像的一部分,因为算法还可以被训练为基于包括所选图案特征的一部分的裁剪后的图像来认证对象。特别地,对于所选图案特征是指激光光斑的情况,所选图案特征将遵循最大强度位于所选图案特征的中间的高斯强度函数。在这种情况下,识别模型可以例如基于强度函数的特性进行认证,其中,如果在裁剪后的图像中仅强度函数的部分(即,仅所选图案特征的部分)是可见的,则也可以实现准确的认证,因为这些部分已经允许确定强度曲线的相应特性。在优选的实施例中,对图案图像进行裁剪,使得裁剪后的图像包括多于一个所选图案特征的部分。例如,通过利用所选图案特征作为用于对裁剪后的图像的边界进行裁剪的边界点来裁剪图案图像。然而,优选的是,对图案图像进行裁剪,使得裁剪后的图像包括至少一个完整的所选图案图像,以提高认证的准确度。预定大小例如可以以裁剪后的图像应覆盖的预定区域的形式确定,或者可以确定区域大小的任何其他特性,例如圆形区域情况下的半径等。优选地,裁剪后的图像是指以预定高度和宽度确定的矩形图像。更优选地,裁剪后的图像是指二次图像。其优点在于,图案特征周围的信息在所有方向上的权重都是相同的。然而,裁剪后的图像通常可以具有任意形状,因此也可以通过不同的大小特性来表征。例如,裁剪后的图像可以是圆形的,并以相应的半径来表征。优选地,每个裁剪后的图像包括相同的预定大小。然而,对于不同的裁剪后的图像,也可以利用不同的预定大小,例如,对于在对象的中心裁剪的图像,可以预定比在距对象的轮廓的预定距离内裁剪的图像更大的大小。优选地,裁剪后的图案图像以所选图案特征为中心。甚至更优选地,对于每个所选图案特征,生成裁剪后的图案图像,该裁剪后的图案图像至少包括优选地位于裁剪后的图像中心的相应所选图案特征。进一步,优选的是,裁剪后的图案图像包括多于一个所选图案特征,例如,除了中心图案特征之外,还包括全部或部分相邻的所选图案特征。
13、在进一步的步骤中,该方法包括通过向基于机器学习的识别模型提供裁剪后的图案图像来认证对象。基于机器学习的识别模型已经被训练为使得其可以基于裁剪后的图案图像作为输入来认证对象。通常,基于机器学习的识别模型利用根据与裁剪后的图案图像相同的规则生成的裁剪后的图案图像进行训练的,这些裁剪后的图案图像随后用于认证对象。基于机器学习的识别模型可以利用任何已知的机器学习算法。然而,神经网络尤其适合于在图像上的特征和对象识别技术的上下文中使用。因此,优选的是,基于机器学习的识别模型基于神经网络算法。更优选地,神经网络是指卷积神经网络。在这种情况下,利用裁剪后的图案图像作为基于机器学习的识别模型的输入尤其合适,因为图案图像的裁剪防止卷积神经网络算法过于依赖位于图像的完全不同区中的特征的相关性来做出认证决策。这大大提高了认证准确度,并且减少了假阳性认证。在优选的实施例中,该识别模型适于学习以基于反映相应材料的图案特征的特性来区分图案图像中的不同材料,并且基于材料差异来进行认证。例如,在申请wo 2020/187719 a1中可以找到这种识别模型的更多细节。
14、由于该识别模型的训练,然后经训练的识别模型可以在提供有裁剪后的图案图像作为输入时认证对象。特别地,识别模型的输出可以是指简单的验证或非验证,或者对象是指预定的特定对象(如个人)还是通常的对象类(如人类)。然而,输出还可以涉及确定被认证的对象属于预定数量的对象类中的哪一个或者属于预定数量的特定对象中的哪一个。例如,然后可以确定在装置的三个特定用户a、b、c中,当前用户被识别为用户a。
15、然后可以输出结果,即识别模型的输出。特别地,该方法包括输出对象的认证的步骤。例如,识别模型的结果(即,对象的认证)可以被提供给向用户提供视觉或音频输出的用户装置的输出单元,以通知用户该结果。此外,如果已经确定潜在用户的身份允许相应的访问,则可以进一步处理输出,例如,以解锁门或装置。此外,对象的认证结果的输出可以进一步用于控制装置,不仅提供对受限资源的访问,而且进一步例如基于对象的认证来控制自动装置或机器人的移动或位置。
16、在本发明的进一步的方面中,呈现了一种用于认证对象的设备,其中,该设备包括:i)输入接口,该输入接口用于接收图案图像,该图案图像示出了用包括一个或多个图案特征的光图案照射时的该对象,ii)处理器,该处理器被配置为:a)基于指示该对象在该图案图像中的位置和范围的信息,从该图案图像中选择位于该对象上的图案特征,b)通过基于这些所选图案特征裁剪该图案图像来生成若干个裁剪后的图案图像,其中,裁剪后的图案图像具有预定大小并且包含这些所选图案特征之一的至少一部分,以及c)通过将这些裁剪后的图案图像提供给基于机器学习的识别模型来认证该对象,该识别模型已经被训练为使得其可以基于这些裁剪后的图案图像作为输入来认证对象,以及iii)输出接口,该输出接口用于输出对象的认证。
17、在本发明的进一步的方面中,呈现了一种用于训练适合于认证对象的基于机器学习的识别模型的方法,其中,该方法包括:i)接收基于历史数据集的训练数据集,该历史数据集包括a)对象的裁剪后的图案图像和b)该对象的真实性,其中,这些裁剪后的图像是从图案图像中生成的,其中,该图案图像示出了用包括一个或多个图案特征的光图案照射时的该对象,并且其中,生成该裁剪后的图案图像包括a)基于指示该对象在该图案图像中的位置和范围的信息,从该图案图像中选择位于该对象上的图案特征,以及b)通过基于这些所选图案特征裁剪该图案图像来生成若干个裁剪后的图案图像,其中,裁剪后的图案图像具有预定大小并且包含这些所选图案特征之一的至少一部分,ii)通过基于该训练数据集调整该识别模型的参数化来训练可训练的基于机器学习的识别模型,使得经训练的识别模型适于在提供有该对象的裁剪后的图案图像作为输入时认证对象,以及iii)输出该经训练的识别模型。
18、在本发明的进一步的方面中,呈现了一种用于训练适合于认证对象的基于机器学习的识别模型的设备,其中,该设备包括:i)输入接口,该输入接口用于接收基于历史数据集的训练数据集,该历史数据集包括a)对象的裁剪后的图案图像和b)该对象的真实性,其中,这些裁剪后的图像是从图案图像中生成的,其中,该图案图像示出了用包括一个或多个图案特征的光图案照射时的该对象,并且其中,生成该裁剪后的图案图像包括a)基于指示该对象在该图案图像中的位置和范围的信息,从该图案图像中选择位于该对象上的图案特征,以及b)通过基于这些所选图案特征裁剪该图案图像来生成若干个裁剪后的图案图像,其中,裁剪后的图案图像具有预定大小并且包含这些所选图案特征之一的至少一部分,ii)处理器,该处理器被配置为通过基于该训练数据集调整该识别模型的参数化来训练可训练的基于机器学习的识别模型,使得经训练的识别模型适于在提供有该对象的裁剪后的图案图像作为输入时认证对象,以及iii)输出接口,该输出接口用于输出该经训练的识别模型。
19、在本发明的进一步的方面中,呈现了对象的真实性的用途,其中,通过如上所述的方法获得的对象的真实性的用途包括访问控制。
20、在本发明的进一步的方面中,呈现了一种非暂态计算机可读数据介质,其中,该数据介质存储有计算机程序,该计算机程序包括使计算机执行如上所述的方法的步骤的指令。
21、在本发明的进一步的方面中,呈现了一种非暂态计算机可读数据介质,其中该数据介质存储有计算机程序,该计算机程序包括使计算机执行如上所述的训练方法的步骤的指令。
22、在本发明的进一步的方面中,呈现了一种用于确定对象的真实性的方法,其中,该方法包括:a)接收该对象的图案图像和泛光图像,其中,该图案图像示出用光图案照射时的该对象,并且其中,该泛光图像示出用泛光照射时的该对象,b)从泛光图像中确定对象的轮廓,c)基于从泛光图像中获得的轮廓,从图案图像中选择位于对象上的图案特征,c)通过裁剪图案图像来生成若干个裁剪后的图像,其中,裁剪后的图像具有预定的宽度和高度,并且在该裁剪后的图像的中心包含所选图案特征之一,d)通过将裁剪后的图像提供给神经网络来确定对象的真实性,该神经网络已经用包含对象的裁剪后的图像的历史数据集进行了训练,以及e)输出对象的真实性。
23、在本发明的进一步的方面中,呈现了一种用于确定对象的真实性的系统,其中,该系统包括:a)输入端,该输入端用于接收该对象的图案图像和泛光图像,其中,该图案图像示出用光图案照射时的该对象,并且其中,该泛光图像示出用泛光照射时的该对象,b)处理器,该处理器被配置为:i)从该泛光图像中确定对象的轮廓,ii)基于从泛光图像中获得的该轮廓,从图案图像中选择位于对象上的图案特征,iii)通过裁剪图案图像来生成若干个裁剪后的图像,其中,裁剪后的图像具有预定的宽度和高度,并且在该裁剪后的图像的中心包含所选图案特征之一,iv)通过将裁剪后的图像提供给神经网络来确定对象的真实性,该神经网络已经用包含对象的裁剪后的图像的历史数据集进行了训练,以及c)输出端,该输出端用于输出对象的真实性。
24、在进一步的方面中,呈现了一种用于训练适合于确定对象的真实性的神经网络的方法,其中,该方法包括:a)接收基于历史数据集的训练数据集,这些历史数据集包括对象的裁剪后的图像和该对象的真实性,其中,这些裁剪后的图像是从该对象的图案图像和泛光图像中生成的,其中,该图案图像示出用光图案照射时的该对象,并且其中,该泛光图像示出用泛光照射时的该对象,并且其中,生成该裁剪后的图像包括:b)从泛光图像中确定对象的轮廓,基于从泛光图像中获得的轮廓,从该图案图像中选择位于对象上的图案特征,通过裁剪图案图像来生成若干个裁剪后的图像,其中,裁剪后的图像具有预定的宽度和高度,并且在该裁剪后的图像的中心包含所选图案特征之一,c)通过根据训练数据集调整参数化来训练神经网络,以及d)输出经训练的神经网络。
25、应当理解,如上所述的用于认证对象的方法、如上所述的用于认证对象的设备以及如上所述的用于认证对象的计算机可读数据介质具有相似和/或相同的优选实施例,特别是如从属权利要求中所定义的。此外,如上所述的训练方法、如上所述的训练设备和如上所述的训练计算机可读数据介质也具有相似和/或优选的实施例,特别是如从属权利要求中所定义的。
26、应当理解,本发明的优选实施例也可以是从属权利要求或上述实施例与相应独立权利要求的任意组合。
27、本发明的这些和其他方面将参考下文描述的实施例变得显而易见并且得以阐明。
本文地址:https://www.jishuxx.com/zhuanli/20240929/312271.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
上一篇
上下文提醒的制作方法
下一篇
返回列表