一种开放式词汇的交通道路零样本语义分割方法
- 国知局
- 2024-10-09 14:46:06
本发明属于计算机视觉,具体涉及一种开放式词汇的交通道路零样本语义分割方法。
背景技术:
1、随着城市化进程的不断推进,自动驾驶技术和智能交通系统的发展极大地提升了人们的出行便利性和安全性,在这些系统中,精准的场景理解和实时决策对于确保交通安全和提高行驶效率至关重要。在交通场景中,未知类对语义分割任务会产生一定的影响。未知类指的是在训练阶段未见过的类别,也就是模型没有接触到的新的交通元素或物体。这些未知类可能是由于交通场景的复杂性、多样性或变化性而引入的。交通场景中的未知类对语义分割任务会产生一定的影响,传统模型可能无法正确地将其分配到相应的类别,导致分割结果的不准确。由于未知类在训练阶段没有标注数据,因此无法直接用于模型的训练,未知类的存在增加了数据标注的难度和工作量。零样本语义分割可以在没有见过的类别的情况下进行推理和分割,这对于减少标注工作量、提高分割模型的泛化能力具有重要意义。目前零样本语义分割方法主要分为两类:第一种是xian等人在文献“y.xian,t.lorenz,b.schiele and z.akata.feature generating networks for zero-shotlearning.2018ieee/cvf conference on computer vision and pattern recognition,salt lake city,ut,usa,2018,pp.5542-5551”中提出了一种基于生成对抗网络的方法。该方法通过学习从语义描述(如类别属性或文本描述)到特征空间的映射,生成未见类别的视觉特征,主要包含特征生成网络和分类器训练两部分。该方法方法的成功在很大程度上依赖于输入的类别描述的质量,如果类别描述不够准确或不够详细,生成的特征可能不足以准确反映类别的真实视觉表现。第二种是li等人在文献“li y,wang d.zero-shotlearning with generative latent prototype model[j].arxiv preprint arxiv:1705.09474,2017.”中提出了一种结合生成模型和自训练策略的方法来解决零样本语义分割问题,通过生成模型从语义描述中生成潜在类别原型,并利用自训练机制来迭代优化分割模型的性能,初始模型使用生成的潜在原型进行训练,之后模型在真实数据集上进行自我迭代训练,逐步校正和优化对未见类别的识别和分割能力。此方法高度依赖生成模型的性能。如果生成的潜在原型与真实类别的特征差距较大,那么最终的分割效果可能会大打折扣,并且需要大量的计算资源和时间来训练。
技术实现思路
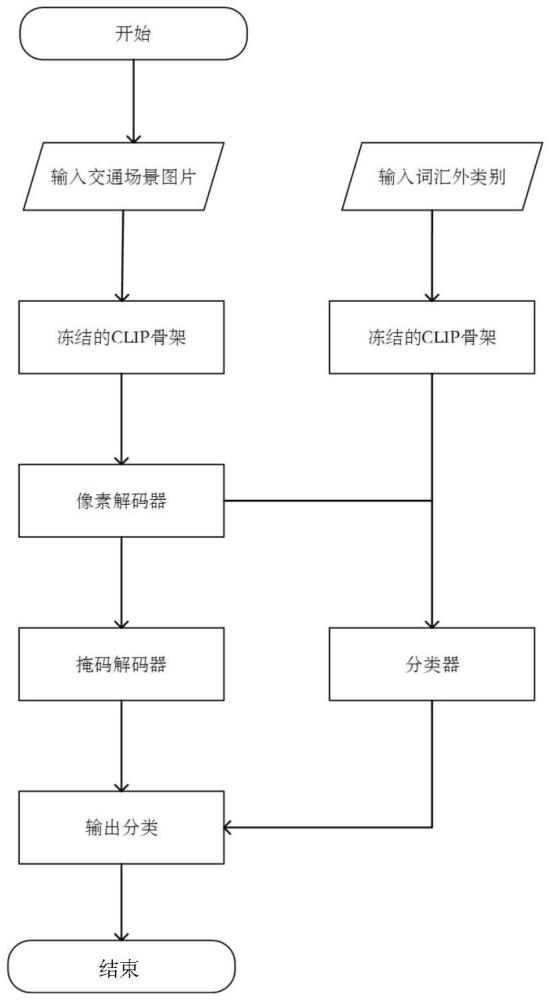
1、为了克服现有技术的不足,本发明提供了一种开放式词汇的交通道路零样本语义分割方法,首先使用一个冻结的clip骨干网络生成类别无关的掩码,然后将低分辨率图像和预测的掩码输入到该骨干网络中进行开放词汇识别。这种方式将掩码生成和识别过程统一在一个框架中,提高了效率并取得了优秀的性能,有效地提高了交通场景下的语义分割的准确性。
2、本发明解决其技术问题所采用的技术方案如下:
3、步骤1:准备训练和测试检测系统的数据集;
4、步骤2:将训练集数据输入神经网络中,学习图像与标签对应的关系;所述神经网络包括一个冻结的clip骨干网络、一个类别无关的掩码生成器,一个词汇内分类器和一个词汇外分类器;使用预训练的卷积网络convnext作为clip骨干网络的图像编码器;
5、步骤3:利用clip骨干网络提取的图像特征,结合物体查询和像素解码器生成类别无关的候选区域掩码;
6、步骤4:利用类别名称的文本编码和预测掩码的像素特征进行对比学习,从而预测每个掩码对应的类别,并对预测类别进行交叉熵损失;
7、模型训练过程中,仅使用词汇内分类器的损失进行反向传播,以更新可训练的参数,包括掩码生成器中的参数和词汇内分类器的参数;
8、步骤5:在推理阶段,使用训练好的模型进行推理,预测图像中的物体类别和掩码;除了使用词汇内分类器外,还利用词汇外分类器进行零样本类别预测,并结合词汇内分类器的结果进行集成,从而获得最终预测结果。
9、优选地,所述步骤1具体为:
10、采用公开数据集cityscapes,图像分辨率为1024*2048;采用cityscapes数据集的前15个类别作为可见类进行训练,在推理过程中,不仅包含训练时类别,也加入训练阶段不可见的4个类别,以此来验证模型在交通场景的零样本学习能力。
11、优选地,所述步骤2具体为:
12、所述卷积神经网络采用yu等人在文献“yu q,he j,deng x,et al.convolutionsdie hard:open-vocabulary segmentation with single frozen convolutional clip[j].advances in neural information processing systems,2024,36.”中使用的神经网络,神经网络名字简称fc-clip;网络包含一个冻结的clip骨干网络,一个类别无关的掩码生成器,一个词汇内分类器和一个词汇外分类器,其中类别无关的掩码生成器是利用mask2former中的设计,通过像素解码器和掩码解码器生成类别无关的分割掩码;像素解码器用于增强clip骨干网络提取的特征,掩码解码器用于生成最终的分割掩码。
13、优选地,所述步骤4具体为:
14、利用类别名称的文本编码和预测掩码的像素特征进行对比学习,从而预测每个掩码对应的类别,并对预测类别进行交叉熵损失;模型训练过程中,仅使用词汇内分类器的损失进行反向传播,以更新可训练的参数,包括掩码生成器中的参数和词汇内分类器的参数;
15、对于fc-clip,损失函数包括分割损失和分类损失。其中分割损失为:
16、
17、l=α·lfacal+β·ldice
18、其中,h表示图像的高度,w表示图像的宽度,模型预测每个类别的概率分布,yi表示真实的目标标签,表示模型的预测标签,γ表示模型对于容易被错误分类的样本的关注程度,α和β分别表示focal损失和dice损失的调节因子,用于平衡易分样本和难分样本的重要性;
19、衡量预测类别与真实类别之间的差异的分类损失为:
20、
21、其中,c表示类别的数量,yi表示第i类的真实标签,取值为0或1,pi表示模型预测第i类的概率。
22、优选地,所述步骤5具体为:
23、使用训练好的模型进行推理,预测图像中的物体类别和掩码;除了使用词汇内分类器外,还利用词汇外分类器进行零样本类别预测,并结合词汇内分类器的结果进行集成,从而获得最终预测结果;采用平均精度macc、平均交并比miou和平均像素准确率pacc作为判定标准来评估模型性能。
24、本发明的有益效果如下:
25、1.采用单阶段框架,通过共享预训练的卷积clip骨架网络,避免了重复提取图像特征,减少了计算成本,同时提升了性能。
26、2.卷积网络具有良好的尺度泛化能力,具有更好的尺度泛化能力,适用于高分辨率的分割任务。
27、3.系统结构更合理。利用词汇内分类器对训练集中的类别进行预测,同时使用词汇外分类器对测试集中的新类别进行预测。有效地结合两个分类器的预测结果,提高了分割的准确率。
本文地址:https://www.jishuxx.com/zhuanli/20241009/306430.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。