语音转换方法、装置、计算机设备和存储介质与流程
- 国知局
- 2024-10-15 09:19:03
本技术涉及语音转换,特别是涉及一种语音转换方法、装置、计算机设备和存储介质。
背景技术:
1、语音转换(voice conversion)是在说话内容不变基础上,将原始语音说话人音色迁移到目标说话人音色,在电影配音、角色模仿以及复刻人物音色等方面都有重要的应用。在车载领域也有着丰富的应用场景,如导航变声,ip定制,个性化定制用户音色等,通过单样本语音转换复制音色,不仅可以大大降低对训练数据的要求,也可以显著节省计算资源。
2、当前基于深度学习实现到特定目标说话人的语音转换已经取得很大的进步,例如基于cycle gan、vae以及asr的语音转换方法都可以很好的实现到训练集内说话人的语音转换。然而,如果想要增加一个目标说话人音色,或者进行用户音色的自定义复刻,通常需要大量的说话人数据以重新训练一个以该说话人音色为目标音色语音转换模型,或者通过少量数据对现有模型进行自适应训练。实际应用中,数据库录制的周期和成本都比较高,而对于普通用户而言,也很难获得用户大量的语音数据。
3、基于文本辅助的的注意力模型虽然能够与tts模型共享注意力(attention),实现一对多(one-to-many)转换,但是也有训练周期长,计算量大,无法实现超长文本合成转换等缺点,流式文本转语音(tts)模型虽然能并行合成语音但是也有参数量大的缺点。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种语音转换方法、装置、计算机设备和存储介质,能够解决流式文本转为某种目标说话人语音的参数量大、周期和成本都比较高的技术问题。
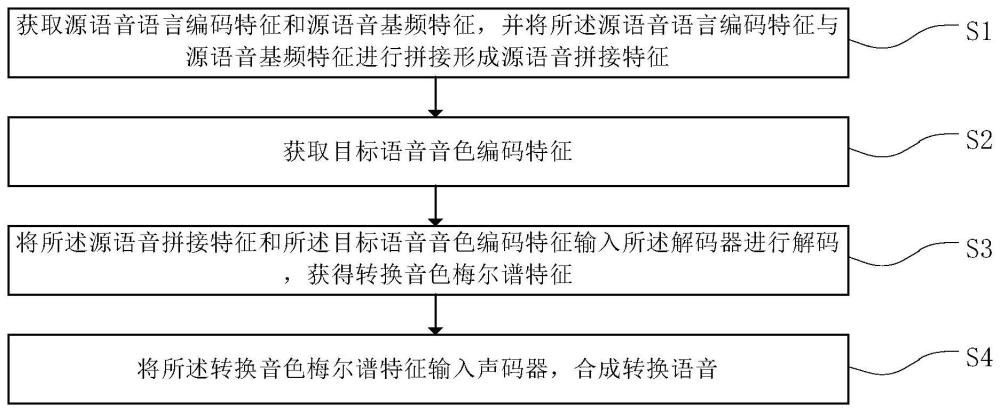
2、一方面,提供一种语音转换方法,所述方法包括:
3、获取源语音语言编码特征和源语音基频特征,并将所述源语音语言编码特征与源语音基频特征进行拼接形成源语音拼接特征;
4、获取目标语音音色编码特征;
5、将所述源语音拼接特征和所述目标语音音色编码特征输入所述解码器进行解码,获得转换音色梅尔谱特征;
6、将所述转换音色梅尔谱特征输入声码器,合成转换语音。
7、在其中一个实施例中,所述将所述源语音拼接特征和所述目标语音音色编码特征输入所述解码器进行解码,获得转换音色梅尔谱特征步骤,包括:
8、将所述源语音拼接特征输入至一维卷积层内进行卷积处理后输入至生成模块;
9、所述目标语音音色编码特征进行条件批归一化处理后输入至生成模块;
10、将卷积处理后的源语音拼接特征与条件批归一化处理后的目标语音音色编码特征经所述生成模块内的分段线性函数及上采样层、一维卷积层和膨胀卷积层处理后的输出结果输入至一维卷积层内进行卷积处理后输出转换音色梅尔频谱特征。
11、在其中一个实施例中,所述将所述源语音拼接特征和所述目标语音音色编码特征输入所述解码器进行解码,获得转换音色梅尔谱特征步骤,还包括:
12、将噪声向量经线性层处理后输入至批归一化层;
13、将卷积处理后的源语音拼接特征与条件批归一化处理后的目标语音音色编码特征输入至所述批归一化层,与噪声向量进行拼接累加;
14、将与噪声向量进行拼接累加后的拼接特征经所述生成模块内的分段线性函数及上采样层、一维卷积层和膨胀卷积层处理后的输出结果输入至一维卷积层内进行卷积处理后输出转换音色梅尔频谱特征。
15、在其中一个实施例中,所述将卷积处理后的源语音拼接特征与条件批归一化处理后的目标语音音色编码特征输入至所述批归一化层,与噪声向量进行拼接累加步骤,包括:
16、将卷积处理后的源语音拼接特征与条件批归一化处理后的目标语音音色编码特征作为第一语音输入特征;
17、在所述生成模块内设置多个批归一化层以及多个分段线性函数及上采样层,其中一个归一化层的输出端连接至所述分段线性函数及上采样层的输入端,所述分段线性函数及上采样层的输出端连接至一维卷积层或膨胀维卷积层的输入端,所述一维卷积层或所述膨胀维卷积层的输出端连接至另一个归一化层的输入端;
18、将所述第一语音输入特征输入至所述批归一化层与噪声向量进行拼接累加,经所述分段线性函数及上采样层、一维卷积层处理后输出第一拼接特征;
19、将所述第一语音输入特征经分段线性函数及上采样层、一维卷积层处理后输出第一校正拼接特征;
20、采用所述第一校正拼接特征对所述第一拼接特征进行校正,形成第二语音输入特征;
21、将所述第二语音输入特征输入至所述批归一化层与噪声向量进行拼接累加,经所述分段线性函数及上采样层、膨胀卷积层处理后输出第二拼接特征;
22、将所述第二语音输入特征经分段线性函数及上采样层、膨胀卷积层处理后输出第二校正拼接特征;
23、采用所述第二校正拼接特征对所述第二拼接特征进行校正,形成语音输出特征。
24、在其中一个实施例中,所述获取源语音语言编码特征和源语音基频特征,并将所述源语音语言编码特征与源语音基频特征进行拼接形成源语音拼接特征步骤包括:
25、将文本序列转换为音素序列;
26、将所述音素序列输入编码器预训练网络,与位置编码拼接后输入至编码器多头注意力层,依次经残差与归一化层、前向反馈层处理、残差与归一化层及线性层处理后输出文本序列特征;
27、将源语音梅尔谱输入解码器预训练网络,与位置编码特征拼接后形成拼接特征输入掩盖多头注意力层,经残差与归一化处理后形成解码频谱特征并将其输入至解码器多头注意力层;
28、将所述文本序列特征与目标语音音色编码特征拼接后形成二维特征矩阵序列并输入至解码器多头注意力层;
29、所述解码器多头注意力层对所述二维特征矩阵序列和所述解码频谱特征进行对齐运算后,经过残差与归一化处理后输出待合成文本的语音;
30、将所述文本序列特征与所述待合成文本的语音做矩阵乘,输出源语音拼接特征。
31、在其中一个实施例中,所述将文本序列输入源语音拼接特征模块并转为音素序列步骤,包括:
32、向源语音拼接特征模块输入文本序列;
33、将所述文本序列经过文本正则形成正则表达式;
34、将所述正则表达式经过字音转换形成汉语;
35、将所述汉语经过多音字分类和韵律预测转为音素序列。
36、在其中一个实施例中,在将所述音素序列输入编码器预处理网络与位置编码拼接步骤之前,以及在将源语音梅尔谱输入解码器预处理网络与位置编码特征拼接步骤之前,还包括:
37、将所述音素序列按时间序列对每帧进行位置编码,所述位置编码的公式为
38、
39、其中,pe为位置编码,pos为位置序号,i为时间序列的维度序号,d model为模型维度。
40、另一方面,提供了一种语音转换装置,所述装置包括:
41、编码器预训练网络,用于获取源语音语言编码特征;
42、解码器预训练网络,用于获取源语音基频特征,并将所述源语音语言编码特征与源语音基频特征进行拼接形成源语音拼接特征;
43、目标语音编码器,用于获取目标语音音色编码特征;
44、解码器,用于将所述源语音拼接特征和所述目标语音音色编码特征进行解码,获得转换音色梅尔谱特征;
45、声码器,用于将所述转换音色梅尔谱特征合成转换语音。
46、再一方面,提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
47、获取源语音语言编码特征和源语音基频特征,并将所述源语音语言编码特征与源语音基频特征进行拼接形成源语音拼接特征;
48、获取目标语音音色编码特征;
49、将所述源语音拼接特征和所述目标语音音色编码特征输入所述解码器进行解码,获得转换音色梅尔谱特征;
50、将所述转换音色梅尔谱特征输入声码器,合成转换语音。
51、又一方面,提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现以下步骤:
52、获取源语音语言编码特征和源语音基频特征,并将所述源语音语言编码特征与源语音基频特征进行拼接形成源语音拼接特征;
53、获取目标语音音色编码特征;
54、将所述源语音拼接特征和所述目标语音音色编码特征输入所述解码器进行解码,获得转换音色梅尔谱特征;
55、将所述转换音色梅尔谱特征输入声码器,合成转换语音。
56、上述语音转换方法、装置、计算机设备和存储介质,通过将所述非说话人相关语言特征与所述源说话人基频特征拼接进入解码器,将所述目标说话人编码特征输入所述解码器;所述解码器输出转换后具有目标说话人基频特征的梅尔谱;将转换后的梅尔谱输入声码器,合成转换语音。亦即采用借助转换器(transformer)端到端非自回归模型与文本辅助,引入多头注意力进行文本与音频的非说话人相关语言特征对齐,通过源说话人相关特征与基频特征通过解码器嵌入目标说话人语言特征,实现快速高效端到端非自回归语音转换。因此本技术能够减少文本转为某种目标说话人语音的参数量、缩短转换周期,提升了合成转换语音的效率,降低了合成转换语音的成本。
本文地址:https://www.jishuxx.com/zhuanli/20241015/313706.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表