一种基于上下文适应器和偏置损失的语音识别方法及系统与流程
- 国知局
- 2024-10-09 14:41:28
本发明涉及自然语言处理,尤其是一种基于上下文适应器和偏置损失的语音识别方法及系统。
背景技术:
1、自动语音识别旨在利用机器学习技术将口语输入转换为可理解的文本形式。它是人工智能和自然语言处理领域的一个重要分支,具有广泛的应用,包括语音搜索、语音助手、电影字幕生成等。
2、然而,在真实世界的应用场景中,语音识别模型需要应对很多不常见的词语。例如专有名词和首字母缩略词。这些词语的较少出现导致语音识别模型缺乏先验知识,使语音助手和智能客户服务等实际应用可能会因信息不足而无法正常运行。为语音识别模型提供有关稀有词汇可能出现的先验知识,这一过程称为上下文偏置。例如,当使用语音助手拨打电话时,它可以使用联系人列表中的姓名,或者当请求播放音乐时,可以将歌曲标题或艺术家姓名添加到列表中作为目标偏置短语。但是现有的模型很难选择正确的偏置短语,为上下文偏置方法的实际应用带来困难。
技术实现思路
1、本发明所要解决的技术问题是克服现有方法无法正确选择偏置短语的困难,提供一种基于上下文适应器和偏置损失的语音识别方法。
2、为此,本发明采用如下的技术方案:一种基于上下文适应器和偏置损失的语音识别方法,其包括:
3、利用大规模语音数据进行预训练,基于transducer结构构建一个基础语音识别模型;
4、将偏置短语输入上下文适应器编码为偏置向量;
5、将所述的偏置向量与基础语音识别模型的编码输出相加,输入联合网络以完成最终的预测,得到最终的预测文本;
6、对含有偏置短语的数据进行偏置学习,对最终的预测文本进行transducer学习,利用偏置学习损失和transducer学习损失对上下文适应器进行微调。
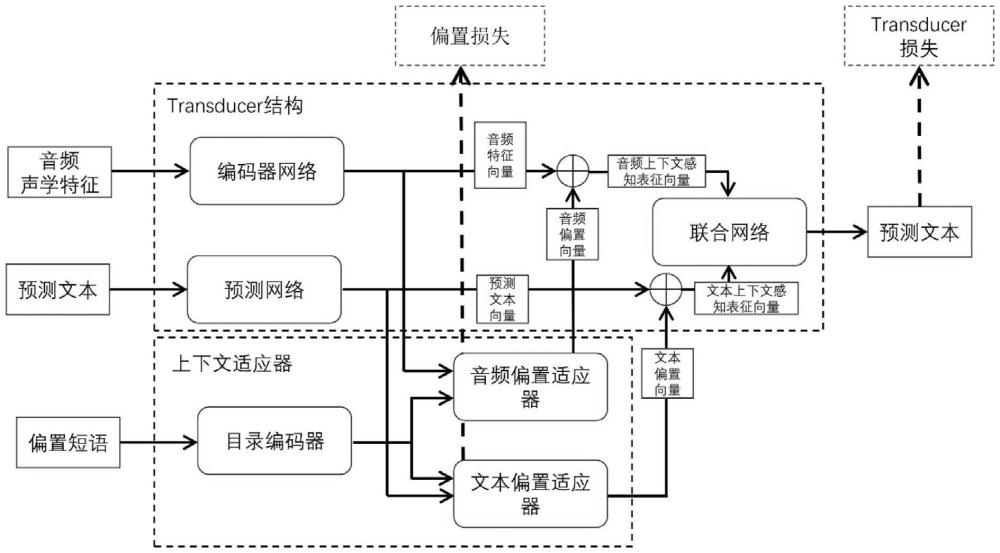
7、本发明首先使用大规模语音数据预训练,基于transducer结构构建一个基础语音识别模型,即预训练模型,然后利用上下文适应器将偏置短语编码为偏置向量,并与预训练模型的编码输出相加完成适应上下文偏置的语言识别,预训练模型通过transducer损失与偏置损失更新参数。
8、进一步地,所述的transducer结构包括编码器网络、预测网络和联合网络,所述基础语音识别模型的构建步骤如下:
9、使用编码器网络将语音数据中的声学特征向量xt编码为音频特征向量
10、
11、使用预测网络以自回归方式基于先前的预测文本yu编码为预测文本向量
12、
13、所述的联合网络,用于合并上述两个网络的编码输出,计算文本预测概率,输出预测文本。
14、进一步地,所述的上下文适应器包括三个部分,分别为目录编码器、音频偏置适应器和文本偏置适应器,将偏置短语输入上下文适应器编码为偏置向量,具体内容为:
15、将偏置短语qs输入基于双向lstm模型的目录编码器,取双向lstm模型最后的隐藏状态,压缩为偏置短语的一维嵌入向量ps:
16、ps=bilstm(qs);
17、将一维嵌入向量ps输入音频偏置适应器,使用多头注意力机制将偏置短语嵌入向量p与所述的音频特征向量对齐,得到音频注意力分数
18、
19、其中,wq、wk分别为多头注意力机制中的查询向量和键向量的计算参数,d是隐藏维度;偏置短语嵌入向量p为一维嵌入向量ps的集合;
20、使用多头注意力机制将偏置短语嵌入向量p与所述的预测文本向量对齐,得到文本注意力分数
21、
22、利用音频注意力分数和值向量得到音频偏置向量
23、
24、其中,wv为多头注意力机制中的值向量的计算参数;
25、利用文本注意力分数和值向量得到文本偏置向量
26、
27、进一步地,所述的偏置向量与基础语音识别模型的编码输出相加,输入联合网络以完成最终的预测,得到最终的预测文本,具体内容为:
28、利用所述的音频偏置向量和所述的音频特征向量计算音频上下文感知表征向量
29、
30、其中,代表元素相加;
31、利用所述的文本偏置向量和所述的预测文本向量计算文本上下文感知表征向量
32、
33、将音频上下文感知表征向量和文本上下文感知表征向量输入联合网络,使用联合网络合并这两个向量进行文本预测概率p(yu+1∣xt,y1:u)的计算,最后输出最终的预测文本yu+1:
34、
35、进一步地,所述偏置学习损失的计算过程如下:记录偏置短语的索引c;计算索引c和两个注意力分数的偏置损失:
36、所述transducer损失的计算过程如下:对利用音频上下文感知表征向量和文本上下文感知表征向量进行预测得到的文本预测概率计算transducer损失
37、总损失计算为:
38、
39、其中,α为transducer损失和偏置损失之间的权重。
40、本发明采用的另一种技术方案为:一种基于上下文适应器和偏置损失的语音识别系统,其包括:
41、基础语音识别模型构建单元:利用大规模语音数据进行预训练,基于transducer结构构建一个基础语音识别模型;
42、偏置向量生成单元:将偏置短语输入上下文适应器编码为偏置向量;
43、预测文本生成单元:将所述的偏置向量与基础语音识别模型的编码输出相加,输入联合网络以完成最终的预测,得到最终的预测文本;
44、上下文适应器微调单元:对含有偏置短语的数据进行偏置学习,对最终的预测文本进行transducer学习,利用偏置学习损失和transducer学习损失对上下文适应器进行微调。
45、本发明具有的有益效果为:本发明引入新的针对偏置短语的学习目标,利用上下文适应器与偏置损失函数,提高了语音识别模型对于不常见短语的识别准确性,克服了现有方法无法选择正确的偏置短语的问题。
技术特征:1.一种基于上下文适应器和偏置损失的语音识别方法,其特征在于,包括:
2.根据权利要求1所述的基于上下文适应器和偏置损失的语音识别方法,其特征在于,所述的transducer结构包括编码器网络、预测网络和联合网络,所述基础语音识别模型的构建步骤如下:
3.根据权利要求2所述的基于上下文适应器和偏置损失的语音识别方法,其特征在于,所述的上下文适应器包括三个部分,分别为目录编码器、音频偏置适应器和文本偏置适应器,将偏置短语输入上下文适应器编码为偏置向量,具体内容为:
4.根据权利要求3所述的基于上下文适应器和偏置损失的语音识别方法,其特征在于,所述的偏置向量与基础语音识别模型的编码输出相加,输入联合网络以完成最终的预测,得到最终的预测文本,具体内容为:
5.根据权利要求4所述的基于上下文适应器和偏置损失的语音识别方法,其特征在于,所述偏置学习损失的计算过程如下:记录偏置短语的索引c;计算索引c和两个注意力分数的偏置损失:
6.一种基于上下文适应器和偏置损失的语音识别系统,其特征在于,包括:
7.根据权利要求6所述的基于上下文适应器和偏置损失的语音识别系统,其特征在于,所述的transducer结构包括编码器网络、预测网络和联合网络,所述基础语音识别模型的构建步骤如下:
8.根据权利要求7所述的基于上下文适应器和偏置损失的语音识别系统,其特征在于,所述的上下文适应器包括三个部分,分别为目录编码器、音频偏置适应器和文本偏置适应器,将偏置短语输入上下文适应器编码为偏置向量,具体内容为:
9.根据权利要求8所述的基于上下文适应器和偏置损失的语音识别系统,其特征在于,所述的偏置向量与基础语音识别模型的编码输出相加,输入联合网络以完成最终的预测,得到最终的预测文本,具体内容为:
10.根据权利要求9所述的基于上下文适应器和偏置损失的语音识别系统,其特征在于,所述偏置学习损失的计算过程如下:
技术总结本发明公开了一种基于上下文适应器和偏置损失的语音识别方法及系统。针对现有方法面对偏置词表较大时无法正确选择偏置词的问题,本发明采用的技术方案为:利用大规模语音数据进行预训练,基于Transducer结构构建一个基础语音识别模型;将偏置短语输入上下文适应器编码为偏置向量;将偏置向量与基础语音识别模型的编码输出相加,输入联合网络以完成最终的预测,得到最终的预测文本;对含有偏置短语的数据进行偏置学习,对最终的预测文本进行Transducer学习,利用偏置学习损失和Transducer学习损失对上下文适应器进行微调。本发明引入上下文适应器与偏置损失函数,提高了语音识别模型对于不常见短语的识别准确性。技术研发人员:沈晓兵,周齐辉,吕力行,王小荣,王国清,徐拓,王芸,郭可均受保护的技术使用者:浙江浙能电力股份有限公司萧山发电厂技术研发日:技术公布日:2024/9/29本文地址:https://www.jishuxx.com/zhuanli/20241009/306122.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表